《丁奇-MySQL45讲-01》之归纳总结
01 | 基础架构:一条SQL查询语句是如何执行的?
- MySQL架构图
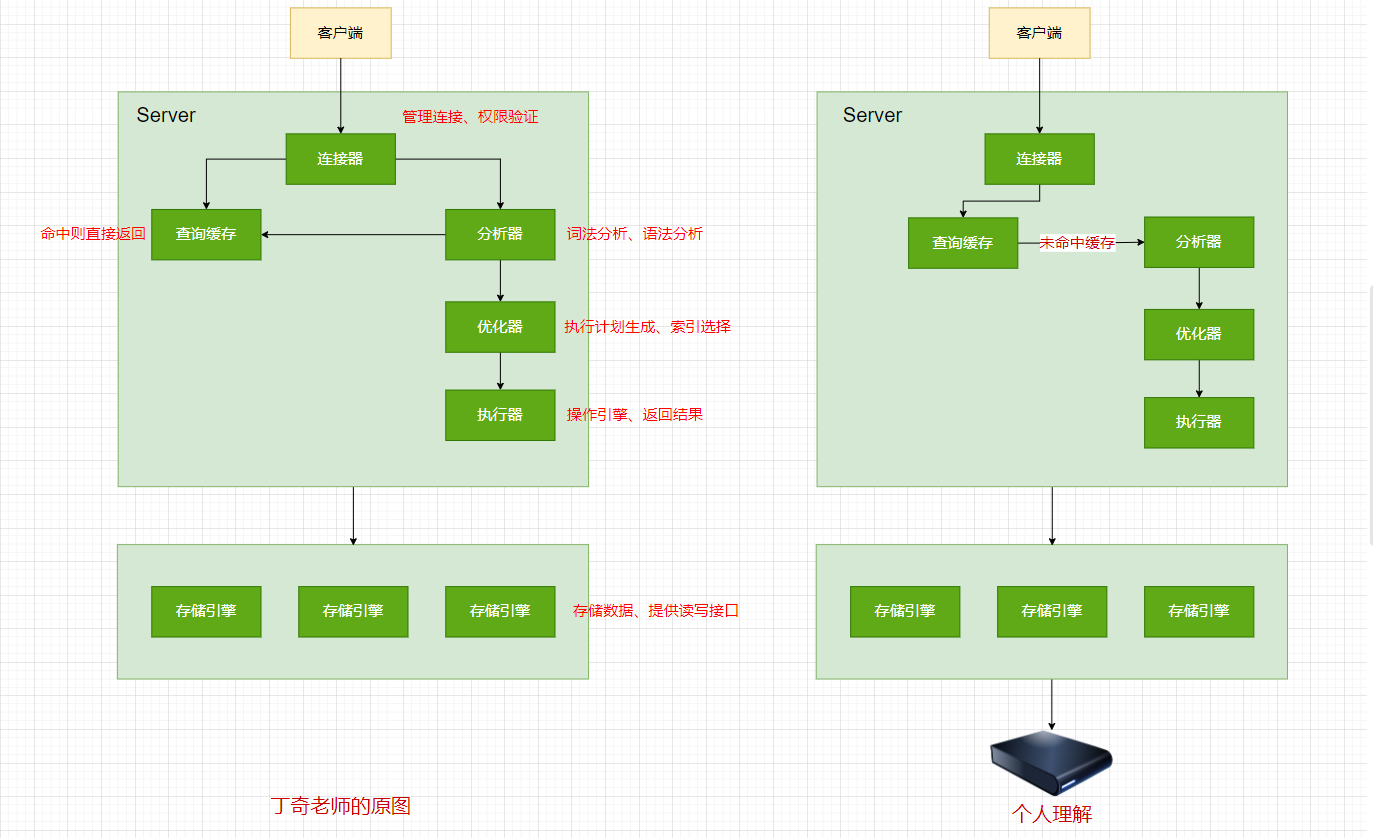
左侧图是丁奇老师原本的图,右侧是个人理解所画的,按照在文中的理论来说,个人认为应该是先查询缓存,如果查不到才会进行词法分析,比如有一条SQL:select * from T where ID = 10;,先去缓存中以该条SQL为key开始查询缓存,如果没查询到才会开始解析该SQL,通过select关键词分析可以知道该条SQL是要做查询,既然是做查询,就要遵循查询语句的相关语法(也会在这一层判断表是否存在、列是否存在),所以通常SQL语法校验错误应该就是这一层实现的,语法校验通过后,MySQL还会帮你优化下SQL,比如哪里去掉重复的内容或者是不必要的语句甚至有可能是条件语句,这么做的道理当然是为了更快更好地执行完一条SQL,安排好执行计划后就开始执行了。
总的来说,MySQL分为Server、存储引擎层两部分。Server层包括连接器、查询缓存(MySQL移除了该功能)、分析器、优化器、执行器,涵盖MySQL的大多数核心服务,像经常使用的内置函数如时间,应该是去存储引擎获取完数据后在进行时间函数的执行;存储引擎负责数据的存储和读取,其架构模式是插件式的,也就是说MySQL可以有多种存储引擎,要是有可能,你自己也是可以开发的,最经常使用的便是InnoDB,InooDB在MySQL5.5.5版本后开始称为默认存储引擎。
-
连接器:负责跟客户端建立连接、获取权限、管理连接。用户密码认证通过后,就会去权限表(mysql.user)查询对应用户的权限,之后,该会话的权限判断逻辑都将依赖此时读到的权限,说明权限信息属于会话级,即使有其他用户修改了你的权限,也不会影响到你,只有在开启新的会话后才会生效,MySQL应该是对权限信息对了缓存。
-
长连接:建立连接是耗时又耗力的操作,所以通常在建立完一个连接后最好是能够复用该连接,但同时复用一个连接有可能会造成内存过大,因为临时使用的内存是被当前连接所管理的,只有在当前连接断开的情况下,内存才会得到释放,那么可以在判断执行过一个占用内存大的查询后,断开连接(可以在提交事务后手动断开连接),或者如果使用的是MySQL5.7版本,那么可以执行mysql_reset_connection(属于
