【心电信号】基于matlab ECG滤波【含Matlab源码 484期】
时间:2021-06-18 19:29:52
收藏:0
阅读:0
一、简介
在语音去噪中最常用的方法是谱减法,谱减法是一种发展较早且应用较为成熟的语音去噪算法,该算法利用加性噪声与语音不相关的特点,在假设噪声是统计平稳的前提下,用无语音间隙测算到的噪声频谱估计值取代有语音期间噪声的频谱,与含噪语音频谱相减,从而获得语音频谱的估计值。谱减法具有算法简单、运算量小的特点,便于实现快速处理,往往能够获得较高的输出信噪比,所以被广泛采用。该算法经典形式的不足之处是处理后会产生具有一定节奏性起伏、听上去类似音乐的“音乐噪声”。
转换到频域后,这些峰值听起来就像帧与帧之间频率随机变化的多频音,这种情况在清音段尤其明显,这种由于半波整流引起的“噪声”被称为“音乐噪声”。从根本上,通常导致音乐噪声的原因主要有:
(1)对谱减算法中的负数部分进行了非线性处理
(2)对噪声谱的估计不准
(3)抑制函数(增益函数)具有较大的可变性
1 原理




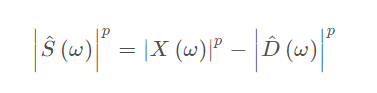
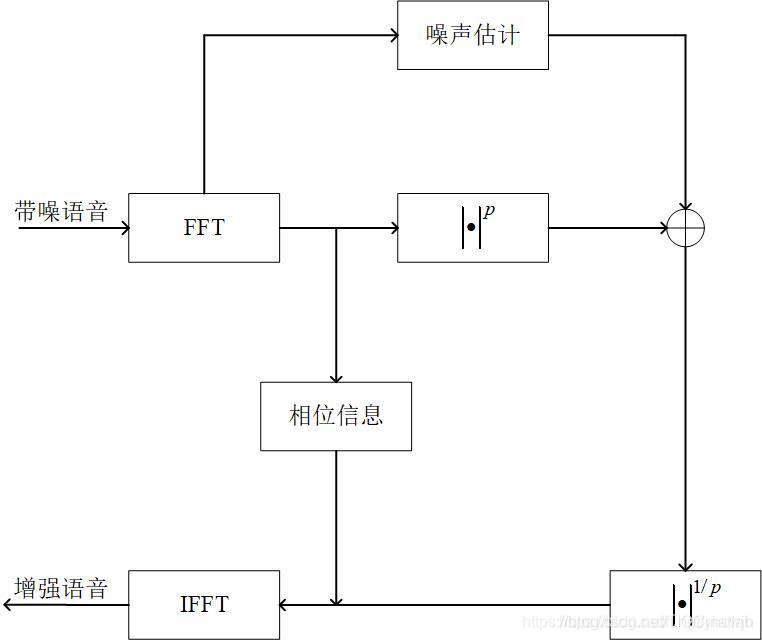
2 流程图
3 谱减法的缺点
1)由于对负值进行半波整流,导致帧频谱的随机频率上出现小的、独立的峰值,变换到时域上面,这些峰值听起来就像帧与帧之间频率随机变化的多颤音,也就是通常所说的“音乐噪声”(Musical Noise)
2)另外,谱减法还存在一个小缺点就是使用带噪语音的相位作为增强后语音的相位,因此产生语音的质量可能比较粗糙,尤其是在低信噪比的条件下,可能会达到被听觉感知的程度,降低语音的质量。
为了更好的理解谱减法语音增强,这里对该算法进行简单仿真,仿真参数设置如下

