Flink Forward #Asia2020 流批一体及数仓资料整理
阿里云实时计算负责人 - 王峰(莫问)/ FFA_2020-Flink as a Unified Engine - Now and Next-V4
2020年Flink

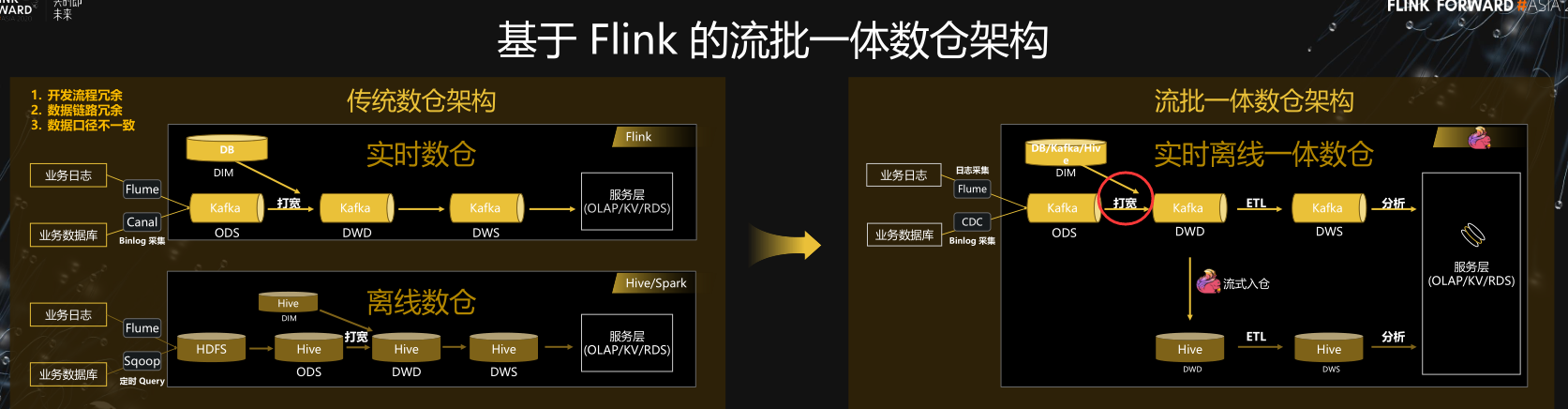
基于Flink 的流批一体数仓
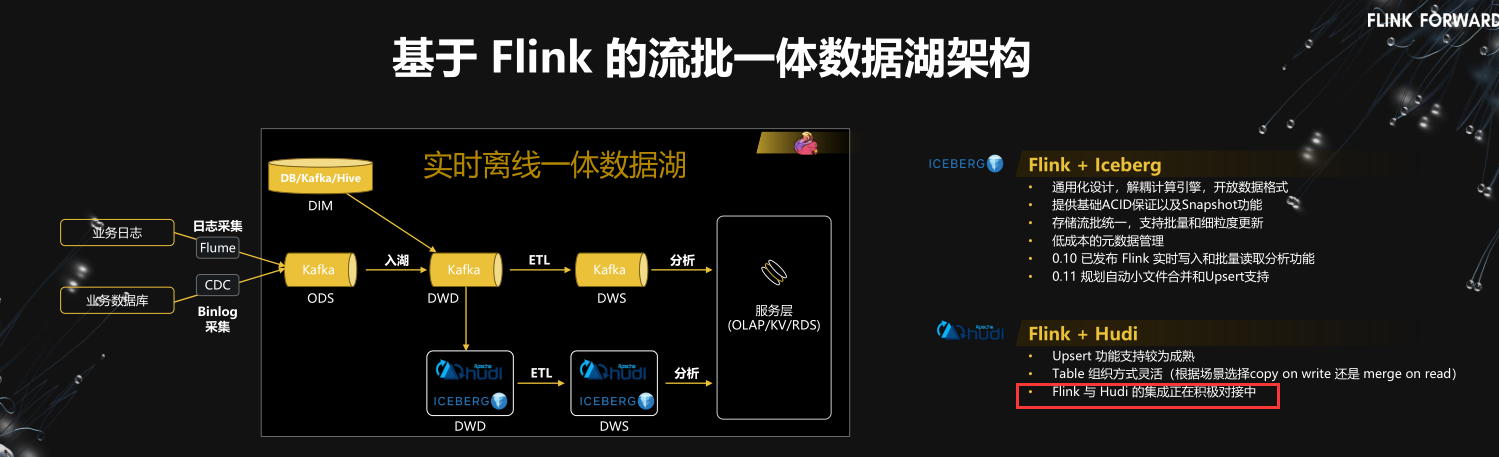
基于Flink流批一体数据湖架构
PyFlink
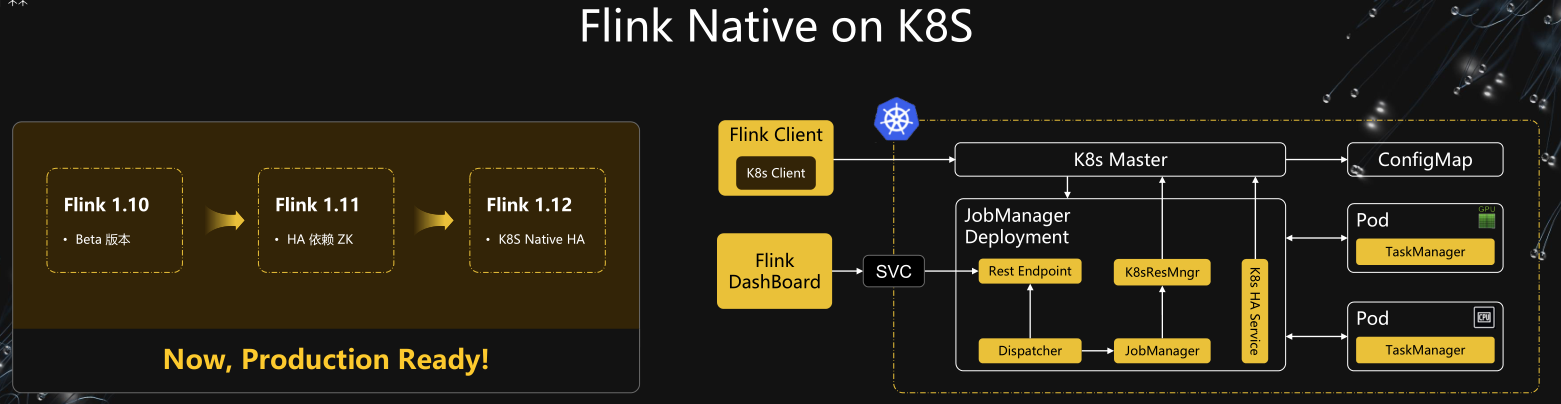
Flink Native on K8S
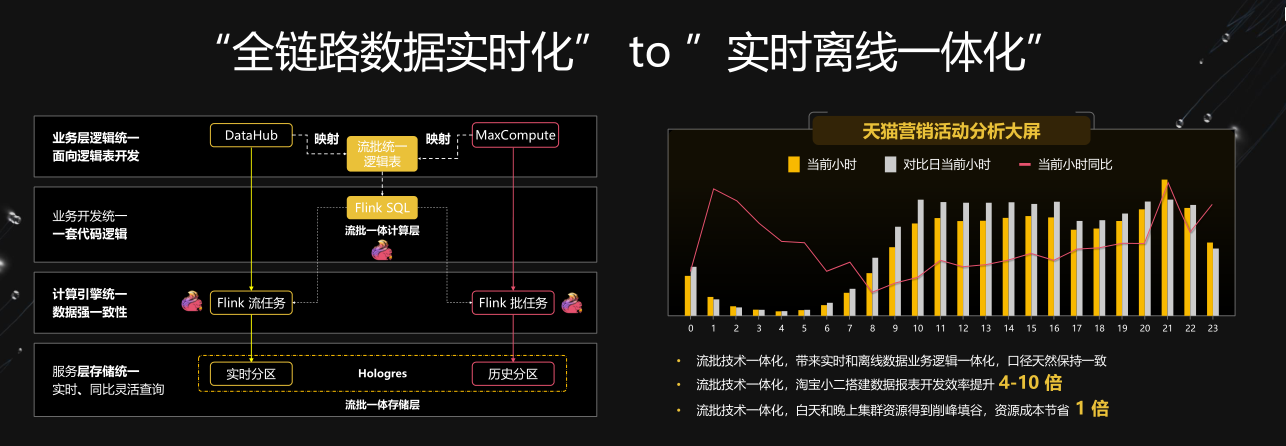
双链路数据实时化
Flag:
- 流批一体Source API、Sink API
- K8S Native HA
- Sql CDC 原生支持
- 开源实时数仓:ClickHouse
- 阿里:Hologres
美团
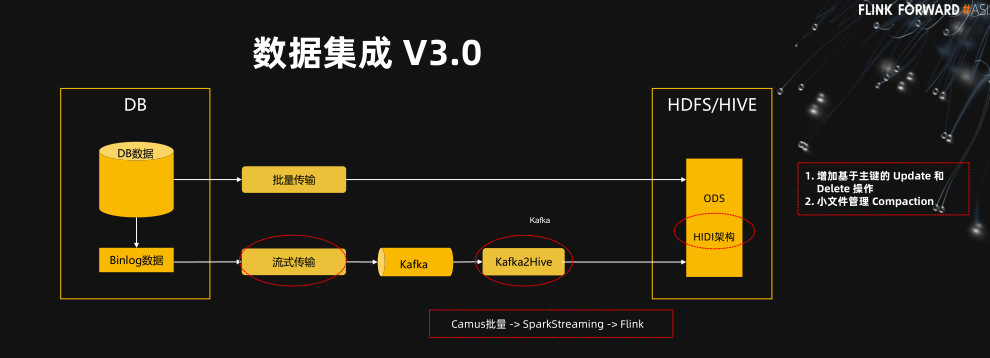
数据集成
组件对比

Flag:
- HIDI、Hudi、Iceberg
- Doris
有赞
Flink on K8S VS Yarn 优势

Flink on K8S 痛点问题

Flag:
- Native on K8S
知乎
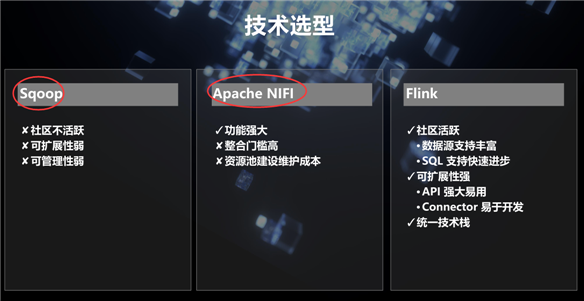
技术选型
Flag:
- ETL
- TiDB
B站
