Python数据分析:股价相关性
为什么要分析股价相关度呢,我们来引入一个概念——配对交易
所谓的配对交易,是基于统计套利的配对交易策略是一种市场中性策略,具体的说,是指从市场上找出历史股价走势相近的股票进行配对,当配对的股票价格差偏离历史均值时,则做空股价较高的股票同时买进股价较低的股票,等待他们回归到长期均衡关系,由此赚取两股票价格收敛的报酬。
接下来开始我们的股价相关度分析,首先我们选两个股票 ~

感觉全聚德和光明乳业都很好吃的样子,我们就选它们了吧! =  ̄ω ̄ =
1 、导入数据包
简单介绍一下要用到的数据包
matplotlib.pyplot :绘图库,其中 pyplot 子包提供一个类 MATLAB 的绘图框架
numpy :科学计算库,支持高级大量的维度数组与矩阵运算
pandas :纳入了大量库和一些标准的数据模型,提供高效地操作大型数据集所需的工具
tushare :财经数据接口包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tushare as ts
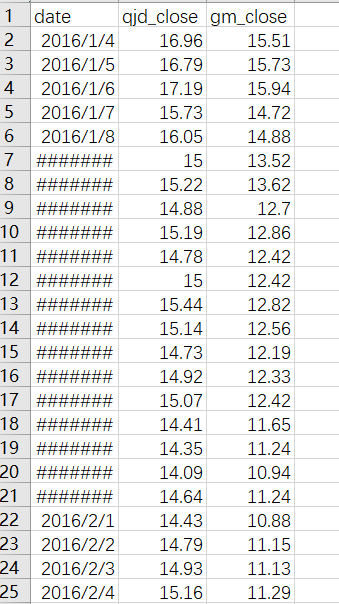
2 、根据全聚德和光明乳业的股票代码获取数据,这里获取的是 2016 年一整年的收盘价,获取完后合并,因为停牌的存在,用前一天的价格去填写缺失数据,最终以 CSV 格式保存数据
s_qjd = ‘002186‘ #全聚德
s_gm = ‘600597‘ #光明乳业
sdate = ‘2016-01-01‘#起止日期
edate = ‘2016-12-31‘
df_qjd = ts.get_h_data(s_qjd, start = sdate, end = edate).sort_index(axis = 0,ascending=True)#获取历史数据
df_gm = ts.get_h_data(s_gm, start = sdate, end = edate).sort_index(axis = 0,ascending=True)
df = pd.concat([df_qjd.close,df_gm.close], axis = 1, keys=[‘qjd_close‘, ‘gm_close‘])#合并
df.ffill(axis=0, inplace=True)#填充缺失数据
