Java集合框架-HashMap
目录
HashMap
1 HashMap引入
Map接口专门处理键值映射数据的存储,可以根据键实现对值的操作。
最常用的实现类是HashMap。
2 HashMa数据结构
1、HashMap概述
HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射。此类不保证映射的顺序,假定哈希函数将元素适当的分布在各桶之间,可为基本操作(get和put)提供稳定的性能。
2、HashMap在JDK1.8以前数据结构和存储原理
链表散列
通过数组和链表结合在一起使用,就叫做链表散列。这其实就是hashmap存储的原理图。

![]() ?
?
HashMap的数据结构和存储原理
HashMap内部有一个entry的内部类,其中有四个属性,我们要存储一个值,则需要一个key和一个value,存到map中就会先将key和value保存在这个Entry类创建的对象中。

![]() ?
?
通过entry对象中的hash值来确定将该对象存放在数组中的哪个位置上,如果在这个位置上还有其他元素,则通过链表来存储这个元素。

![]() ?
?
Hash存放元素的过程
- 通过key、value封装成一个entry对象,然后通过key的值来计算该entry的hash值,通过entry的hash值和数组的长度length来计算出entry放在数组中的哪个位置上面,
- 每次存放都是将entry放在第一个位置。在这个过程中,就是通过hash值来确定将该对象存放在数组中的哪个位置上。
3、JDK1.8后HashMap的数据结构

![]() ?
?
上图展示了HashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树的引入是为了提高效率。
4、HashMap的属性
HashMap的实例有两个参数影响其性能。
初始容量:哈希表中桶的数量
加载因子:哈希表在其容量自动增加之前可以达到多满,的一种尺度
当哈希表中条目数超出了当前容量*加载因子(其实就是HashMap的实际容量)时,则对该哈希表进行rehash操作,将哈希表扩充至两倍的桶数。
Java中默认初始容量为16,加载因子为0.75。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 static final float DEFAULT_LOAD_FACTOR = 0.75f;
capacity译为容量代表的数组的容量,也就是数组的长度,同时也是HashMap中桶的个数。默认值是16。
一般第一次扩容时会扩容到64,之后好像是2倍。总之,容量都是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
通过一张HashMap的数据结构图来分析:

![]() ?
?
3 HashMap的源码分析
1、HashMap的层次关系与继承结构
【HashMap继承结构】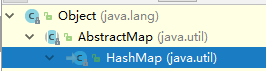
![]() ?
?
【实现接口】
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { }
- Map<K,V>:在AbstractMap抽象类中已经实现过的接口,这里又实现,实际上是多余的。但每个集合都有这样的错误,也没过大影响
- Cloneable:能够使用Clone()方法,在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象。
- Serializable:能够使之序列化,即可以将HashMap对象保存至本地,之后可以恢复状态。
2、HashMap类的属性
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { // 序列号 private static final long serialVersionUID = 362498820763181265L; // 默认的初始容量是16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; // 默认的填充因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 当桶(bucket)上的结点数大于这个值时会转成红黑树 static final int TREEIFY_THRESHOLD = 8; // 当桶(bucket)上的结点数小于这个值时树转链表 static final int UNTREEIFY_THRESHOLD = 6; // 桶中结构转化为红黑树对应的table的最小大小 static final int MIN_TREEIFY_CAPACITY = 64; // 存储元素的数组,总是2的幂次倍 transient Node<k,v>[] table; // 存放具体元素的集 transient Set<map.entry<k,v>> entrySet; // 存放元素的个数,注意这个不等于数组的长度。 transient int size; // 每次扩容和更改map结构的计数器 transient int modCount; // 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容 int threshold; // 填充因子 final float loadFactor; }
3、HashMap的构造方法
【HashMap()】:
//看上面的注释就已经知道,DEFAULT_INITIAL_CAPACITY=16,DEFAULT_LOAD_FACTOR=0.75 //初始化容量:也就是初始化数组的大小 //加载因子:数组上的存放数据疏密程度。 public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }
【HashMap(int)】
public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }
【HashMap(int,float)】
public HashMap(int initialCapacity, float loadFactor) { // 初始容量不能小于0,否则报错 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); // 初始容量不能大于最大值,否则为最大值 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // 填充因子不能小于或等于0,不能为非数字 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); // 初始化填充因子 this.loadFactor = loadFactor; // 初始化threshold大小 this.threshold = tableSizeFor(initialCapacity); }
【HashMap(Map<? extends K, ? extends V> m)】
public HashMap(Map<? extends K, ? extends V> m) { // 初始化填充因子 this.loadFactor = DEFAULT_LOAD_FACTOR; // 将m中的所有元素添加至HashMap中 putMapEntries(m, false); }
4、常用方法
【put(K key,V value)】
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
【putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)】
HashMap并没有直接提供putVal接口给用户调用,而是提供的put函数,而put函数就是通过putVal来插入元素的。
【get(Object key)】
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
【getNode(int hash,Pbject key)】
HashMap并没有直接提供getNode接口给用户调用,而是提供的get函数,而get函数就是通过getNode来取得元素的。
【resize方法】
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
在resize前和resize后的元素布局如下:

![]() ?
?
4 总结
1. 要知道hashMap在JDK1.8以前是一个链表散列这样一个数据结构,而在JDK1.8以后是一个数组加链表加红黑树的数据结构。
2. 通过源码的学习,hashMap是一个能快速通过key获取到value值得一个集合,原因是内部使用的是hash查找值得方法。
迭代器
所有实现了Collection接口的容器类都有一个iterator方法用以返回一个实现Iterator接口的对象
Iterator对象称作为迭代器,用以方便的对容器内元素的遍历操作,Iterator接口定义了如下方法:
- boolean hashNext();//判断是否有元素没有被遍历
- Object next();//返回游标当前位置的元素并将游标移动到下一个位置
- void remove();//删除游标左边的元素,在执行完next之后该操作只能执行一次
方法1:通过迭代器Iterator实现遍历
- 获取Iterator :Collection 接口的iterator()方法
- Iterator的方法:
- boolean hasNext(): 判断是否存在另一个可访问的元素
- Object next(): 返回要访问的下一个元素
Set keys=dogMap.keySet(); //取出所有key的集合 Iterator it=keys.iterator(); //获取Iterator对象 while(it.hasNext()){ String key=(String)it.next(); //取出key Dog dog=(Dog)dogMap.get(key); //根据key取出对应的值 System.out.println(key+"\t"+dog.getStrain()); }
方法2:增强for循环
for(元素类型t 元素变量x : 数组或集合对象){ 引用了x的java语句 }
泛型
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
通过泛型 , JDK1.5使用泛型改写了集合框架中的所有接口和类

![]() ?
?

![]() ?
?
? 通配符: < ? >
Collections工具类
Java提供了一个操作Set、List和Map等集合的工具类:Collections,该工具类提供了大量方法对集合进行排序、查询和修改等操作,还提供了将集合对象置为不可变、对集合对象实现同步控制等方法。
这个类不需要创建对象,内部提供的都是静态方法。
1、Collectios概述