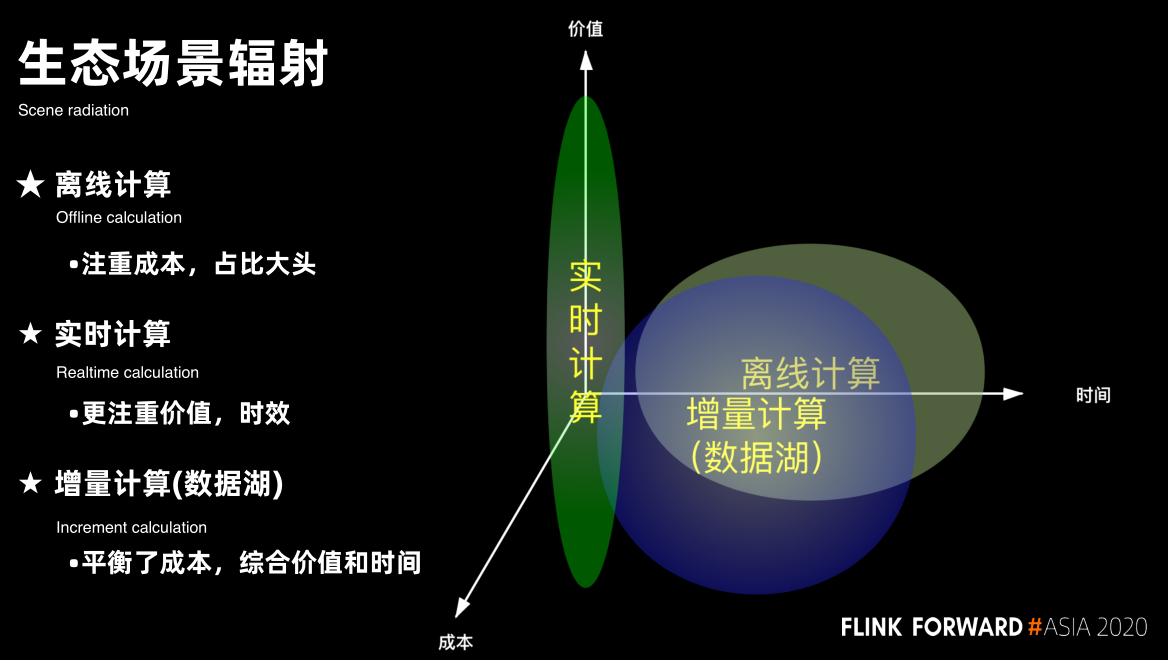
生态场景
Flag:
- ETL
- ClickHouse
- AIFlow
阿里云开放平台
Flink on Zeppelin

作业调度

Flag:
- Flink + Zepplin + Airflow
阿里:Flink在线机器学习
架构
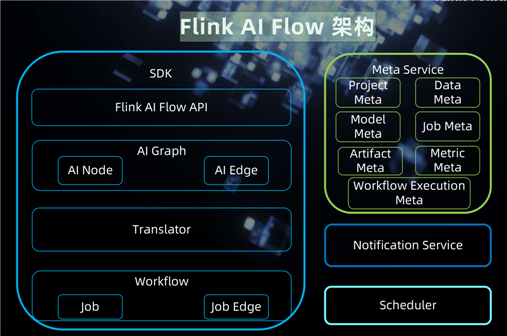
开源

Flag :
- Flink AI Flow 开源
湖仓一体 - 融合趋势下基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
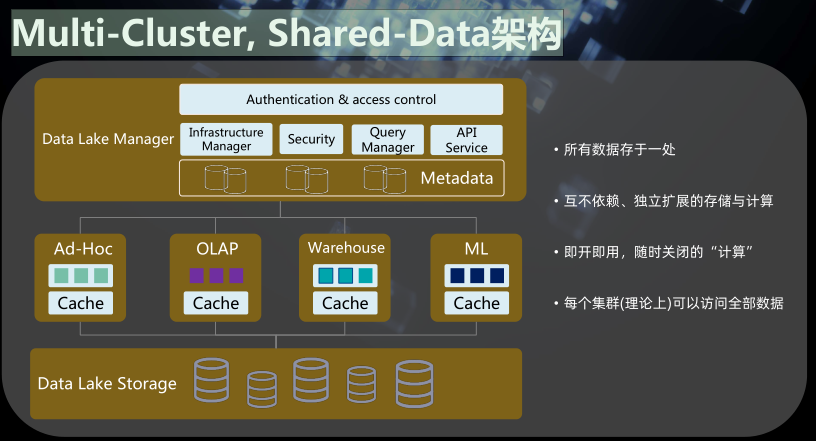
Multi-Cluster, Shared-Data架构
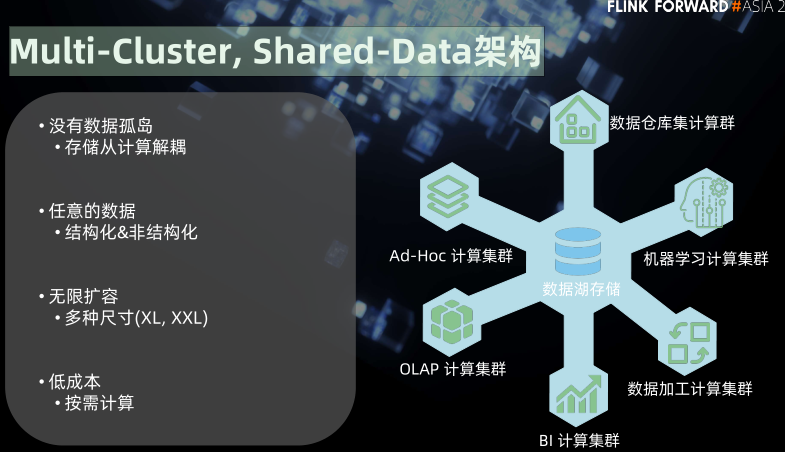
Multi-Cluster, Shared-Data架构2
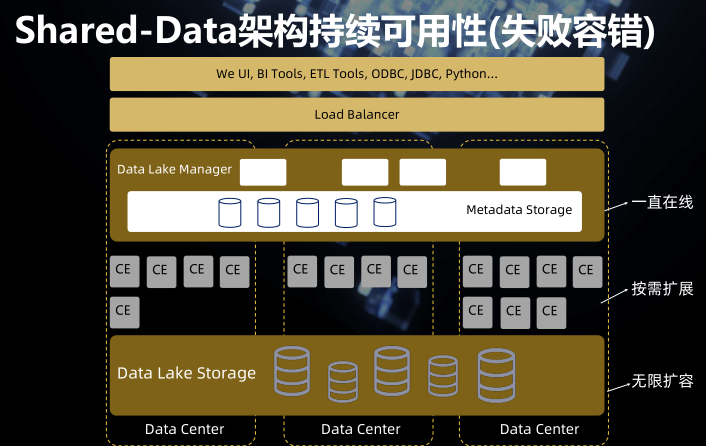
失败容错
贝壳
数仓架构
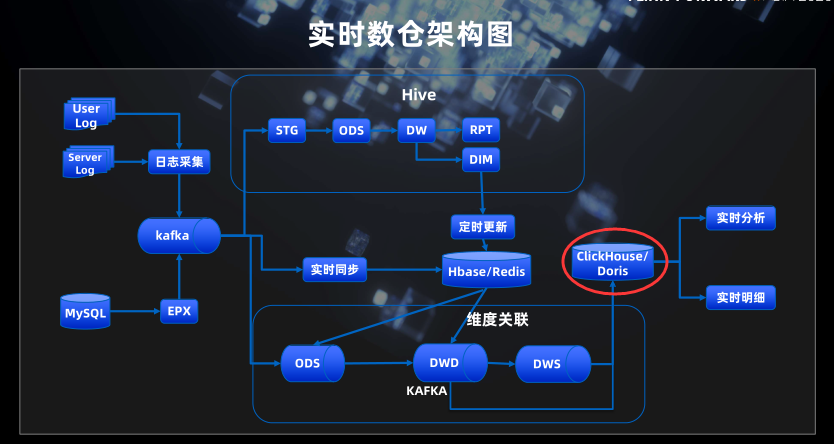
Flag:
- clickhouse
- doris
顺丰
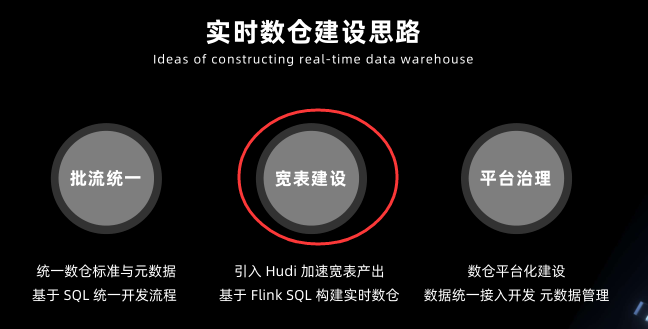
实时数仓建设思路
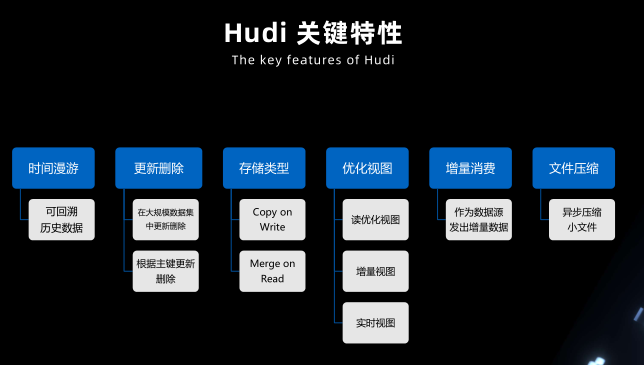
Hudi 关键特性
加速宽表
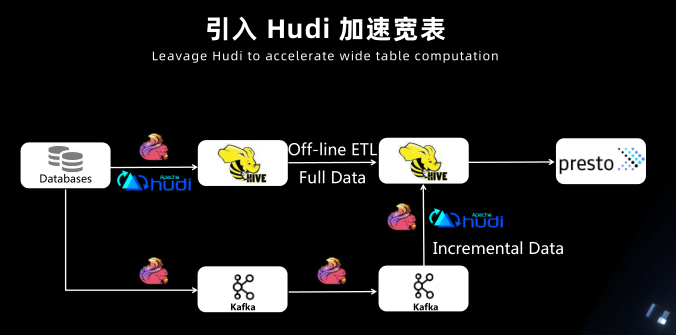