df.to_csv(‘qjd_gm.csv‘)
3 、用 pearson 相关系数计算相关度( Pearson 相关系数是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。),再打印出来看一眼
corr = df.corr(method = ‘pearson‘, min_periods = 1)#pearson方法计算相关性
print(corr)

算出来有 0.81 ,超过 0.8 ,按值域等级来说属于极强相关,不过话说一个卖烤鸭的为什么会和卖牛奶的相关度那么高。。。。难道大家吃烤鸭的时候都喜欢喝牛奶吗。。。
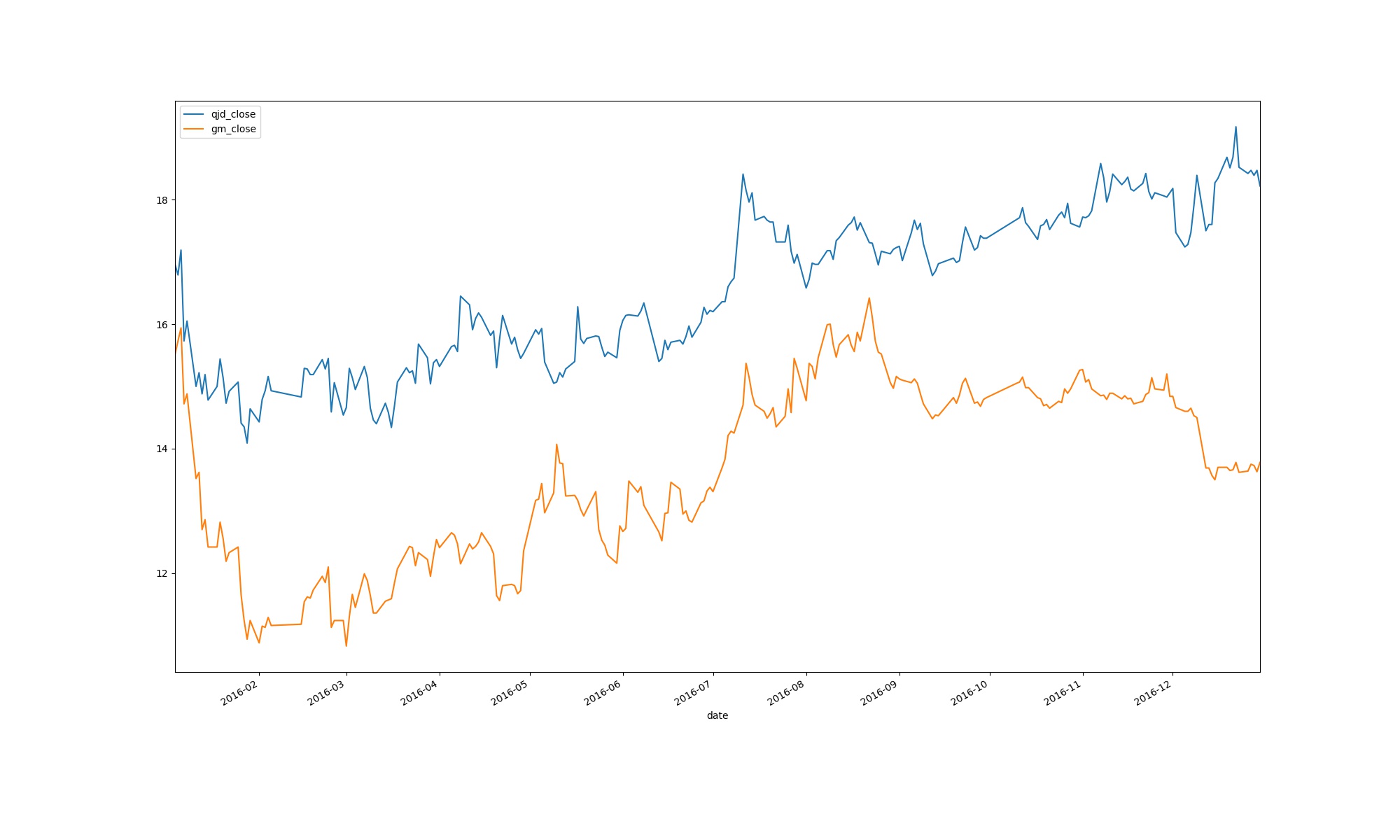
df.plot(figsize = (20,12))
plt.savefig(‘qjd_gm.jpg‘)
plt.close()
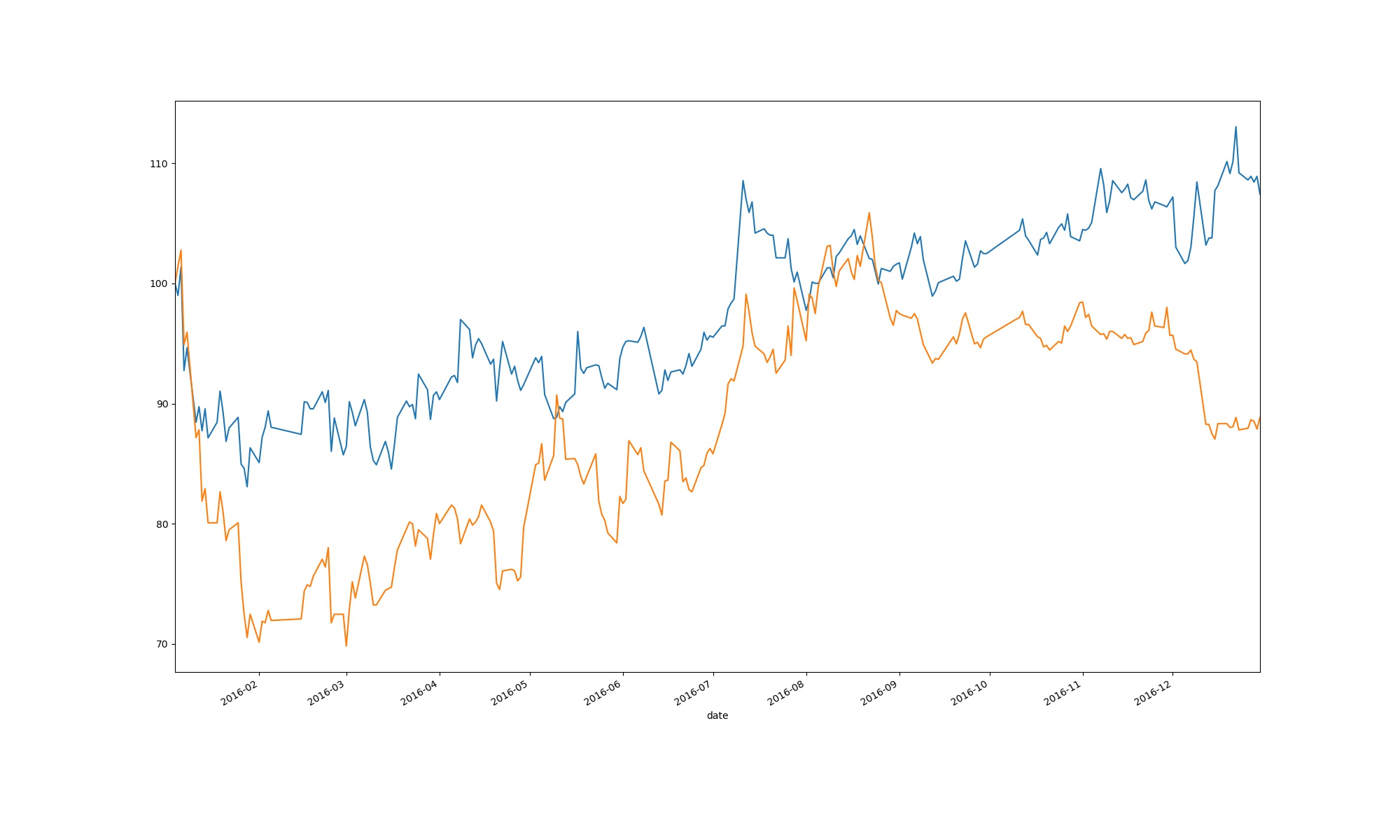
5 、按分析日期的第一天的股价为基准做归一化处理,打印图像
df[‘qjd_one‘] = df.qjd_close / float(df.qjd_close[0])*100
df[‘gm_one‘] = df.gm_close / float(df.gm_close[0])*100
df.qjd_one.plot(figsize = (20,12))
df.gm_one.plot(figsize = (20,12))
plt.savefig(‘qjd_gm_one.jpg‘)
好啦,做完啦,虽然我也不知道为什么全聚德会和光明乳业这么高相关性
不过理论上是可以做配对交易的,不过股票有风险,投资需谨慎 ~
╮ ( ╯ ▽ ╰ ) ╭
以下是完整代码:
# coding=gbk
import matplotlib.pyplot as plt #提供类matlab里绘图框架
import numpy as np
import pandas as pd
import tushare as ts
#获取数据
s_qjd = ‘002186‘ #全聚德
s_gm = ‘600597‘ #光明乳业
sdate = ‘2016-01-01‘#起止日期
edate = ‘2016-12-31‘
df_qjd = ts.get_h_data(s_qjd, start = sdate, end = edate).sort_index(axis = 0,ascending=True)#获取历史数据
