Sql Server 数据分页
http://www.cnblogs.com/qqlin/archive/2012/11/01/2745161.html
1.引言
在列表查询时由于数据量非常多,一次性查出来会非常慢,就算一次查出来了,也不能一次性显示给客户端,所以要把数据进行分批查询出来,每页显示一定量的数据,这就是数据要分页。
2.常用的数据分页方法
我们经常会碰到要取n到m条记录,就是有分页思想,下面罗列一下一般的方法。
我本地的一张表 tbl_FlightsDetail,有300多W记录,主键 FlightsDetailID(Guid),要求按照FlightsDetailID排序 取 3000001 到3000010 之间的10条记录,也是百万级。
方法1 定位法 (利用ID大于多少)
语句形式:
select top 10 * from tbl_FlightsDetail where FlightsDetailID>( select max(FlightsDetailID) from ( select top 3000000 FlightsDetailID from tbl_FlightsDetail order by FlightsDetailID ) as t ) order by FlightsDetailID
执行计划:
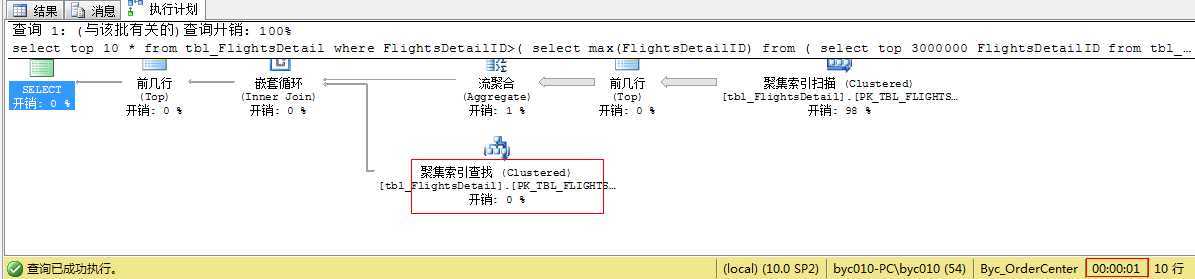
先查出 top 300000,再聚合取这个集合中最大的Id1,再过滤 id大于id1的集合(上图中使用到索引),再取top 10 条。
方法2 (利用Not In)
语句形式:
select top 10* from tbl_FlightsDetail where FlightsDetailID not in ( select top 3000000 FlightsDetailID from tbl_FlightsDetail order by FlightsDetailID ) order by FlightsDetailID
执行计划:
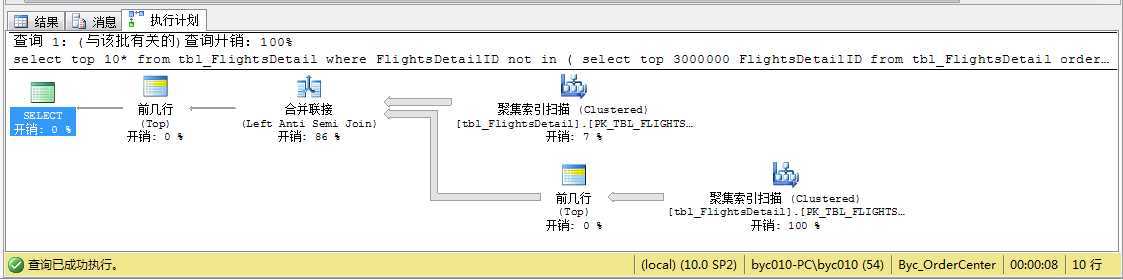
和方法一类似,只是过滤where条件不一样,这里用到的是not in,上图中没有用到索引,耗时8秒。如果 FlightsDetailID不是索引的话,方法1和该方法将差不多。
方法3 (利用颠颠倒倒top)
语句形式:
select top 10* from ( select top 3000010* from tbl_FlightsDetail order by FlightsDetailID ) as t order by t.FlightsDetailID desc
执行计划:
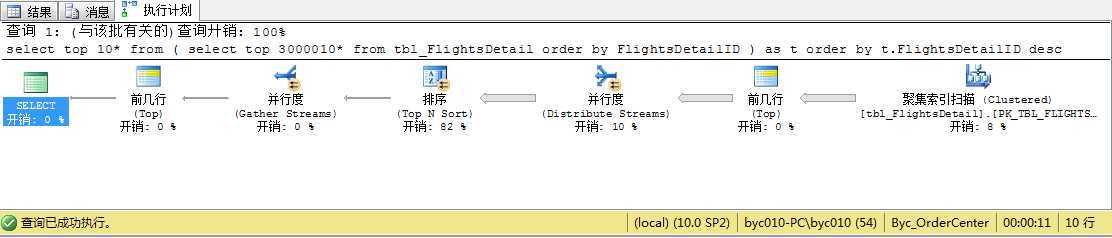
先取 前面3000010条记录,再倒序,这时再取前面10条即是300001 到300010条记录,没有用到索引,耗时11秒
方法4 (ROW_NUMBER()函数)
语句形式:
select * from ( select *,ROW_NUMBER() OVER (ORDER BY FlightsDetailID) as rank from tbl_FlightsDetail ) as t where t.rank between 3000001 and 3000010