实时数仓宽表

Flag:
- Hudi 加速宽表
- clickhouse
腾讯实时数仓
痛点总结

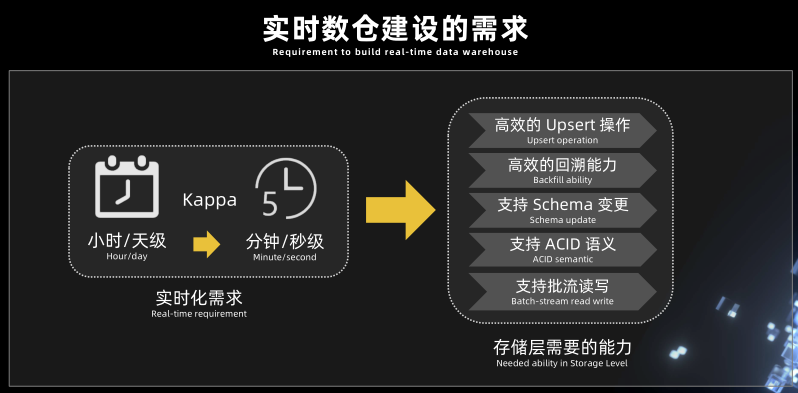
实时数仓建设的需求
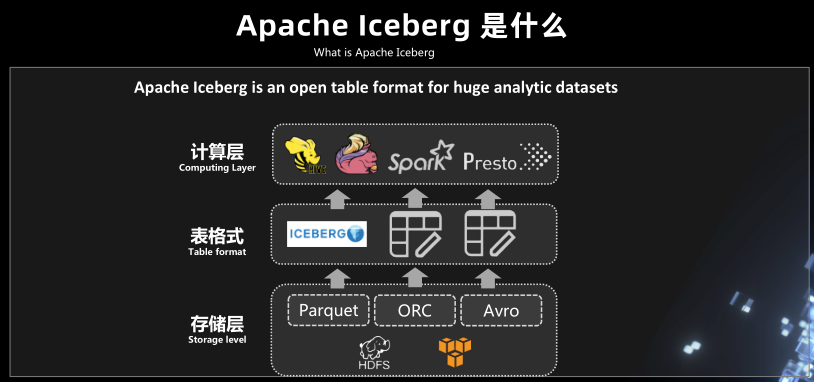
Apache Iceberg 是什么
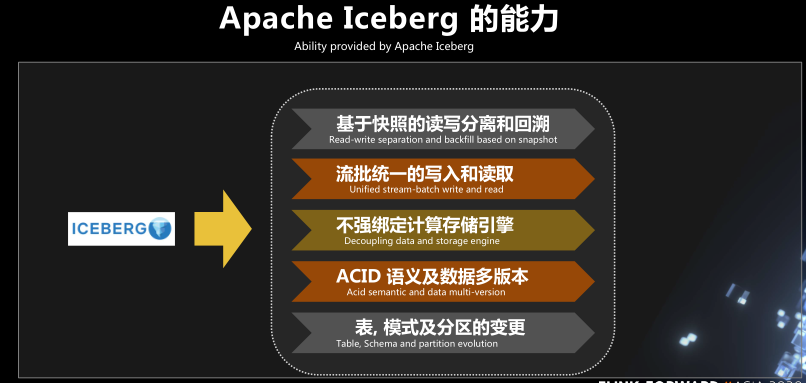
Apache Iceberg 的能力
实时数仓-数据湖分析系统
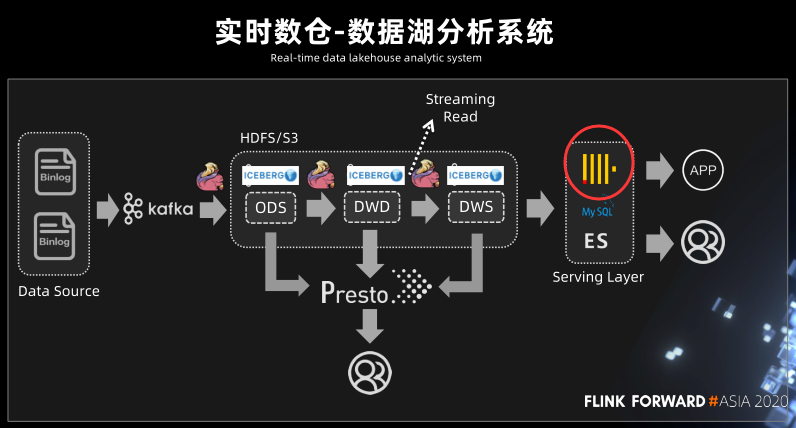
实时数仓-数据湖分析系统

Flag:
- Iceberg
- clickhouse
腾讯看点基于Flink构建万亿数据量下的实时数仓及实时查询系统
实时数仓
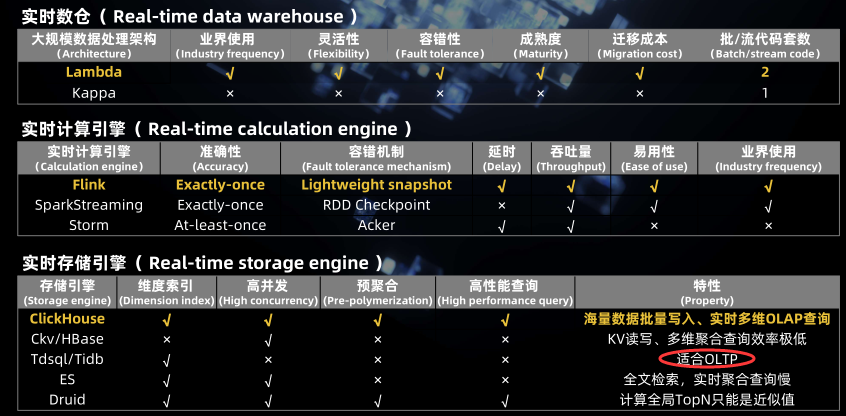
基于 Flink SQL 构建流批一体的 ETL 数据集成
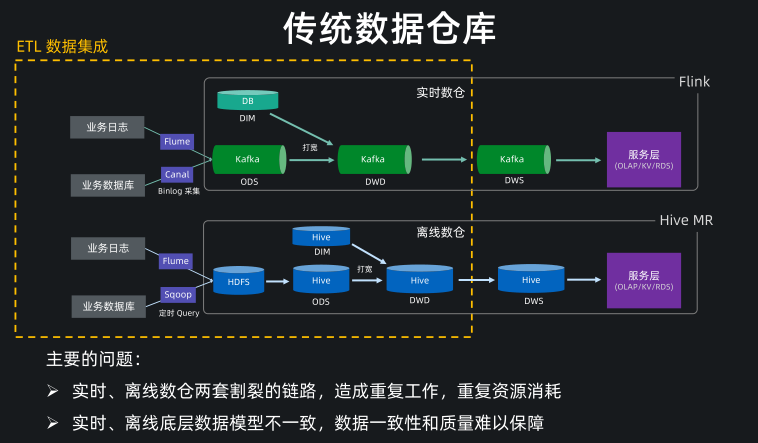
传统数仓
-
传统的数据仓库,实时和离线数仓是比较割裂的两套链路,比如实时链路通过 Flume和 Canal 实时同步日志和数据库数据到 Kafka 中,然后在 Kafka 中做数据清理和打宽。
-
离线链路通过 Flume 和 Sqoop 定期同步日志和数据库数据到 HDFS 和 Hive。然后在 Hive 里做数据清理和打宽。
-
这里我们主要关注的是数仓的前半段的构建,也就是到 ODS、DWD 层,我们把这一块看成是广义的 ETL 数据集成的范围。
-