二、源代码
global hr1 hr2 hr3 hr4 s y fs
clf reset
set(gcf,‘menubar‘,‘none‘)
set(gcf,‘unit‘,‘nor malized‘,‘position‘,[0.1,0.1,0.85,0.85]);
set(gcf,‘defaultuicontrolunits‘,‘normal‘)
set(gcf,‘defaultuicontrolfontsize‘,12);
uicontrol(‘style‘,‘frame‘,‘position‘,[0.64,0.6,0.3,0.3]);
uicontrol(‘style‘,‘text‘,‘string‘,‘选择按钮框‘,‘position‘,[0.65,0.91,0.12,0.03],‘horizontal‘,‘left‘);
hr1=uicontrol(gcf,‘style‘,‘popupmenu‘,‘string‘,‘谱减法|维纳滤波法|最小均方误差估计法‘,‘position‘,[0.65,0.85,0.25,0.03]);
hr2=uicontrol(gcf,‘style‘,‘toggle‘,‘string‘,‘开始/关闭‘,‘position‘,[0.72,0.65,0.15,0.05]);
%uicontrol(gcf,‘style‘,‘)
%htitle1=title(‘原是语音波形‘);
uicontrol(‘style‘,‘text‘,‘string‘,‘原始语音波形‘,‘position‘,[0.25,0.93,0.12,0.03],‘horizontal‘,‘center‘);
h_axes1=axes(‘position‘,[0.05,0.54,0.52,0.38]);
set(h_axes1,‘ylim‘,[-1,1]);
%t=0:pi/50:2*pi;
%y=sin(t);
%plot(t,y);
[y,fs,bit]=wavread(‘C:\Users\lenovo\Desktop\89787488speech_enhancement_GUI\speech enhancement\5.wav‘);
L1=length(y);
t1=1:L1;
plot(t1,y);
uicontrol(‘style‘,‘text‘,‘string‘,‘增强后语音波形‘,‘position‘,[0.25,0.45,0.12,0.03],‘horizontal‘,‘center‘);
h_axes2=axes(‘position‘,[0.05,0.05,0.52,0.38]);
set(h_axes2,‘ylim‘,[-1,1]);
set(hr1,‘callback‘,‘speech_enhancement‘);
set(hr2,‘callback‘,‘speech_enhancement‘);
function [ss,po]=specsubm(s,fs,p)
%SPECSUBM performs speech enhancement using spectral subtraction [SS,PO]=(S,FS,P)
%
% implementation of spectral subtraction algorithm by R Martin (rather slow)
% algorithm parameters: t* in seconds, f* in Hz, k* dimensionless
% 1: tg = smoothing time constant for signal power estimate (0.04): high=reverberant, low=musical
% 2: ta = smoothing time constant for signal power estimate
% used in noise estimation (0.1)
% 3: tw = fft window length (will be rounded up to 2^nw samples)
% 4: tm = length of minimum filter (1.5): high=slow response to noise increase, low=distortion
% 5: to = time constant for oversubtraction factor (0.08)
% 6: fo = oversubtraction corner frequency (800): high=distortion, low=musical
% 7: km = number of minimisation buffers to use (4): high=waste memory, low=noise modulation
% 8: ks = oversampling constant (4)
% 9: kn = noise estimate compensation (1.5)
% 10:kf = subtraction floor (0.02): high=noisy, low=musical
% 11:ko = oversubtraction scale factor (4): high=distortion, low=musical
if nargin<3 po=[0.04 0.1 0.032 1.5 0.08 400 4 4 1.5 0.02 4].‘; else po=p; end
ns=length(s);
ts=1/fs;
ss=zeros(ns,1);
ni=pow2(nextpow2(fs*po(3)/po(8)));
ti=ni/fs;
nw=ni*po(8);
nf=1+floor((ns-nw)/ni);
nm=ceil(fs*po(4)/(ni*po(7)));
win=0.5*hamming(nw+1)/1.08;win(end)=[];
zg=exp(-ti/po(1));
za=exp(-ti/po(2));
zo=exp(-ti/po(5));
px=zeros(1+nw/2,1);
pxn=px;
os=px;
mb=ones(1+nw/2,po(7))*nw/2;
im=0;
osf=po(11)*(1+(0:nw/2).‘*fs/(nw*po(6))).^(-1);
imidx=[13 21]‘;
x2im=zeros(length(imidx),nf);
osim=x2im;
pnim=x2im;
pxnim=x2im;
qim=x2im;
for is=1:nf
idx=(1:nw)+(is-1)*ni;
x=rfft(s(idx).*win);
x2=x.*conj(x);
pxn=za*pxn+(1-za)*x2;
im=rem(im+1,nm);
if im
mb(:,1)=min(mb(:,1),pxn);
else
mb=[pxn,mb(:,1:po(7)-1)];
end
pn=po(9)*min(mb,[],2);
%os= oversubtraction factor
os=zo*os+(1-zo)*(1+osf.*pn./(pn+pxn));
px=zg*px+(1-zg)*x2;
q=max(po(10)*sqrt(pn./x2),1-sqrt(os.*pn./px));
ss(idx)=ss(idx)+irfft(x.*q);
end
三、运行结果



四、备注
版本:2014a
完整代码或代写加1564658423
评论(0)