C的API,不是命令,难怪我执行不了)来恢复到初始状态。 -
分析器:其实一开始的场景已经说的很通俗易懂了。
-
优化器:说白了,就是MySQL会帮你的执行SQL做优化,同样都是去北京,你可以选择火车或飞机,也可以选择先做火车在做飞机,这其中也会考虑成本等其他因素,最终MySQL会决定一个方案出来。
-
执行器:根据表中的引擎定义(InnoDB还是MyISAM)调用指定引擎的API,接下来分析select * from T where ID = 10的执行流程:
ID不是索引:执行器调用存储引擎接口,存储引擎从磁盘上取T表的第一个数据页(丁奇老师文中写的是第一行,加上评论区大佬的分析,个人页认为是数据页,可能老师没表述清楚)返回给执行器,执行器拿到数据页后开始一个一个的判断ID是否等于10,如果不是就跳过,如果是就将其加入到结果集中,等该数据页遍历结束后,继续调用存储引擎的接口取T表的下一个数据页,重复上面的逻辑,直到取到T表的最后一个数据页。那么执行器怎么才知道当前数据页是否是T表的最后一页呢,个人理解应该会返回标志之类的,或者说存储引擎在最后一个数据页上加上标志即可,毕竟存储引擎知道是否是最后一页。
ID是索引:执行器带着ID = 10的参数调用存储引擎接口,存储引擎从磁盘索引树上找到ID = 10的第一个数据页返回给执行器,执行器直接放入到结果集中,接着继续调用存储引擎获取下一页。
以上两种场景的分析中加入了个人的理解,并不一定就是如此。两种场景的区别一方面是无索引场景下的判断是在Server层执行的,而有索引的是在存储引擎执行的,其实这也是有道理,通过索引查找到的数据一定是满足条件的,而索引也是存放在磁盘上的,也只有存储引擎能够读取磁盘的数据了;另外一方面是无索引场景下返回给执行器的数据页大小会比有索引下返回的数据页更大。丁奇老师文中对于这块有这么一个描述执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的,个人认为是执行器每调用一次存储引擎返回的是数据页,而数据页不止包含一行数据,所以说存储引擎扫描了多行,而rows_examined(慢查询日志中可以看到该变量)表示执行器调用存储引擎的次数。
唠嗑
不论是丁奇老师还是评论区的人都是大佬,一个比一个好问好学,关键都还解释到位,每次看完正文后还是刷好久的评论,一条一条的吸收,基本上一篇文章都是2个小时。