那么在这一块,传统的架构主要存在的问题就是这种割裂的数仓搭建这会造成很多重复工作,重复的资源消耗,并且实时、离线底层数据模型不一致,会导致数据一致性和质量难以保障。
-
同时两个链路的数据是孤立的,数据没有实现打通和共享。
流批一体的 ETL 数据集成
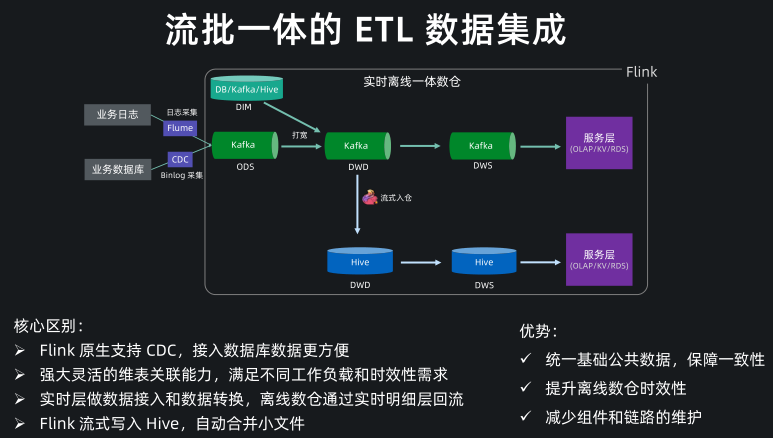
基于 Flink SQL 我们现在可以方便地构建流批一体的 ETL 数据集成,与传统数仓架构的核心区别主要是这几点:
- Flink SQL 原生支持了 CDC 所以现在可以方便地同步数据库数据,不管是直连数据库,还是对接常见的 CDC工具。
- Flink SQL 在最近的版本中持续强化了维表 join 的能力,不仅可以实时关联数据库中的维表数据,现在还能关联 Hive 和 Kafka 中的维表数据,能灵活满足不同工作负载和时效性的需求。
- 基于 Flink 强大的流式 ETL 的能力,我们可以统一在实时层做数据接入和数据转换,然后将明细层的数据回流到离线数仓中。
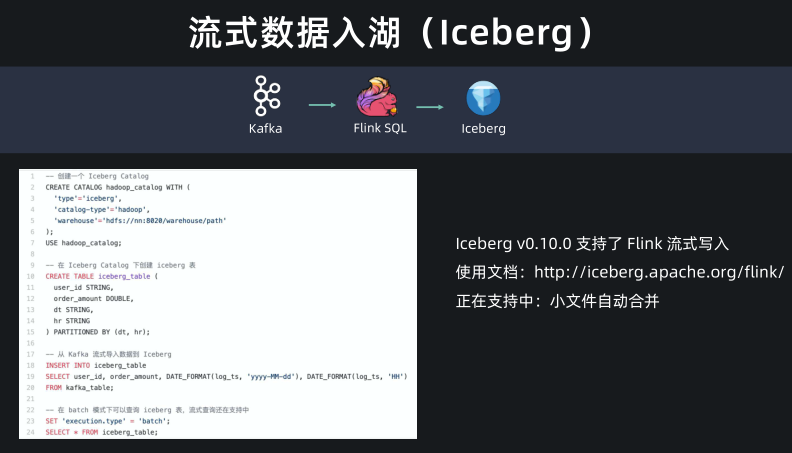
- 现在 Flink 流式写入 Hive,已经支持了自动合并小文件的功能,解决了小文件的痛苦。
所以基于流批一体的架构,我们能获得的收益:
- 统一了基础公共数据
- 保障了流批结果的一致性
- 提升了离线数仓的时效性
- 减少了组件和链路的维护成本
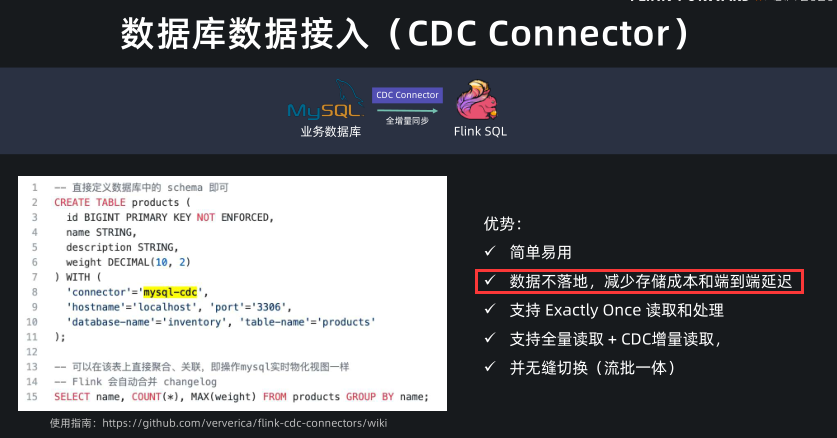
CDC Connector
数据入 OLAP

流式数据入湖(Iceberg)
