进程间的通信
每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。
1. 管道
1.1 匿名管道
$ ps auxf | grep mysql
上面命令行里的「|」竖线就是一个管道,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行。
同时,我们得知上面这种管道是没有名字,所以「|」表示的管道称为匿名管道,用完了就销毁。
注意: 匿名管道是只能用于存在父子关系的进程间通信
1.2 命名管道
管道还有另外一个类型是命名管道,也被叫做 FIFO,因为数据是先进先出的传输方式。
在使用命名管道前,先需要通过 mkfifo 命令来创建,并且指定管道名字:
$ mkfifo myPipe
myPipe 就是这个管道的名称,基于 Linux 一切皆文件的理念,所以管道也是以文件的方式存在,我们可以用 ls 看一下,这个文件的类型是 p,也就是 pipe(管道) 的意思:
$ ls -l
prw-r--r-- 1 root root 0 Jun 8 20:08 myPipe
接下来,我们往 myPipe这个管道写入数据:
$ echo "hello" > myPipe // 将数据写进管道
// 停住了 ...
你操作了后,你会发现命令执行后就停在这了,这是因为管道里的内容没有被读取,只有当管道里的数据被读完后,命令才可以正常退出。
于是,我们执行另外一个命令来读取这个管道里的数据:
$ cat < myPipe // 读取管道里的数据
hello
可以看到,管道里的内容被读取出来了,并打印在了终端上,另外一方面,echo 那个命令也正常退出了。
我们可以看出,管道这种通信方式效率低,不适合进程间频繁地交换数据。当然,它的好处,自然就是简单,同时也我们很容易得知管道里的数据已经被另一个进程读取了。
1.3 匿名管道创建
匿名管道的创建,需要通过下面这个系统调用:
int pipe(int fd[2])
这里表示创建一个匿名管道,并返回了两个描述符,一个是管道的读取端描述符 fd[0],另一个是管道的写入端描述符 fd[1]。注意,这个匿名管道是特殊的文件,只存在于内存,不存于文件系统中。
其实,所谓的管道,就是内核里面的一串缓存。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?
我们可以使用
fork创建子进程,创建的子进程会复制父进程的文件描述符,这样就做到了两个进程各有两个「fd[0]与fd[1]」,两个进程就可以通过各自的fd写入和读取同一个管道文件实现跨进程通信了。
2. 消息队列
A进程要给B进程发送消息,A进程把数据放在对应的消息队列后就可以正常返回了,B进程需要的时候再去读取数据就可以了。同理,B进程要给A进程发送消息也是如此。
2.1 创建
消息队列是保存在内核中的消息链表,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。
2.2 销毁
消息队列生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会一直存在。
2.3 缺点
- 消息队列不适合比较大数据的传输,因为在内核中每个消息体都有一个最大长度的限制,同时所有队列所包含的全部消息体的总长度也是有上限。在 $Linux$ 内核中,会有两个宏定义
MSGMAX和MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。 - 消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程。
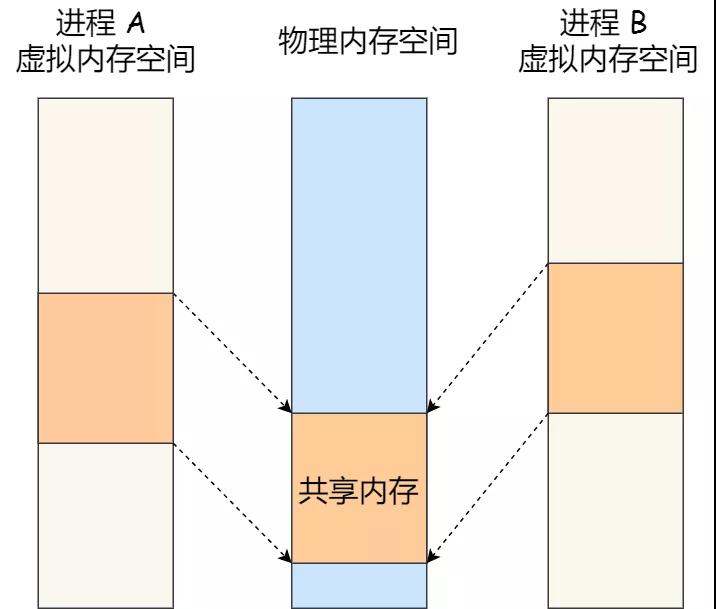
3. 共享内存
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存的方式,就很好的解决了这一问题。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度。
4. 信号量
用了共享内存通信方式,带来新的问题,那就是如果多个进程同时修改同一个共享内存,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。为了防止该问题的发生引入信号量。
信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据。
4.1 实现
进程间的信号量和线程间的信号量实现类似, 信号量表示资源的数量,控制信号量的方式有两种原子操作:
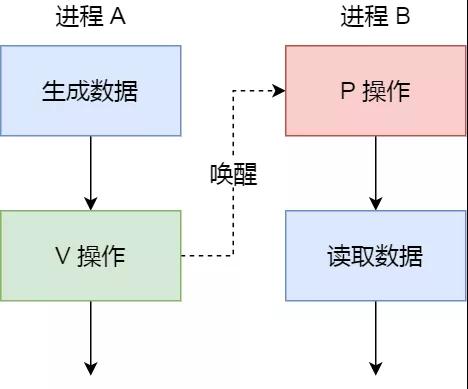
- 一个是P 操作,这个操作会把信号量减去 -1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
- 另一个是V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
4.2 应用
4.2.1 互斥
信号初始化为 1,就代表着是互斥信号量,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
进程A 进程B
P操作 P操作
| |
共享内存 共享内存
| |
V操作 V操作
4.2.2 同步
信号量初始化为 0, 就可以用信号量来实现多进程同步的方式。
5. 信号