df_gm = ts.get_h_data(s_gm, start = sdate, end = edate).sort_index(axis = 0,ascending=True)
df = pd.concat([df_qjd.close,df_gm.close], axis = 1, keys=[‘qjd_close‘, ‘gm_close‘])#合并
df.ffill(axis=0, inplace=True)#填充缺失数据
df.to_csv(‘qjd_gm.csv‘)
#pearson方法计算相关性
corr = df.corr(method = ‘pearson‘, min_periods = 1)
print(corr)
#打印图像
df.plot(figsize = (20,12))
plt.savefig(‘qjd_gm.jpg‘)
plt.close()
#归一化处理打印图像
df[‘qjd_one‘] = df.qjd_close / float(df.qjd_close[0])*100
df[‘gm_one‘] = df.gm_close / float(df.gm_close[0])*100
df.qjd_one.plot(figsize = (20,12))
df.gm_one.plot(figsize = (20,12))
plt.savefig(‘qjd_gm_one.jpg‘)
[/code]
?
?
参考资料:
?
[1] MBA 智库百科 [
http://wiki.mbalib.com/wiki/%E9%85%8D%E5%AF%B9%E4%BA%A4%E6%98%93
](http://wiki.mbalib.com/wiki/%E9%85%8D%E5%AF%B9%E4%BA%A4%E6%98%93)
?
[2] 东方财富网 http://quote.eastmoney.com/stocklist.html
?
[3] 七月在线 [ https://ask.julyedu.com/ ](https://ask.julyedu.com/)
?
[4] Tushare [ http://tushare.org/ ](http://tushare.org/)
?
?
?
?
?
?
?