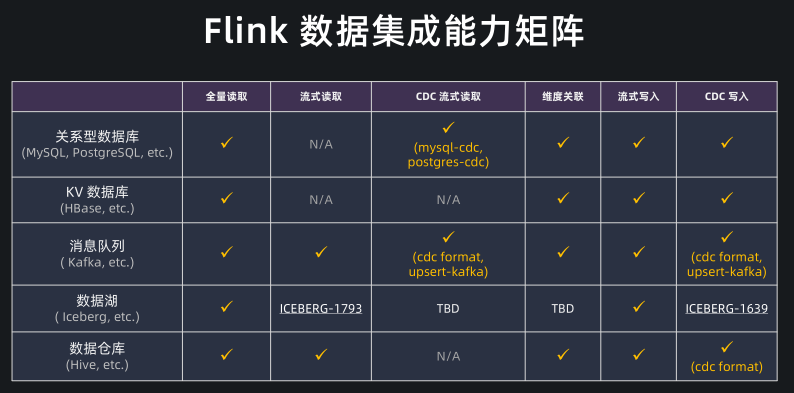
Flink 数据集成能力矩阵
Flag:
- 打宽
- clickhouse
参考总结及规划:
1、以实时数仓、K8S、PyFlink 等场景的分布;
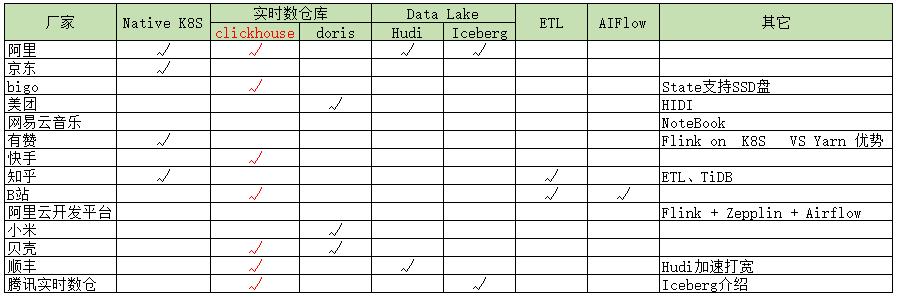
2、Flink+ClickHouse
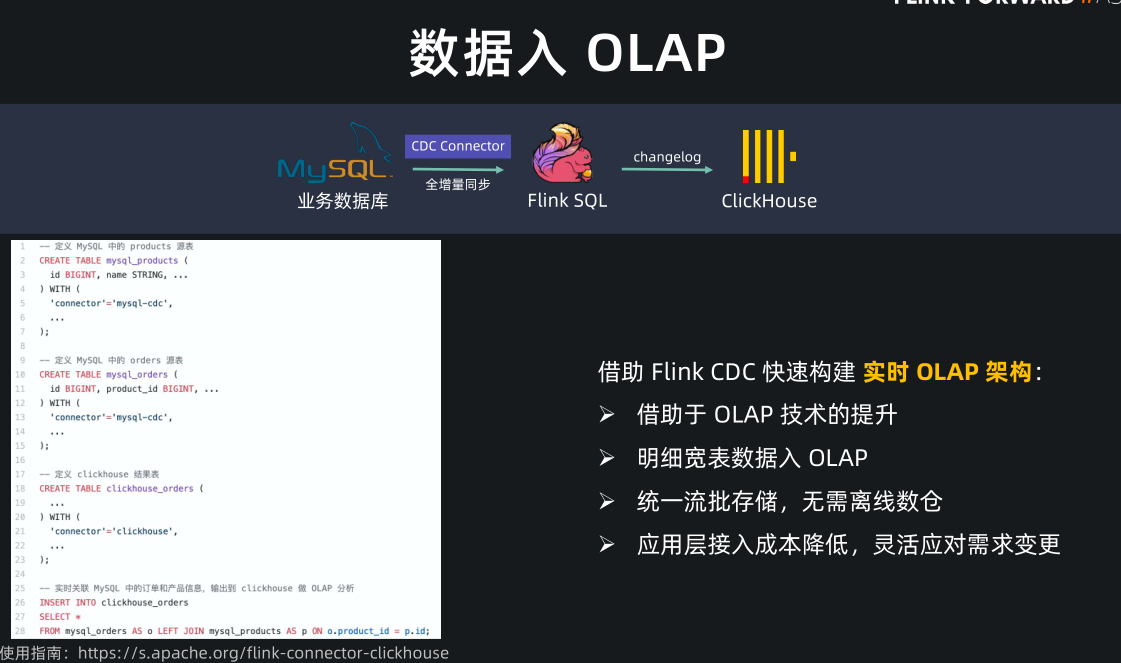
MySQL CDC connector 非常受用户的欢迎,尤其是结合 OLAP 引擎,可以快速构建实时 OLAP 架构。实时 OLAP 架构的一个特点就是将数据库数据同步到 OLAP 中做即席查询,这样就无需离线数仓了。
-
现在很多公司都在用 Flink+ClickHouse 来快速构建实时 OLAP 架构。
-
我们只需要在 Flink 中定义一个 mysql-cdc source,一个 ClickHouse sink,然后提交一个 insert into query 就完成了从 MySQL 到 ClickHouse 的实时同步工作,非常方便。
-
而且,ClickHouse 有一个痛点就是 join 比较慢,所以一般我们会把 MySQL 数据打成一张大的明细宽表数据,再写入 ClickHouse。这个在 Flink 中一个 join 操作就完成了。而在 Flink 提供 MySQL CDC connector 之前,要在全量+增量的实时同步过程中做 join 是非常麻烦的。
- Flag :Sqlserver-cdc source?