上面说的进程间通信,都是常规状态下的工作模式。对于异常情况下的工作模式,就需要用「信号」的方式来通知进程,信号和信号量虽然名字相似但是是完全不同的两个概念。
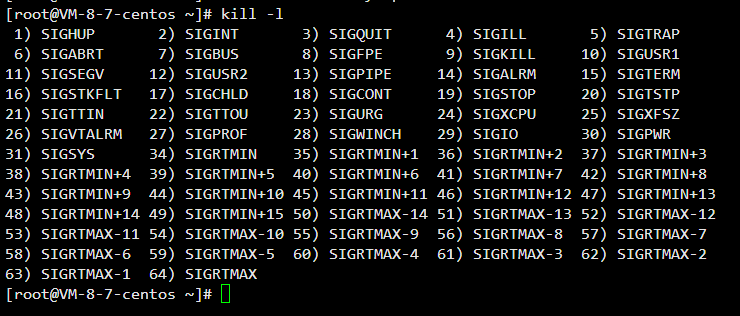
5.1 Linux系统中可以使用kill -l命令查看所有信号。
5.2 信号的来源
运行在 shell 终端的进程,我们可以通过键盘输入某些组合键的时候,给进程发送信号。例如
Ctrl+Z产生SIGINT信号,表示终止该进程Ctrl+Z产生SIGTSTP信号,表示停止该进程,但还未结束
如果进程在后台运行,可以通过 kill 命令的方式给进程发送信号,但前提需要知道运行中的进程 PID 号,例如:
kill -9 1050,表示给PID为1050的进程发送SIGKILL信号,用来立即结束该进程
所以,信号事件的来源主要有硬件来源(如键盘
Cltr+C)和软件来源(如kill命令)。
5.3 信号的处理
信号是进程间通信机制中唯一的异步通信机制,因为可以在任何时候发送信号给某一进程,一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式。
-
执行默认操作。Linux 对每种信号都规定了默认操作,例如,上面列表中的 SIGTERM 信号,就是终止进程的意思。Core 的意思是 Core Dump,也即终止进程后,通过 Core Dump 将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。
-
捕捉信号。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
-
忽略信号。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
6. socket
前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
实际上,Socket 通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信。
6.1 socket同一主机间进程通信
SOCK_STREAM 式本地套接字的通信双方均需要具有本地地址,其中服务器端的本地地址需要明确指定,指定方法是使用 struct sockaddr_un 类型的变量。
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* 路径名 */
};
这里面有一个很关键的东西,socket进程通信命名方式有两种。
-
一是普通的命名,
socket会根据此命名创建一个同名的socket文件,客户端连接的时候通过读取该socket文件连接到socket服务端。这种方式的弊端是服务端必须对socket文件的路径具备写权限,客户端必须知道socket文件路径,且必须对该路径有读权限。 -
另外一种命名方式是抽象命名空间,这种方式不需要创建
socket文件,只需要命名一个全局名字,即可让客户端根据此名字进行连接。后者的实现过程与前者的差别是,后者在对地址结构成员sun_path数组赋值的时候,必须把第一个字节置0,即sun_path[0] = 0,下面用代码说明:
第一种方式:
// name the server socket
server_addr.sun_family = AF_UNIX;
strcpy(server_addr.sun_path,"/tmp/UNIX.domain");
server_len = sizeof(struct sockaddr_un);
client_len = server_len;
第二种方式:
#define SERVER_NAME @socket_server
// name the socket
server_addr.sun_family = AF_UNIX;
strcpy(server_addr.sun_path, SERVER_NAME);
server_addr.sun_path[0]=0;
// server_len = sizeof(server_addr);
server_len = strlen(SERVER_NAME) + offsetof(struct sockaddr_un, sun_path);
其中,offsetof函数在#include <stddef.h>头文件中定义。因第二种方式的首字节置0,我们可以在命名字符串SERVER_NAME前添加一个占位字符串,例如:
#define SERVER_NAME @socket_server
前面的@符号就表示占位符,不算为实际名称。
提示:客户端连接服务器的时候,必须与服务端的命名方式相同,即如果服务端是普通命名方式,客户端的地址也必须是普通命名方式;如果服务端是抽象命名方式,客户端的地址也必须是抽象命名方式。
6.1.1 服务端
//s_unix.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#define UNIX_DOMAIN "/tmp/UNIX.domain"
int main(void)
{
socklen_t clt_addr_len;
int listen_fd;
int com_fd;
int ret;
int i;
static char recv_buf[1024];
int len;