![]() ?
?
2、排序操作
static void reverse(List<?> list): 反转列表中元素的顺序。 static void shuffle(List<?> list) : 对List集合元素进行随机排序。 static void sort(List<T> list) 根据元素的自然顺序 对指定列表按升序进行排序 static <T> void sort(List<T> list, Comparator<? super T> c) : 根据指定比较器产生的顺序对指定列表进行排序。 static void swap(List<?> list, int i, int j) 在指定List的指定位置i,j处交换元素。 static void rotate(List<?> list, int distance) 当distance为正数时,将List集合的后distance个元素“整体”移到前面;当distance为 负数时,将list集合的前distance个元素“整体”移到后边。该方法不会改变集合的长度。
3、查找、替换操作
static <T> int binarySearch(List<? extends Comparable<? super T>>list, T key) 使用二分搜索法搜索指定列表,以获得指定对象在List集合中的索引。 注意:此前必须保证List集合中的元素已经处于有序状态。 static Object max(Collection coll) 根据元素的自然顺序,返回给定collection 的最大元素。 static Object max(Collection coll,Comparator comp): 根据指定比较器产生的顺序,返回给定 collection 的最大元素。 static Object min(Collection coll): 根据元素的自然顺序,返回给定collection 的最小元素。 static Object min(Collection coll,Comparator comp): 根据指定比较器产生的顺序,返回给定 collection 的最小元素。 static <T> void fill(List<? super T> list, T obj) : 使用指定元素替换指定列表中的所有元素。 static int frequency(Collection<?> c, Object o) 返回指定 collection 中等于指定对象的出现次数。 tatic int indexOfSubList(List<?> source, List<?> target) : 返回指定源列表中第一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1。 static int lastIndexOfSubList(List<?> source, List<?> target) 返回指定源列表中最后一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1。 static <T> boolean replaceAll(List<T> list, T oldVal, T newVal) 使用一个新值替换List对象的所有旧值oldVal
4、同步控制
static <T> Collection<T> synchronizedCollection(Collection<T> c) 返回指定 collection 支持的同步(线程安全的)collection。 static <T> List<T> synchronizedList(List<T> list) 返回指定列表支持的同步(线程安全的)列表。 static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射。 static <T> Set<T> synchronizedSet(Set<T> s) 返回指定 set 支持的同步(线程安全的)set。
Collectons提供了多个synchronizedXxx()方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
5、Collesction设置不可变集合
emptyXxx()
返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
ingletonXxx():
返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
unmodifiableXxx():
返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map。
Vevtor和Stack
锁机制:对象锁、方法锁、类锁
对象锁就是方法锁:就是在一个类中的方法上加上synchronized关键字,这就是给这个方法加锁了。
类锁:锁的是整个类,当有多个线程来声明这个类的对象的时候将会被阻塞,直到拥有这个类锁的对象被销毁或者主动释放了类锁。这个时候在被阻塞住的线程被挑选出一个占有该类锁,声明该类的对象。其他线程继续被阻塞住。例如:在类A上有关键字synchronized,那么就是给类A加了类锁,线程1第一个声明此类的实例,则线程1拿到了该类锁,线程2在想声明类A的对象,就会被阻塞。
现在使用的是方法锁。
1 Vector
1、Vector概述

![]() ?
?
1. Vector是一个可变化长度的数组
2. Vector增加长度通过的是capacity和capacityIncrement这两个变量,目前还不知道如何实现自动扩增的,等会源码分析
3. Vector也可以获得iterator和listIterator这两个迭代器,并且他们发生的是fail-fast,而不是failsafe,注意这里,不要觉得这个vector是线程安全就搞错了
4. Vector是一个线程安全的类,如果使用需要线程安全就使用Vector,如果不需要,就使用arrayList
5. Vector和ArrayList很类似,就少许的不一样,从它继承的类和实现的接口来看,跟arrayList一模一样。
2、Vector源码分析
Vector的继承关系和层次结构和ArrayList中的一模一样
构造方法作用:
1. 初始化存储元素的容器,也就是数组,elementData,
2. 初始化capacityIncrement的大小,默认是0,这个的作用就是扩展数组的时候,增长的大小,为0则每次扩展2倍
【Vector():空构造】
【Vector(int)】
【ector(int,int)】
【Vector(Collection<? extends E> c)】
3、核心方法
这个就是在每个方法上比arrayList多了一个synchronized,其他都一样。
2 Stack
Vector的子类Stack,我们学过数据结构都知道,这个就是栈的意思。那么该类就是跟栈的用法一样
class Stack<E> extends 1 Vector<E> {}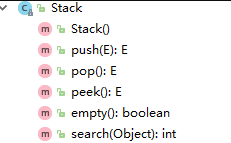
![]() ?
?
3 总结Vector和Stack
【Vector总结】
1. Vector线程安全是因为它的方法都加了synchronized关键字
2. Vector的本质是一个数组,特点能是能够自动扩增,扩增的方式跟capacityIncrement的值有关
3. 它也会fail-fast,还有一个fail-safe两个的区别在下面的list总结中会讲到。
【Stack的总结】
1. 对栈的一些操作,先进后出
2. 底层也是用数组实现的,因为继承了Vector
3. 也是线程安全的