3、实时数仓相关技术组件对比
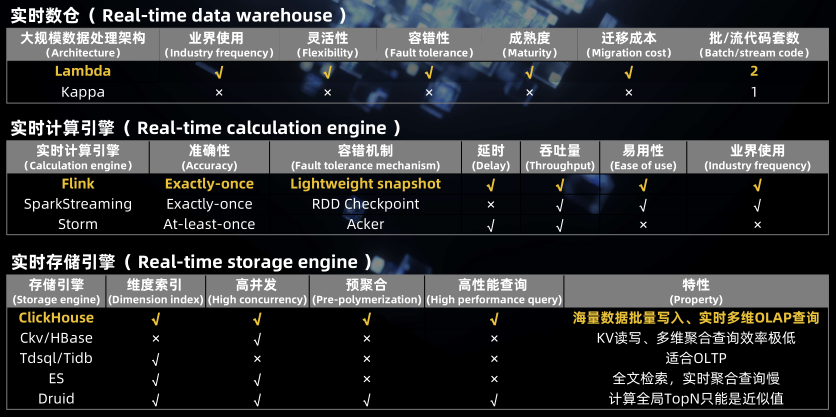
4、流批一体的ETL打宽:数据打宽是数据集成中最为常见的业务加工场景,数据打宽最主要的手段就是 Join,Flink SQL 提供了丰富的 Join 支持,包括 Regular Join、Interval Join、Temporal Join。

Regular Join(双流关联) 就是大家熟知的双流 Join,语法上就是普通的 JOIN 语法。如下图:
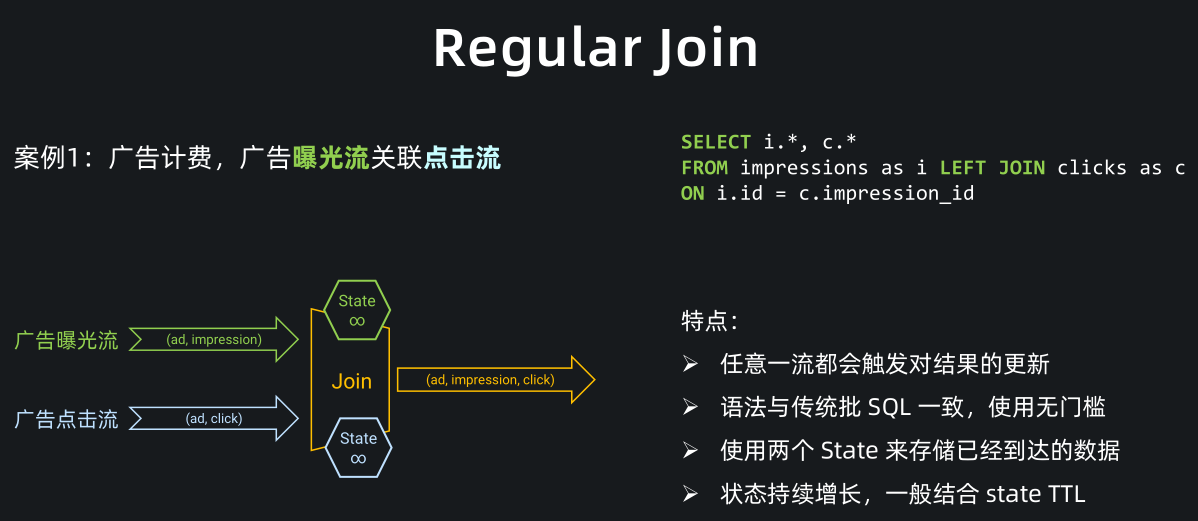
-
图中案例是通过广告曝光流关联广告点击流将广告数据打宽,打宽后可以进一步计算广告费用。
-
从图中可以看出,曝光流和点击流都会存入 join 节点的 state,join 算子通过关联曝光流和点击流的 state 实现数据打宽。
-
Regular Join 的特点是,任意一侧流都会触发结果的更新,比如案例中的曝光流和点击流。同时 Regular Join 的语法与传统批 SQL 一致,用户学习门槛低。
-
但需要注意的是,Regular join 通过 state 来存储双流已经到达的数据,state 默认永久保留,所以 Regular join 的一个问题是默认情况下 state 会持续增长,一般我们会结合 state TTL 使用。
- Flag:
Interval Join(区间关联) 是一条流上需要有时间区间的 join,比如刚刚的广告计费案例中,它有一个非常典型的业务特点在里面,就是点击一般发生在曝光之后的 10 分钟内。
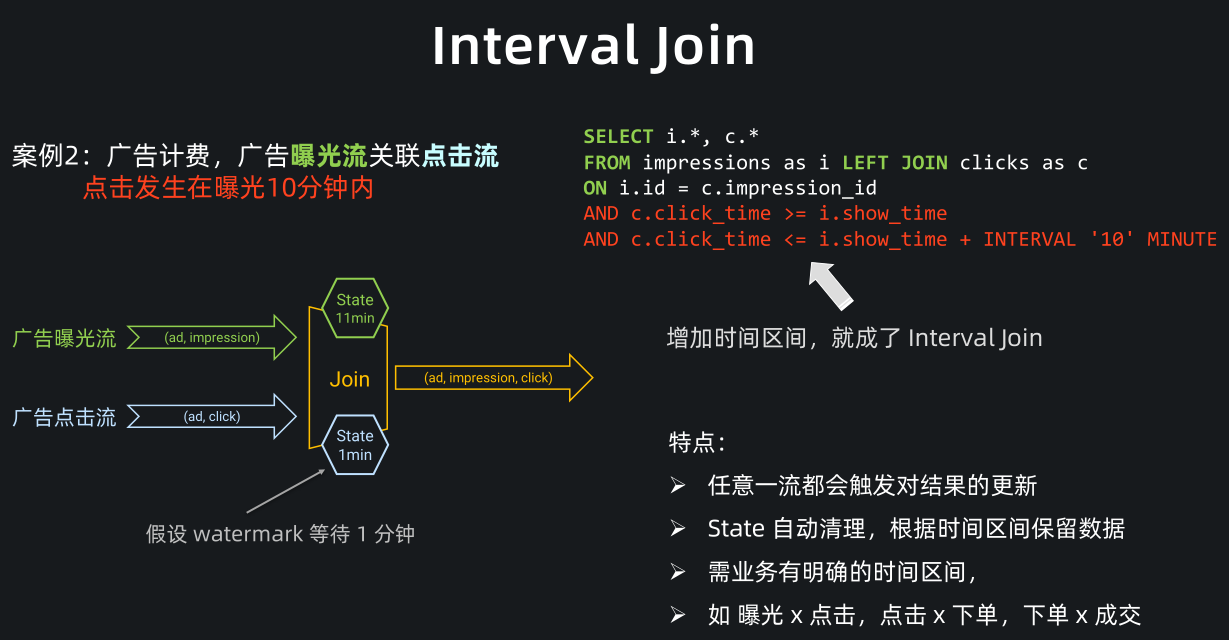
-
此相对于 Regular Join,我们其实只需要关联这10分钟内的曝光数据,所以 state 不用存储全量的曝光数据,它是在 Regular Join 之上的一种优化。
-
要转成一个 Interval Join,需要在两个流上都定义时间属性字段(如图中的 click_time 和 show_time)。
-
并在 join 条件中定义左右流的时间区间,比如这里我们增加了一个条件:点击时间需要大于等于曝光时间,同时小于等于曝光后 10 分钟。
-
与 Regular Join 相同, Interval Join 任意一条流都会触发结果更新,但相比 Regular Join,Interval Join 最大的优点是 state 可以自动清理,根据时间区间保留数据,state 占用大幅减少。
-
Interval Join 适用于业务有明确的时间区间,比如曝光流关联点击流,点击流关联下单流,下单流关联成交流。
Temporal join (时态表关联) 是最常用的数据打宽方式,它常用来做我们熟知的维表 Join。Flink 支持非常丰富的 Temporal join 功能,包括关联 lookup DB,关联 changelog,关联 Hive 表。在以前,大家熟知的维表 join 一般都是关联一个可以查询的数据库,因为维度数据在数据库里面,但实际上维度数据可能有多种物理形态,比如 binlog 形式,或者定期同步到 Hive 中变成了 Hive 分区表的形式。在 Flink 1.12 中,现在已经支持关联这两种新的维表形态。

-
Temporal Join Lookup DB 是最常见的维表 Join 方式,比如在用户点击流关联用户画像的案例中,用户点击流在 Kafka 中,用户实时画像存放在 HBase 数据库中,每个点击事件通过查询并关联 HBase 中的用户实时画像完成数据打宽。
-
