viola & jones-robust real-time face detection 大意
本论文主要有三个关键的贡献:
- 使用积分图快速地计算haar特征
- 使用adaboost算法从特征池中现在关键的特征
- 构建分类器级联实现快速的人脸检测
haar特征:
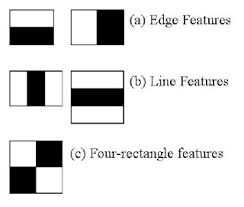
本论文使用三种简单的矩形特征:
- 由上下(或者左右)邻接的大小相同的两个矩形组成(如下图a),特征值为白的矩形的像素和减去黑的矩形的像素和
- 由上下(或者左右)邻接的大小相同的三个矩形组成(如下图b),特征值为白的矩形的像素和减去黑的矩形的像素和
- 由四个矩形组成(如下图c),特征值为白的矩形的像素和减去黑的矩形的像素和
如下图所示:
积分图像:
积分图像的定义如下:
ii(x,y) = ∑i(x‘,y‘),其中x‘<=x,y‘<=y
即递归式:
s(x,y) = s(x,y-1)+i(x,y)
ii(x,y) = ii(x-1,y)+s(x,y)
s(x,-1) = 0
ii(-1,y) = 0
其中s(x,y)为第x行的累计和,i(x,y)为原始图像的像素值。
积分图像可以通过遍历一次原始图像计算好。
任何的矩形可以通过4次访问积分图像计算好。
分类函数:
本论文使用简单阈值型分类函数(也叫弱分类器),定义如下:
h(x,f,p,θ) = 1 if pf(x) < pθ
0 otherwise
其中,x为24*24的被检测图像的子窗口,f(x)为该窗口求出的haar特征值,p为正负号,θ为阈值。
因为使用单个的特征组成的分类器不能够使产生较低的错误率,所以可以使用多个特征(多个弱分类器)组成一个较强的强分类器。
下面使用adaboost算法选择分类错误较小的弱分类器组成一个强分类器的步骤:
- 给定样本图像(x1,y1),...,(xn,yn),其中yi=0,1,分别对应负和正的样本
- 初始化每个样本的权重,正样本为w1,i=1/(2m),其中m为正样本的数目,负样本为w1,i=1/(2l),其中l为负样本数目
- 迭代T次产生T个当前样本权重下分类错误率较低的弱分类器:
-
- 归一化样本权重
- 选择当前权重下分类错误权重最小的弱分类器,分类错误权重定义如下:
εt=minf,p,θ=∑wi|h(xi,f,p,θ)-yi|
- 得到一个弱分类器:ht(x) = h(x,ft,pt,θt)使得εt最小
- 更新样本权重:
wt+1,i = wt,iβt1-ei,其中βt = εt/(1-εt),弱分类器分类正确是ei为0,否则为1。
- 得到最终的强分类器:
C(x) = 1 ∑atht(x)>=1/2∑at
0 otherwise
其中,at = log1/βt
对于训练过程中选取当前样本权重下分类错误权重最低的分类器的算法如下:
- 对于每个特征,样本计算该特征的特征值,以该特征值从大到下排序。
- 对于该特征的最佳阈值计算过程只需遍历一次上面已排序的列表,此过程需要维持4个数值:正样本权重和T+、负样本权重和T-、当前样本下的正样本的权重和S+和当前样本下的负样本的权重S-。
- 遍历过程中,以当前样本特征值为阈值的错误为e=min(S++(T--S-),S-+(T+-S+))
- 选择遍历过程中e最小的当前样本特征值作为使用该特征的弱分类器的阈值,正负号p取决于e是S++(T--S-)还是S-+(T+-S+)
强分类器级联:
级联的结构如下:
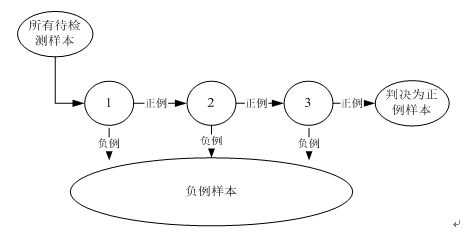
被检测的图像的所有的子窗口经过级联结构中每个强分类器,如果该强分类器判定为0,则该子窗口立即抛弃。直到到达最后的子窗口才会判定为人脸。这样的结构可以实现快速的人脸检测。
训练级联的检测器的主要的思想是使非人脸尽快得在级联结构的前面几级的强分类器中开始的被抛弃,因此训练好的级联检测器后一级强分类器一般比前一级跟复杂。
训练级联的算法如下:
- 选择每级最大可接受的虚警率f和每级最小可接受的检出率d
- 选择整个级联检测器的虚警率Ftarget
- P-正样本集合
- N-负样本集合
- F0=1.0;D0=1.0
- i=0
- while Fi > Ftarget
i=i+1
ni=0;Fi=Fi-1
while Fi > f*Fi-1
ni=ni+1
利用adaboost算法,使用样本P和N训练一个由ni个弱分类器组成的强分类器
计算当前级联的分类器在验证集上的虚警率Fi和检出率Di
降低第i个强分类器(即上面使用P和N样本训练的强分类器)的阈值直到级联检测器的检出率达到d*Di-1
- N-清空
- 如果Fi>Ftarget,则使用当前的级联检测器产生训练需要的负样本,把负样本加到负样本集N中
其它需要的注意的事项:
- 图像处理
计算矩形特征值时需要归一化特征子窗口的像素值,减少光照等带来的影响。
归一化方法:x=(x-m)/σ,其中x为像素值,m为子窗口的均值,σ为标准差
标准差σ计算方法:σ2 = m2 - 1/N∑x2,其中N为子窗口的像素数目。
使用积分图可以快速的计算均值,而使用像素值平方的积分图像可以快速的计算1/N∑x2。
所以训练是需要计算2个积分图像。
- 检测器扫描
检测器检测时是使用多个尺度和位置的检测器扫描被检测图像,即尺度的变化是检测器而不是被检测图像。使用每个尺度之间的缩放率scale为1.25可以获取好的检测效果。在被检测图像中的移动步长Δ,Δ也是受scale影响。Δ的选择影响检测速度和检出率。Δ越小检出率越高,但是检测速度就越慢。
- 多个检测结果的合并
由于最终的检测器对飘移和缩放的微笑变化不敏感,所以多个检测结果可能出现在每个人脸图像周围。实际上,应该对于这样的情况只需要返回一个检测结果就行。因此需要合并重复的检测区域。处理的过程:没重叠的直接放到结果中,重复的只需求一个平均的区域,然后放到结果中。
viola & jones-robust real-time face detection 大意,布布扣,bubuko.com