一种日志型数据库的实现
在《LSM存储组织结构介绍》一文中,我们了解了LSM存储结构,同时提到针对不同的业务场景,可能需要选择不同的数据库实现。假如需要存储语音、视频或图片,你会选择怎样的实现方式?不需要对类数据进行修改,也不需要排序与范围查找,下面我们来看一种日志型数据库实现方式,因其用于存储语音、图片,我们称其为media数据库。
存储格式
media数据库以数字命名数据文件,每个数据文件大小上限为FileSize左右,fileinfo文件存储当前正在被写入的文件的文件名,数据存储格式如下:
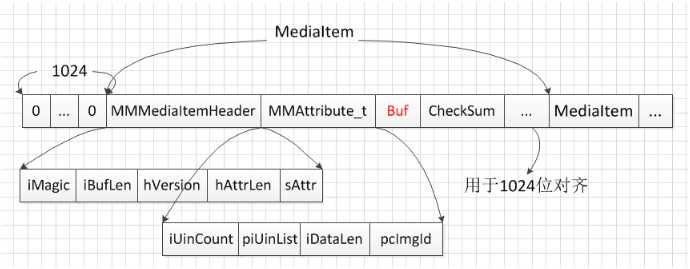
1. 每个数据文件,开头均填充1024个0
2. MMMediaItemHeader表示一条media数据的头部,其由以下字段组成:
- iMagic:写入media数据时被统一置为0xffffffff,读取时进行校验
- iBufLen:除用于1K对齐的一段外的长度,即 len(MMMediaItemHeader)+len(MMAttribute_t)+len(Buf)+len(CheckSum)
- hattrLen:MMAttribute_t的长度,即len(MMAttribute_t)
3. MMAttribute_t表示一条media数据的相关属性,由调用方填写,有以下字段组成:
- iUinCount:该条media数据对应的用户数
- piUinList:该条media数据对应的用户id列表
- iDataLen:数据Buf的长度
4. Buf:实际语音、图片等数据
5. CheckSum:Buf数据求和,读取时进行校验
写操作
对media写入数据的过程如下:
1. 取fileinfo中记录的文件,尝试Append数据
2. 如果该文件大小小于FileSize,则填充MMMediaItemHeader数据结构、计算CheckSum,写入数据
3. 如果fileinfo记录的文件大小大于FileSize,则创建一个新的文件,文件头部记录1K 0,然后再和第2步一样写入数据
完成数据写入后,最终将fileinfo信息、数据偏移offset信息返回。media的实现中,没有对数据的删除操作,media数据或永久保留,或依赖外部脚本删除,如配置定时脚本删除n天前的数据文件。
读操作
在以上写的实现中,最终将fileinfo信息、Offset值返回,读的时候,也需要调用端提供这两个信息,读过程如下:
1. 打开fileinfo指定的文件,lseek定位到偏移位置
2. 读取FirstGetLen长度的数据(假设为16K)
3. 从所读取的数据中,取开头sizeof(MMMediaItemHeader)数据,校验其中iMagic是否为0xffffffff
4. 判断iBufLen是否大于FirstGetLen,如果大于,则重新定位到fileinfo、Offset对应的位置,读取iBufLen对应长度数据
5. 从读出的数据中取出iCheckSum,再对Buf数据计算一次CheckSum,两者比对,再做一次校验
6. 返回Buf数据
容灾
我们可以考虑对media保存两份数据,实现简单的容灾,如提供一个Addbuf接口,前端对一条数据进行写入时,Addbuf分别对Master media和Slave media各做一次写操作。
小结
以上我们对图片、语音、视频存储场景,实现了一个日志型存储数据库。不同于常用数据库需要事先定义表结构,media存储的是图片、语言等不定长数据(类似mysql的blob数据类型),并没有表结构定义。
media数据库加速了写操作性能,读操作要求提供所要读取的文件和偏移量,适合单次写入后根据返回读取的场景,亦可加多一层维护文件md5、fileinfo、偏移量等数据的对应信息。