华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库;它依靠共享存储池实现了强一致,保证数据的安全可靠。
本文分享自华为云社区《华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历》,原文作者:Cassandra官方 。
背景介绍
华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库;它依靠共享存储池实现了强一致,保证数据的安全可靠。核心特点是:存算分离、低成本、高性能。
问题描述
GaussDB(for Cassandra)自研架构下遇到一些挑战性问题,比如cpu过高,内存泄漏,内存异常增长,时延高等问题,这些也都是开发过程中遇到的典型问题。分析内存异常增长是一个比较大的挑战,内存的异常增长对于程序来说是一个致命的问题,因为其可能触发OOM,进程异常宕机,业务中断等结果,所以对内存进行合理的规划使用及控制就显得尤为重要。通过调整cache容量,bloom过滤器大小,以及memtable大小等等,实现性能提升,读写时延改善等效果。
在线下测试过程中发现内核在长时间运行后,内存只增不减,出现异常增长的情况,怀疑可能存在内存泄漏。
分析&验证
首先根据内存使用,将内存分为堆内和堆外两个部分,分别进行该两块内存的分析。确定有问题的内存是堆外内存,进一步对堆外内存分析。引入更高效的内存管理工具tcmalloc,解决内存异常增长问题。下面为具体分析验证过程。
确定内存异常区域
使用jdk的jmap命令和Cassandra的监控(配置jvm.memory.*监控项)等方法,每隔1min采集jvm的堆内内存及进程整体内存。
启动测试用例,直到内核的整体内存达到上限。分析采集到的堆内内存和进程内存变化曲线,发现其堆内内存仍保持相对稳定,未出现一直持续上涨,但期间内核的整体内存仍然在持续上涨,两者的增长曲线不符。即问题应该发生在堆外内存。
堆外内存分析验证
glibc内存管理
使用pmap命令打印进程的内存地址空间分布,发现有大量的64MB的内存块和许多内存碎片,该现象与glibc的内存分配方式有关。堆外内存的使用和进程整体的内存增长趋势相近,初步怀疑该问题是由堆外内存导致。加之glibc归还内存的条件苛刻,即内存不易及时释放,内存碎片多,猜测问题和gblic有关系。当内存碎片过多,空闲内存浪费严重,最终进程内存的最大使用量会出现超过预期计划最大值的可能,甚至出现OOM。
tcmalloc内存管理
引入tcmalloc内存管理器,代替glibc的ptmalloc内存管理方式。减少过多的内存碎片,提高内存使用效率,本次分析验证采用gperftools-2.7源码进行tcmalloc的编译。运行相同的测试用例,发现内存仍在持续上涨,但是上涨幅度较之前降低,通过pmap打印出该内存地址分布情况,发现之前的小内存块和内存碎片显著减小,说明该工具有一定优化效果,印证了前面提到内存碎片过多的猜测。
但是内存异常增长的问题仍然存在,有点像是tcmalloc的回收不及时或者不回收导致。实际上tcmalloc的内存回收是比较 "reluctant" 的,主要是为了当再次需要内存申请时可以直接使用,减少系统调用次数,提高性能。基于此原因,下来进行手动调用其释放内存接口releasefreememory。发现效果不明显,原因暂时未知(可能确实存在没待释放的空闲内存)。
手动触发tcmalloc的releasefreememory接口
为验证该问题,通过设置cache容量的方式进行。
- 先设置cache的容量为6GB,然后将读请求压起来,使cache的6GB容量填满
- 修改cache的容量为2GB,为快速是内存释放,手动调用tcmalloc的releasefreememory接口,发现没有效果,推测采用tcmalloc之后,内存仍然一直上涨不下跌的原因可能与该接口的有关。
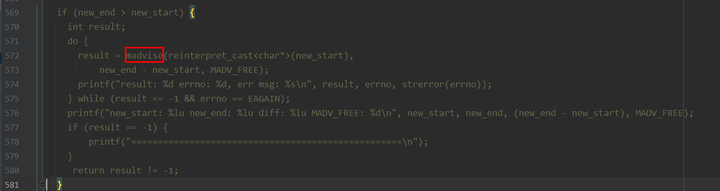
- 在releasefreememory接口内部的多个地方记录日志,然后启动进程再次测试,发现一处报错是在进行系统调用madvise时有出现失败。
- 代码位置:
报错日志信息:

- 通过该处的调用失败,分析代码。发现tcmalloc的内存释放逻辑是“round-robin”,即中间有一个span释放失败,则后续待释放的span被终止,releasefreememory逻辑调用结束。这个就和前面的现象吻合,执行完releasefreememory接口后基本没有效果,发现每次都是在释放了几十MB时,因为该接口的调用失败导致释放逻辑终止。
- 再次分析该系统调用madvise失败原因。通过给内核的该方法打patch,发现其失败原因是因为传入的地址块对应的内存状态是LOCKED状态。导致系统调用失败,报错为非法参数。
- 内存为LOCKED状态,和该状态相关的有代码调用mlock系统方法、系统的ulimit配置。分析相关代码未发现异常点。查询系统ulimit配置,发现max locked memory 为unlimited。修改其配置为16MB,重启Cassandra进程,再次测试,发现内存释放效果显著。
- 继续运行测试,发现内存持续上涨的情况消失。在业务持续存在的情况下,内存会上涨到最高,不再上涨,保持平稳,符合内存计划使用量。业务压力减少甚至停止后,内存出现缓慢下降趋势。
解决&总结
- 引入tcmalloc工具,优化内存管理。比较优秀的内存管理器有Google的tcmalloc和Facebook的jemalloc等
- 修改系统的max locked memory参数配置。
合理分配进程需要使用内存的最大值,并预留一定容量,对于不符合预期增长的内存需要进一步分析。内存相关问题和程序相关性较强。系统的关键配置需谨慎,要评估其影响。同时排查了类似的所有配置。
增加releasefreememory的命令,后端进行调用,优化tcmalloc hold内存不释放问题。不过releasefreememory命令的执行会锁整个pageHeap,可能导致内存分配请求被hang,所以需要小心执行。
后端增加可动态配置tcmalloc_release_rate的参数,来调整tcmalloc将内存交还给操作系统的频率。该值的合理范围是[0-10],0表示永远不交还,值越大,表示交还的频率越高,默认值是1
结语
本文通过分析开发过程中遇到的内存增长问题,使用更优秀的内存管理工具,以及更细粒度的内存监控,更直观的监控数据库运行期间的内存状态,确保数据库平稳高性能运行。