执行计划:

Sql 2005版本或以上支持,也没用到索引,耗时2秒,速度还不错。
方法5 (利用IN)
此方法是由 金色海洋(jyk)阳光男孩
回复的,飞常感谢,语句形式:
select top 10 * from tbl_FlightsDetail where FlightsDetailID in( select top 10 FlightsDetailID from( select top 3000010 FlightsDetailID from tbl_FlightsDetail order by FlightsDetailID ) as t order by t.FlightsDetailID desc ) order by FlightsDetailID
执行计划:
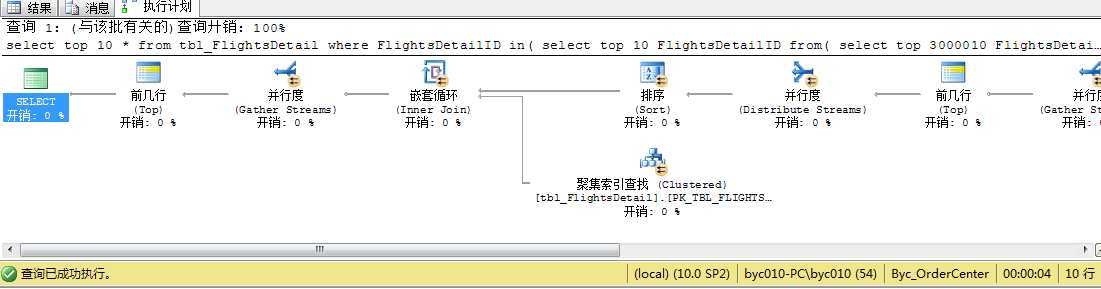
多次执行之后一般维持在4秒左右,用到索引,非常不错,计划图还很长,只截取部分,可能是绕的多一点。
3.千万级分页存储过程
大家百度一下这个标题立马会出现很多相关信息,都大同小异,我自己拷贝的一个,应项目的需要,修改了一个排序的bug以及添加了返回总记录数,如下:

SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO --分页存储过程 CREATE PROCEDURE [dbo].[sp_Paging] ( @Tables nvarchar(1000), --表名/视图名 @PrimaryKey nvarchar(100), --主键 @Sort nvarchar(200) = NULL, --排序字段(不带order by) @pageindex int = 1, --当前页码 @PageSize int = 10, --每页记录数 @Fields nvarchar(1000) = N‘*‘, --输出字段 @Filter nvarchar(1000) = NULL, --where过滤条件(不带where) @Group nvarchar(1000) = NULL, --Group语句(不带Group By) @TotalCount int OUTPUT --总记录数 ) AS DECLARE @SortTable nvarchar(100) DECLARE @SortName nvarchar(100) DECLARE @strSortColumn nvarchar(200) DECLARE @operator char(2) DECLARE @type nvarchar(100) DECLARE @prec int --设定排序语句 IF @Sort IS NULL OR @Sort = ‘‘ SET @Sort = @PrimaryKey IF CHARINDEX(‘DESC‘,@Sort)>0 BEGIN SET @strSortColumn = REPLACE(@Sort, ‘DESC‘, ‘‘) SET @operator = ‘<=‘ END ELSE BEGIN SET @strSortColumn = REPLACE(@Sort, ‘ASC‘, ‘‘) SET @operator = ‘>=‘ END IF CHARINDEX(‘.