Temporal Join Lookup DB 的特点是,维表的更新不会触发结果的更新,维度数据存放在数据库中,适用于实时性要求较高的场景,使用时我们一般会开启 Async IO 和内存 cache 提升查询效率。
再看一个 Lookup DB 的例子,这是一个直播互动数据关联直播间维度的案例。
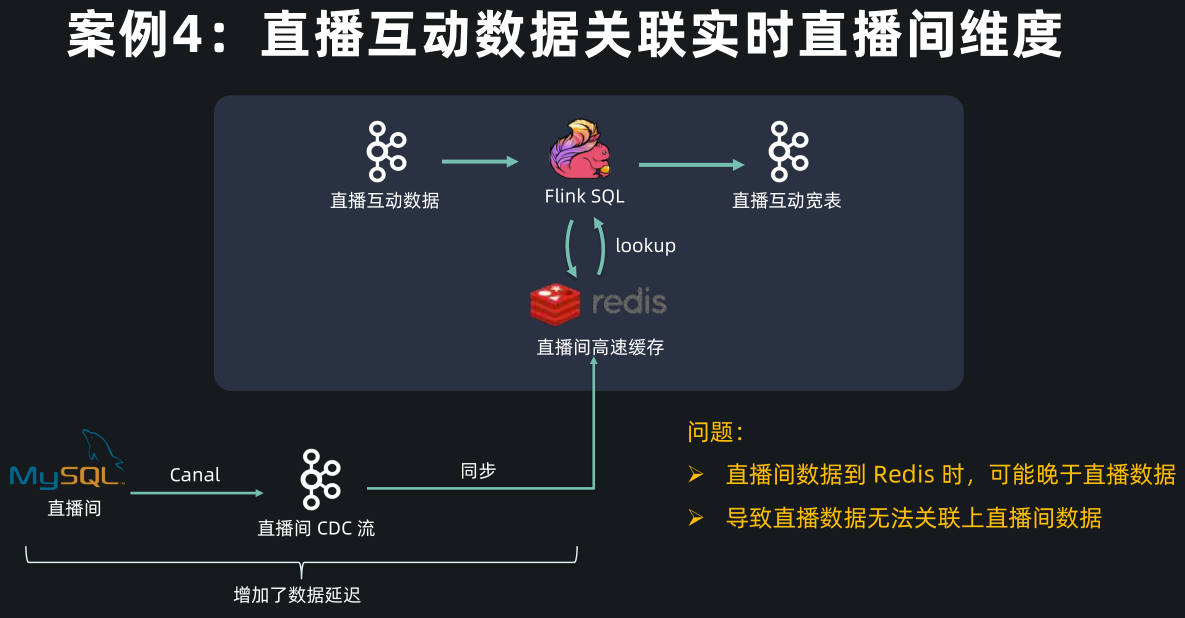
-
案例中直播互动数据(比如点赞、评论)存放在 Kafka 中,直播间实时的维度数据(比如主播、直播间标题)存放在 MySQL 中,直播互动的数据量是非常大的,为了加速访问,常用的方案是加个高速缓存,比如把直播间的维度数据通过 CDC 同步,再存入 Redis 中,再做维表关联。
- 这种方案的问题是,直播的业务数据比较特殊,直播间的创建和直播互动数据基本是同时产生的,因此互动数据可能早早地到达了 Kafka 被 Flink 消费,但是直播间的创建消息经过了 Canal, Kafka,Redis, 这个链路比较长,数据延迟比较大,可能导致互动数据查询 Redis 时,直播间数据还未同步完成,导致关联不上直播间数据,造成下游统计分析的偏差。
针对这类场景,Flink 1.12 支持了 Temporal Join Changelog,通过从 changelog在 Flink state 中物化出维表来实现维表关联。

-
刚刚的场景有了更简洁的解决方案,我们可以通过 Flink CDC connector 把直播间数据库表的 changelog 同步到 Kafka 中,注意我们看下右边这段 SQL,我们用了 upsert-kafka connector 来将 MySQL binlog 写入了 Kafka,也就是 Kafka 中存放了直播间变更数据的 upsert 流。然后我们将互动数据 temporal join 这个直播间 upsert 流,便实现了直播数据打宽的功能。
- 注意我们这里 FOR SYSTEM_TIME AS OF 不是跟一个 processing time,而是左流的 event time,它的含义是去关联这个 event time 时刻的直播间数据,同时我们在直播间 upsert 流上也定义了 watermark,所以 temporal join changelog 在执行上会做 watermark 等待和对齐,保证关联上精确版本的结果,从而解决先前方案中关联不上的问题。
我们详细解释下 temporal join changelog 的过程
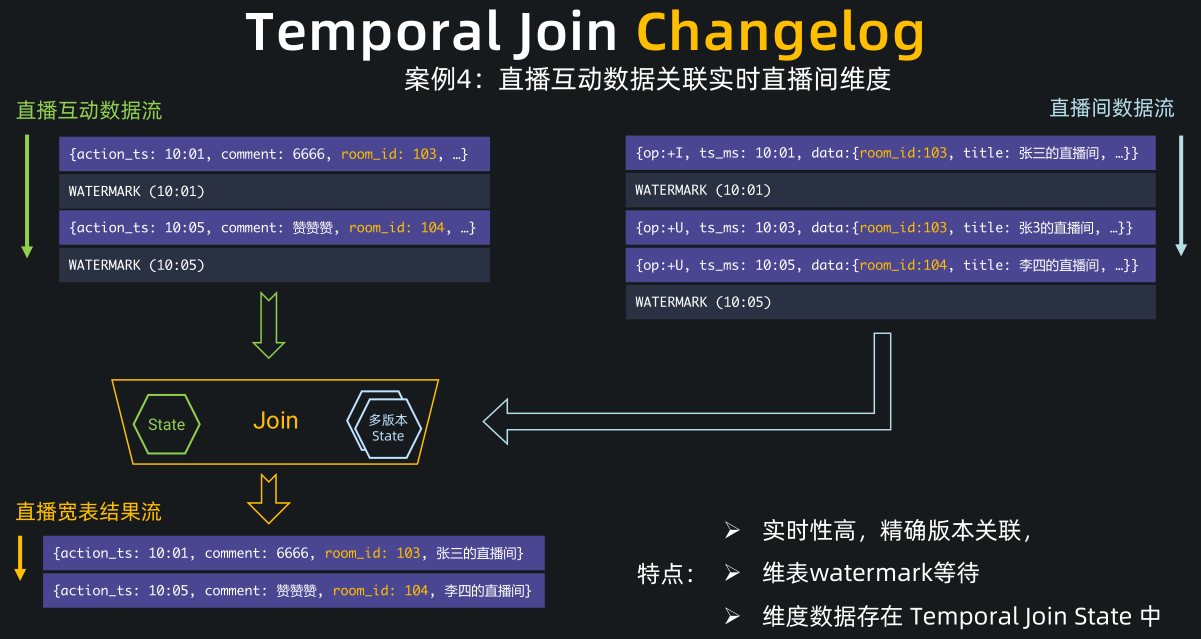
-
左流是互动流数据,右流是直播间 changelog。
-
直播间 changelog 会物化到右流的维表 state 中,state 相当于一个多版本的数据库镜像, 主流互动数据会暂时缓存在左流的 state 中,等到 watermark 到达对齐后再去查维表 state 中的数据。
-
比如现在互动流和直播流的 watermark 都到了10:01分,互动流的这条 10:01 分评论数据就会去查询维表 state,并关联上 103 房间的信息。当 10:05 这条评论数据到来时,它不会马上输出,不然就会关联上空的房间信息。它会一直等待,等到左右两流的 watermark 都到 10:05 后,才会去关联维表 state 中的数据并输出。这个时候,它能关联上准确的 104 房间信息。
- 总结下,Temporal Join Changelog 的特点是实时性高,因为是按照 event time 做的版本关联,所以能关联上精确版本的信息,且维表会做 watermark 对齐等待,使得用户可以通过 watermark 控制迟到的维表数。Temporal Join Changelog 中的维表数据都是存放在 temporal join 节点的 state 中,读取非常高效,就像是一个本地的 Redis 一样,用户不再需要维护额外的 Redis 组件。
