【coursera笔记】Machine Learning(Week6)
发现自己不写总结真是件很恶劣的事情,好多学的东西没有自己总结都忘记了。所以决定从今天开始,学东西的时候一定跟上总结。
我写的东西大多数是自己通俗的总结,不太喜欢写严格的定义或者证明,写了也记不住,欢迎指正。
1. High Bias vs. High Variance
High Bias:通常是因为模型过于简单,使得不能成功拟合数据。比如说一些有二次曲线特性的数据,如果用一次直线去拟合就会出现这个问题,所以它对应了Underfitting问题。另外,从泛化角度来说,这样的模型泛化程度更高。
High Variance:通常是因为模拟过于复杂,使得模型泛化到一般数据时效果很差,但是在训练数据上效果通常很好的问题,它对应了Overffiting的问题。从泛化角度来说,这样的模型泛化程度很低。
2. Cross Validation Set, Training Set, Test Set
Cross Validation Set: 测试模型以调整参数
Training Set:训练数据集
Test Set:最终测试数据集
其实我一直不太明白为什么要单独设置一个Cross Validation,后来做Review Question的时候做到这道题:为什么不能用测试数据集测试模型来调整模型参数?答案是测试数据集可能使得模型把参数调整到只适合测试数据集的范围,这样模型在遇到一个没见过的实例时,效果还是不好。所以我们单独设置一个Cross Validation集合来调整参数,如果这样最后在测试数据上的表现很好,那么就有信心这个模型是真的好了。
在这三个集合上的误差分别由如下公式计算:
Jtrain = 1/2m ∑(hθ(x(i)-y(i))2
Jcv = 1/2mcv ∑(hθ(x(i)-y(i))2
Jtest = 1/2mtest ∑(hθ(x(i)-y(i))2
3. Learning Curves:有助于查看模型是High Bias还是High Variance,两者的图分别如下
High Bias:
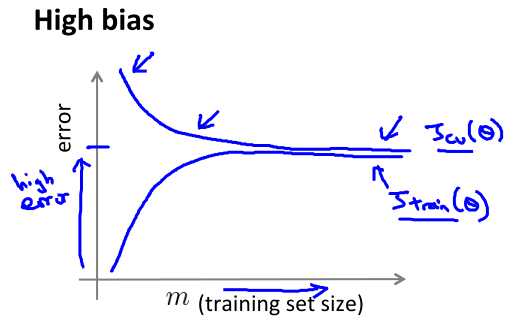
当underfitting的时候,训练数据集越少,模型越容易拟合数据,所以训练集上误差越小,此时模型几乎不能描述数据集任何特征,所以在cross validation上误差很高;随着训练数据的增加,模型的不足逐渐暴露出来,在训练数据集上的误差逐渐增大,但能描述一些数据特征,所以在corss validation上的误差逐渐减小;最后,算法在cross validation和训练数据集的误差逐渐靠近,并且都很高,最后即使增加训练数据,二者也不会降低,因为模型的“描述能力”很低,即使有再多的数据也没有发展空间了。
High Variance:
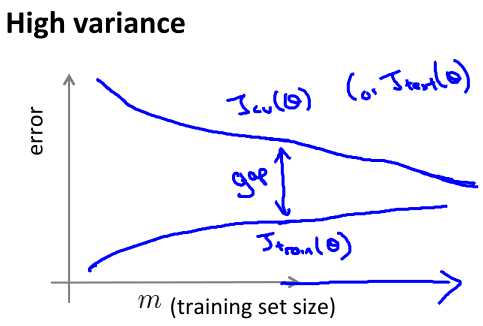
当overfitting的时候,train error和cv error变化的原因跟上述一致,不同的在于此时模型具有模型更复杂特征的能力,cv error和 train error之间会有一个gap,我们可以认为这个gap会随着训练数据的增多而减少,因为过拟合在实际中效果差的原因是它有可能拟合了一些噪音点,而没有突出数据的整体特征,那么随着训练数据的增多,受单个噪音点的影响就会降低,cv error就会降低。
4.根据High Bias和High Variance使用不同的方法
| Get more training examples | High Variance |
| Try smaller sets of features | High Variance |
| Try getting additional features | High Bias |
| Try adding polynomial features | High Bias |
| Try decreasing λ | High Bias |
| Try increasing λ | High Variance |