‘, @strSortColumn) > 0 BEGIN SET @SortTable = SUBSTRING(@strSortColumn, 0, CHARINDEX(‘.‘,@strSortColumn)) SET @SortName = SUBSTRING(@strSortColumn, CHARINDEX(‘.‘,@strSortColumn) + 1, LEN(@strSortColumn)) END ELSE BEGIN SET @SortTable = @Tables SET @SortName = @strSortColumn END --设置排序字段类型和精度 SELECT @type=t.name, @prec=c.prec FROM sysobjects o JOIN syscolumns c on o.id=c.id JOIN systypes t on c.xusertype=t.xusertype WHERE o.name = @SortTable AND c.name = @SortName IF CHARINDEX(‘char‘, @type) > 0 SET @type = @type + ‘(‘ + CAST(@prec AS varchar) + ‘)‘ DECLARE @strPageSize nvarchar(50) DECLARE @strStartRow nvarchar(50) DECLARE @strFilter nvarchar(1000) DECLARE @strSimpleFilter nvarchar(1000) DECLARE @strGroup nvarchar(1000) IF @pageindex <1 SET @pageindex = 1 SET @strPageSize = CAST(@PageSize AS nvarchar(50)) --设置开始分页记录数 SET @strStartRow = CAST(((@pageindex - 1)*@PageSize + 1) AS nvarchar(50)) --筛选以及分组语句 IF @Filter IS NOT NULL AND @Filter != ‘‘ BEGIN SET @strFilter = ‘ WHERE ‘ + @Filter + ‘ ‘ SET @strSimpleFilter = ‘ AND ‘ + @Filter + ‘ ‘ END ELSE BEGIN SET @strSimpleFilter = ‘‘ SET @strFilter = ‘‘ END IF @Group IS NOT NULL AND @Group != ‘‘ SET @strGroup = ‘ GROUP BY ‘ --计算总记录数 DECLARE @TotalCountSql nvarchar(1000) SET @TotalCountSql=N‘SELECT @TotalCount=COUNT(*)‘ +N‘ FROM ‘ + @Tables + @strFilter EXEC sp_executesql @TotalCountSql,N‘@TotalCount int OUTPUT‘,@TotalCount OUTPUT --执行查询语句 EXEC( ‘ DECLARE @SortColumn ‘ + @type + ‘ SET ROWCOUNT ‘ + @strStartRow + ‘ SELECT @SortColumn=‘ + @strSortColumn + ‘ FROM ‘ + @Tables + @strFilter + ‘ ‘ + @strGroup + ‘ ORDER BY ‘ + @Sort + ‘ SET ROWCOUNT ‘ + @strPageSize + ‘ SELECT ‘ + @Fields + ‘ FROM ‘ + @Tables + ‘ WHERE ‘ + @strSortColumn + @operator + ‘ @SortColumn ‘ + @strSimpleFilter + ‘ ‘ + @strGroup + ‘ ORDER BY ‘ + @Sort + ‘ ‘ )
现在我们来测试一下:
DECLARE @return_value int, @TotalCount int EXEC @return_value = [dbo].[sp_Paging] @Tables = N‘tbl_FlightsDetail‘, @PrimaryKey = N‘FlightsDetailID‘, @Sort = N‘FlightsDetailID‘, @pageindex = 299999, @PageSize = 10, @Fields = ‘*‘, @Filter = NULL, @Group = NULL, @TotalCount = @TotalCount OUTPUT SELECT @TotalCount as N‘@TotalCount‘ SELECT ‘Return Value‘ = @return_value
执行计划:
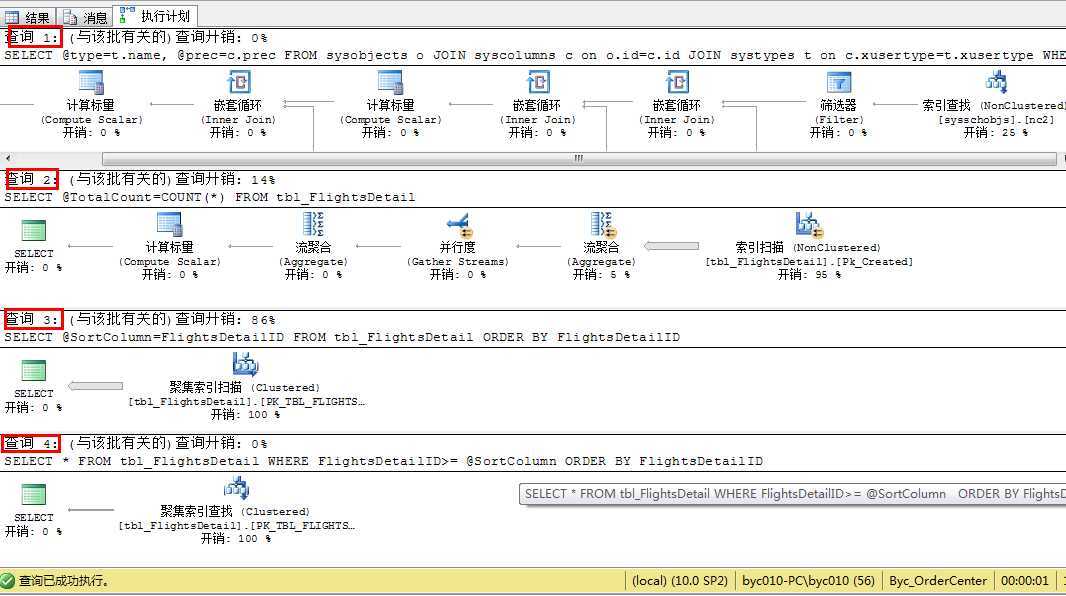
看时间的确是快,执行计划显示4个查询
查询1,是利用系统表获取排序字段、类型和精度,这个很快,全是索引。
查询2,返回总记录数,第一次会慢点,后面就很快了。
查询3 和查询4(用到索引) 才是我们要分页取的数据,查询3 是排序,取一个最大的值赋给变量,查询4是大于这个变量的值 取数据,直接看sql语句,把上面的exec动态语句改成如下:
DECLARE @SortColumn varchar(40) --即 top 3000001,取出最大的 id覆盖@SortColumn SET ROWCOUNT 3000001 SELECT @SortColumn= FlightsDetailID FROM tbl_FlightsDetail ORDER BY FlightsDetailID --即 top 10 SET ROWCOUNT 10 SELECT * FROM tbl_FlightsDetail WHERE FlightsDetailID >= @SortColumn ORDER BY FlightsDetailID
你会发现,原来它跟我们标题2 常用的数据分页方法 中的 方法1 定位 类似,原来奥秘在这。
4.小结
还有一些用游标、表变量的那个性能差不作考虑。分页存储过程看起来挺复杂的,语句多,其实都在判断,在左组装,右组装,最终组装成类似 标题2中常用的分页方法中的 的一种语句,掌握了常用的数据分页方法,大家就可以自己写了,当然还有其它的方法,大家可以分享出来。