在数仓场景中,Hive 的使用是非常广泛的,Flink 与 Hive 的集成非常友好,现在已经支持 Temporal Join Hive 分区表和非分区表。
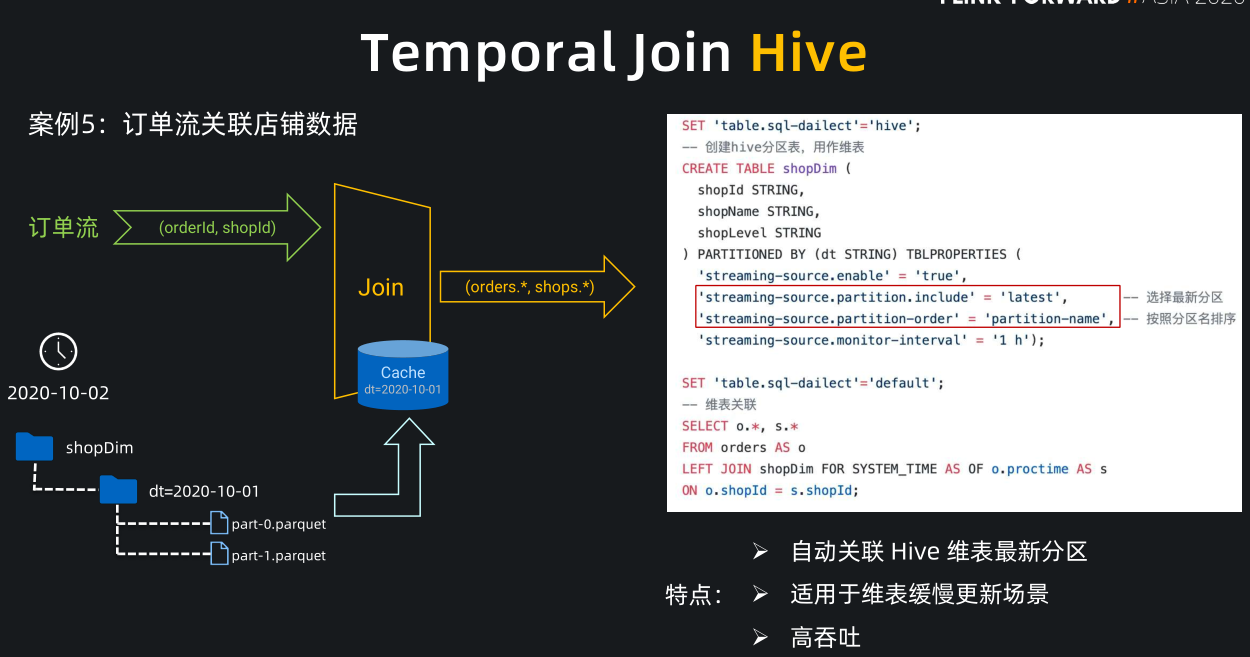
-
我们举个典型的关联 Hive 分区表的案例:订单流关联店铺数据。店铺数据一般是变化比较缓慢的,所以业务方一般会按天全量同步店铺表到 Hive 分区中,每天会产生一个新分区,每个分区是当天全量的店铺数据。
- 为了关联这种 Hive 数据,只需我们在创建 Hive 分区表时指定右侧这两个红圈中的参数,便能实现自动关联 Hive 最新分区功能,partition.include = latest 表示只读取 Hive 最新分区,partition-name 表示选择最新分区时按分区名的字母序排序。
- 到 10 月 3 号的时候,Hive 中已经产生了 10 月 2 号的新分区, Flink 监控到新分区后,就会重新加载10月2号的数据到 cache 中并替换掉10月1号的数据作为最新的维表。之后的订单流数据关联上的都是 cache 10 月 2 号分区的数据。
- Temporal join Hive 的特点是可以自动关联 Hive 最新分区,适用于维表缓慢更新,高吞吐的业务场景。
总结一下我们刚刚介绍的几种在数据打宽中使用的 join:
- Regular Join(双流Join) 的实效性非常高,吞吐一般,因为 state 会保留所有到达的数据,适用于双流关联场景;
- Interval Jon(区间Join) 的时效性非常好,吞吐较好,因为 state 只保留时间区间内的数据,适用于有业务时间区间的双流关联场景;
- Temporal Join Lookup DB 的时效性比较好,吞吐较差,因为每条数据都需要查询外部系统,会有 IO 开销,适用于维表在数据库中的场景;
- Temporal Join Changelog 的时效性很好,吞吐也比较好,因为它没有 IO 开销,适用于需要维表等待,或者关联准确版本的场景;
- Temporal Join Hive 的时效性一般,但吞吐非常好,因为维表的数据存放在cache 中,适用于维表缓慢更新的场景,高吞吐的场景。
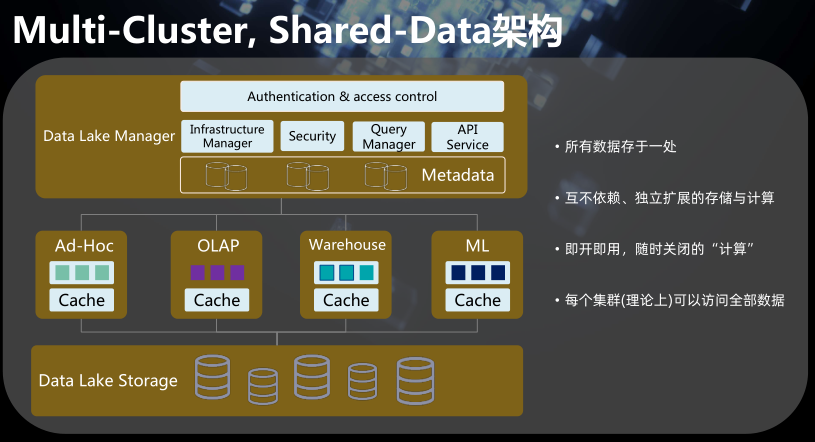
5、Multi-Cluster, Shared-Data架构
6、Native K8S HA / vs Yarn
- 统一运维 公司统一化运维,有专门的部门运维 K8S
- CPU 隔离 K8S Pod 之间 CPU 隔离,实时任务不相互影响,更加稳定
-
存储计算分离:Flink 计算资源和状态存储分离,计算资源能够和其他组件资源进行混部,提升机器使用率
- 弹性扩缩容 大促期间能够弹性扩缩容,更好的节省人力和物力成
7、Flink 交互
- NoteBook
- Zeppline
8、AI
- Flink AI Flow : https://github.com/alibaba/flink-ai-extended
- analytics-zoo: https://github.com/intel-analytics/analytics-zoo
Flag:
- 对照一下分钟曲线的打宽过程?
- 对照业务 能梳理出一个 lookup DB (HBase、Redis)的场景?
- 对照现在有的系统,大部分场景适合于用 Join Hive?
参考资料