linux 目标文件(*.o) bss,data,text,rodata,堆,栈 以及程序加载运行理解(转)
一、编译及加载
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可加载、可执行代码的过程
程序运行时会将编译好的文件从外存中加载到内存中,而后进行运行
过程图解如下:
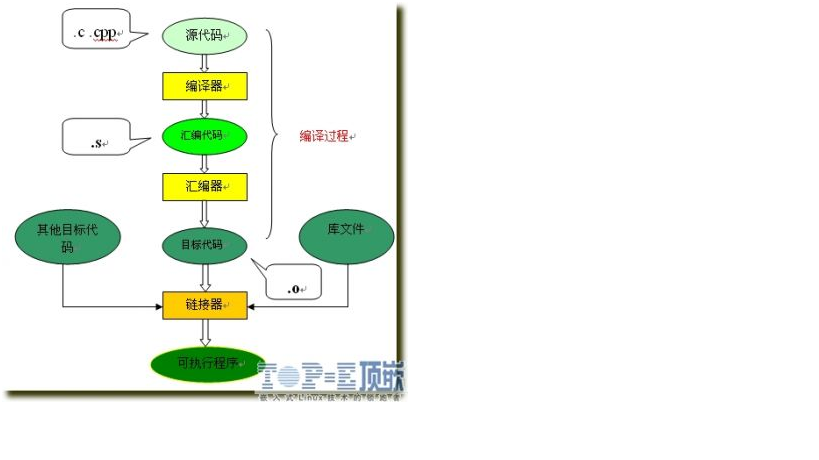
- 预处理器:将.c 文件转化成 .i文件,使用的gcc命令是:gcc –E,对应于预处理命令cpp;
- 编译器:将.c/.h文件转换成.s文件,使用的gcc命令是:gcc –S,对应于编译命令 cc –S;
- 汇编器:将.s 文件转化成 .o文件,使用的gcc 命令是:gcc –c,对应于汇编命令是 as;
- 链接器:将.o文件转化成可执行程序,使用的gcc 命令是: gcc,对应于链接命令是 ld;
- 加载器:将可执行程序加载到内存并进行执行,loader和ld-linux.so。
二、编译过程
编译过程又可以分成两个阶段:编译和汇编。
2.1编译
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
源文件的编译过程包含两个主要阶段:
第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。
主要是以下几方面的处理:
- 宏定义指令,如 #define a b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。
- 条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉
- 头文件包含指令,如#include "FileName"或者#include 等。 该指令将头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。
- 特殊符号,预编译程序可以识别一些特殊的符号。 例如在源程序中出现的LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。预编译程序对于在源程序中出现的这些串将用合适的值进行替换。
头文件的目的主要是为了使某些定义可以供多个不同的C源程序使用,这涉及到头文件的定位即搜索路径问题。头文件搜索规则如下:
- 所有header file的搜寻会从-I开始
- 然后找环境变量 C_INCLUDE_PATH,CPLUS_INCLUDE_PATH,OBJC_INCLUDE_PATH指定的路径
- 再找默认目录(/usr/include、/usr/local/include、/usr/lib/gcc-lib/i386-linux/2.95.2/include......)
第二个阶段编译、优化阶段,编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
2.2汇编
汇编实际上指汇编器(as)把汇编语言代码翻译成目标机器指令的过程。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。目标文件由段组成。通常一个目标文件中至少有两个段:
- 代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
- 数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
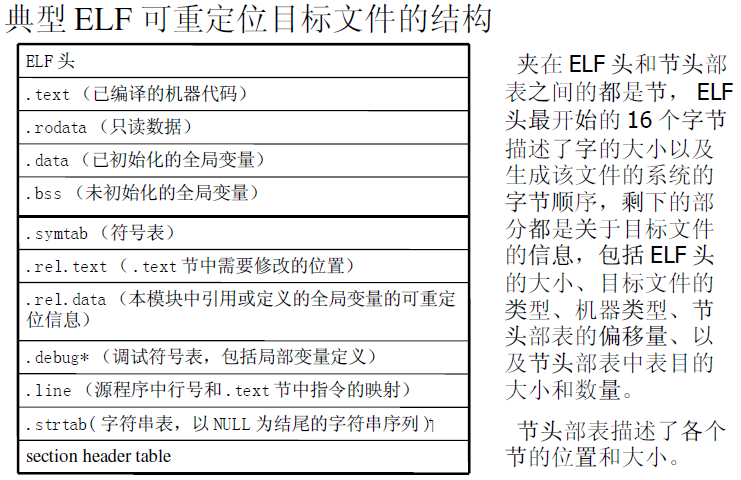
2.3目标文件(Executable and Linkable Format)
- 可重定位(Relocatable)文件:由编译器和汇编器生成,可以与其他可重定位目标文件合并创建一个可执行或共享的目标文件;
- 共享(Shared)目标文件:一类特殊的可重定位目标文件,可以在链接(静态共享库)时加入目标文件或加载时或运行时(动态共享库)被动态的加载到内存并执行;
- 可执行(Executable)文件:由链接器生成,可以直接通过加载器加载到内存中充当进程执行的文件。
2.4 静态库与动态库