struct sockaddr_un clt_addr;
struct sockaddr_un srv_addr;
listen_fd=socket(PF_UNIX,SOCK_STREAM,0);
if(listen_fd<0)
{
perror("cannot create communication socket");
return 1;
}
// set server addr_param
srv_addr.sun_family=AF_UNIX;
strncpy(srv_addr.sun_path,UNIX_DOMAIN,sizeof(srv_addr.sun_path)-1);
unlink(UNIX_DOMAIN);
// bind sockfd & addr
ret=bind(listen_fd,(struct sockaddr*)&srv_addr,sizeof(srv_addr));
if(ret==-1)
{
perror("cannot bind server socket");
close(listen_fd);
unlink(UNIX_DOMAIN);
return 1;
}
// listen sockfd
ret=listen(listen_fd,1);
if(ret==-1)
{
perror("cannot listen the client connect request");
close(listen_fd);
unlink(UNIX_DOMAIN);
return 1;
}
// have connect request use accept
len=sizeof(clt_addr);
com_fd=accept(listen_fd,(struct sockaddr*)&clt_addr,&len);
if(com_fd<0)
{
perror("cannot accept client connect request");
close(listen_fd);
unlink(UNIX_DOMAIN);
return 1;
}
// read and printf sent client info
printf("/n=====info=====/n");
for(i=0;i<4;i++)
{
memset(recv_buf,0,1024);
int num=read(com_fd,recv_buf,sizeof(recv_buf));
printf("Message from client (%d)) :%s/n",num,recv_buf);
}
close(com_fd);
close(listen_fd);
unlink(UNIX_DOMAIN);
return 0;
}
6.1.2 客户端
//c_unix.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#define UNIX_DOMAIN "/tmp/UNIX.domain"
int main(void)
{
int connect_fd;
int ret;
char snd_buf[1024];
int i;
static struct sockaddr_un srv_addr;
// creat unix socket
connect_fd=socket(PF_UNIX,SOCK_STREAM,0);
if(connect_fd<0)
{
perror("cannot create communication socket");
return 1;
}
srv_addr.sun_family=AF_UNIX;
strcpy(srv_addr.sun_path,UNIX_DOMAIN);
// connect server
ret=connect(connect_fd,(struct sockaddr*)&srv_addr,sizeof(srv_addr));
if(ret==-1)
{
perror("cannot connect to the server");
close(connect_fd);
return 1;
}
memset(snd_buf,0,1024);
strcpy(snd_buf,"message from client");
// send info server
for(i=0;i<4;i++)
write(connect_fd,snd_buf,sizeof(snd_buf));
close(connect_fd);
return 0;
}
6.2 socket不同主机间进程通信
SOCK_STREAM 式非本地套接字的通信双方均需要具有IP和端口号,其中服务器端的本地地址需要明确指定,指定方法是使用 struct sockaddr_in 类型的变量。
/* Structure describing an Internet socket address. */
struct sockaddr_in
{
__SOCKADDR_COMMON (sin_);
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr‘. */
unsigned char sin_zero[sizeof (struct sockaddr) -
__SOCKADDR_COMMON_SIZE -
sizeof (in_port_t) -
sizeof (struct in_addr)];
};
参考连接
-
操作系统导论