静态库(static library)就是将相关的目标模块打包形成的单独的文件。使用ar命令。
静态库的优点在于:
- 程序员不需要显式的指定所有需要链接的目标模块,因为指定是一个耗时且容易出错的过程;
- 链接时,连接程序只从静态库中拷贝被程序引用的目标模块,这样就减小了可执行文件在磁盘和内存中的大小。
动态库(dynamic library)是一种特殊的目标模块,它可以在运行时被加载到任意的内存地址,或者是与任意的程序进行链接。
动态库的优点在于:
- 更新动态库,无需重新链接;对于大系统,重新链接是一个非常耗时的过程;
- 运行中可供多个程序使用,内存中只需要有一份,节省内存。
三、链接过程
链接器主要是将有关的目标文件彼此相连接生成可加载、可执行的目标文件。链接器的核心工作就是符号表解析和重定位。
3.1 链接的时机:
- 编译时,就是源代码被编译成机器代码时(静态链接器负责);
- 加载时,也就是程序被加载到内存时(加载器负责);
- 运行时,由应用程序来实施(动态链接器负责)。
3.2 链接的作用(软件复用):
- 使得分离编译成为可能;
- 动态绑定(binding):使定义、实现、使用分离
3.3 静态库搜索路径(由静态链接器负责)
- gcc先从-L寻找;
- 再找环境变量LIBRARY_PATH指定的搜索路径;
- 再找内定目录 /lib /usr/lib /usr/local/lib 这是当初compile gcc时写在程序内的。
3.4 动态库搜索路径(由动态链接器负责)
- 编译目标代码时指定的动态库搜索路径-L;
- 环境变量LD_LIBRARY_PATH指定的动态库搜索路径;
- 配置文件/etc/ld.so.conf中指定的动态库搜索路径;
- 默认的动态库搜索路径/lib /usr/lib/ /usr/local/lib
3.5 静态链接(编译时)
链接器将函数的代码从其所在地(目标文件或静态链接库中)拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
为创建可执行文件,链接器必须要完成的主要任务:
- 符号解析:把目标文件中符号的定义和引用联系起来;
- 重定位:把符号定义和内存地址对应起来,然后修改所有对符号的引用。
关于符号表和符号解析以及重定位的分析后续学习。
3.6 动态链接(加载、运行时)
在此种方式下,函数的定义在动态链接库或共享对象的目标文件中。在编译的链接阶段,动态链接库只提供符号表和其他少量信息用于保证所有符号引用都有定义,保证编译顺利通过。动态链接器(ld-linux.so)链接程序在运行过程中根据记录的共享对象的符号定义来动态加载共享库,然后完成重定位。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
四、加载过程
加载器把可执行文件从外存加载到内存并进行执行。 Linux中进程运行时的内存映像如下:
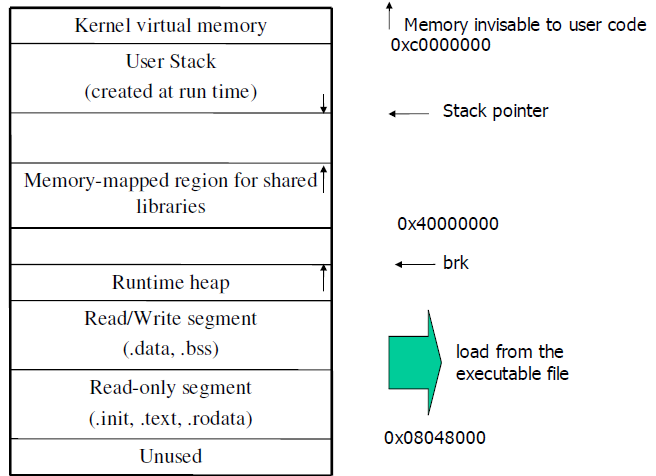
加载过程如下:
加载器首先创建如上图所示的内存映像,然后根据段头部表,把目标文件拷贝到内存的数据和代码段中。然后,加载器跳转到程序入口点(即符号_start 的地址),执行启动代码(startup code),启动代码的调用顺序如所示:

五、处理目标的常用工具
UNIX系统提供了一系列工具帮助理解和处理目标文件。GNUbinutils 包也提供了很多帮助。这些工具包括:
- AR :创建静态库,插入、删除、列出和提取成员;
- STRINGS :列出目标文件中所有可以打印的字符串;
- STRIP :从目标文件中删除符号表信息;
- NM :列出目标文件符号表中定义的符号;
- SIZE :列出目标文件中节的名字和大小;
- READELF :显示一个目标文件的完整结构,包括ELF 头中编码的所有信息。
- OBJDUMP :显示目标文件的所有信息,最有用的功能是反汇编.text节中的二进制指令。
- LDD :列出可执行文件在运行时需要的共享库。
六、编译文件详解
一个简单的程序被编译成目标文件后的结构如下:
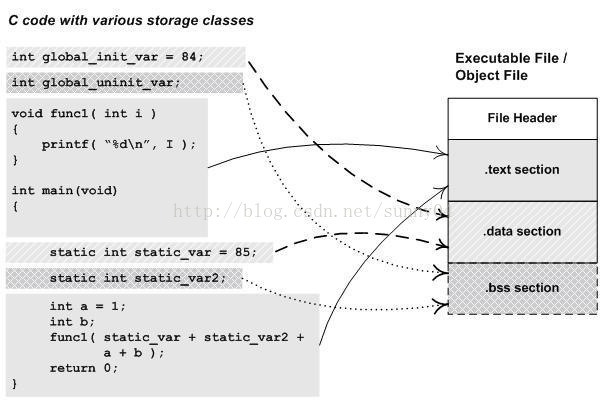
从图可以看出,已初始化的全局变量和局部静态变量保存在 .data段中,未初始化的全局变量和未初始化的局部静态变量保存在 .bss段中。
目标文件各个段在文件中的布局如下:
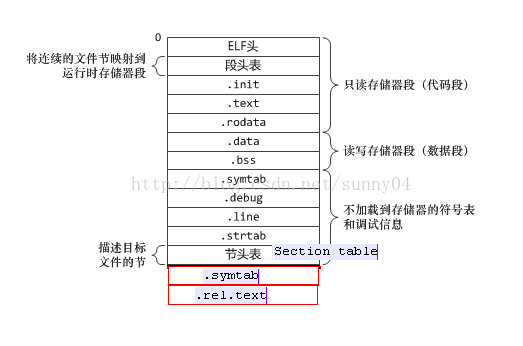
各个段介绍:
init段:
程序初始化入口代码,在main() 之前运行。
bss段:
BSS段属于静态内存分配。通常是指用来存放程序中未初始化的全局变量和未初始化的局部静态变量。未初始化的全局变量和未初始化的局部静态变量默认值是0,本来这些变量也可以放到data段的,但是因为他们都是0,所以为他们在data段分配空间并且存放数据0是没有必要的。
程序在运行时,才会给BSS段里面的变量分配内存空间。
在目标文件(*.o)和可执行文件中,BSS段只是为未初始化的全局变量和未初始化的局部静态变量预留位置而已,它并没有内容,所以它不占据空间。
section table中保存了BSS段(未初始化的全局变量和未初始化的局部静态变量)内存空间大小总和。 (objdump -h *.o 命令可以看到)
data段:
数据段(datasegment)通常是指用来存放程序中已初始化的全局变量和已初始化的静态变量的一块内存区域。数据段属于静态内存分配。
text段:
代码段(codesegment/textsegment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
rodata段:
存放的是只读数据,比如字符串常量,全局const变量 和 #define定义的常量。例如: char*p="123456", "123456"就存放在rodata段中。
strtab段:
存储的是变量名,函数名等。例如: char* szPath="/root",void func() 变量名szPath 和函数名func 存储在strtab段里。
shstrtab段:
bss,text,data等段名也存储在这里。
rel.text段:
针对 text段的重定位表,还有 rel.data(针对data段的重定位表)
heap堆:
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
stack栈:
是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
验证BSS内存空间
程序1:
int ar[30000];
void main()
{
......
}
程序2:
int ar[300000] = {1, 2, 3, 4, 5, 6 };
void main()
{
......
}
结论是:程序2编译之后所得的.exe文件比程序1的要大得多。 为什么?
区别很明显,一个位于.bss段,而另一个位于.data段,两者的区别在于:
l 全局的未初始化变量存在于.bss段中,具体体现为一个占位符;全局的已初始化变量存于.data段中;
l 而函数内的自动变量都在栈上分配空间。
l .bss是不占用.exe文件空间的,其内容由操作系统初始化(清零);
l 而.data却需要占用,其内容由程序初始化,因此造成了上述情况。
注意:
1. bss段(未手动初始化的数据)并不给该段的数据分配空间. 程序运行后,系统分配内存空间并由系统初始化,默认内存空间的值都为0. section table中保存了BSS段(未初始化的全局变量和未初始化的局部静态变量)内存空间大小总和,所以程序运行后,系统知道该分配多少内存给BSS段。
2. data(已手动初始化的数据)段则为数据分配空间,数据保存在目标文件中。
这里有个疑问: data段是变量的内存空间,那是如何区分哪几个字节是变量a的? 哪几个字节是变量b的? 因为变量a,b的内存空间是在一起的,如果你不告诉他们的类型,我们的确是不知道变量a有几个字节,变量b有几个字节。
那么哪里保存了 变量a,b的类型了? 查资料发现,text代码段中调用a的汇编代码,是会告诉我们变量a的类型的,这样我们就知道读取哪几个字节的值了。 程序运行起来后,BSS段中变量内存数据读取原理类似。
转自:
https://blog.csdn.net/weixin_41042404/article/details/81239416
https://blog.csdn.net/sunny04/article/details/40627311