大数据分析:微信推文爬取与分析(词频词云分析)
首先先对《叮咚!院“十佳”优秀经管青年组团出道,快来打call~》这篇微信文章分析,查看网页源代码可以发现,整篇文章的文字部分以层次关系分别在<div id = “js_article”> --> <div class = “rich_media_inner”> --> <div id = “page_content> --> <div class = “rich_media_area_primary> --><div id = “img-content”> --> <div class = “rich_media_content”> 的标签之下,利用BeautifulSoup的find_all方法就可以找到class为rich_media_content的div之下的内容。网页的源代码层级如下
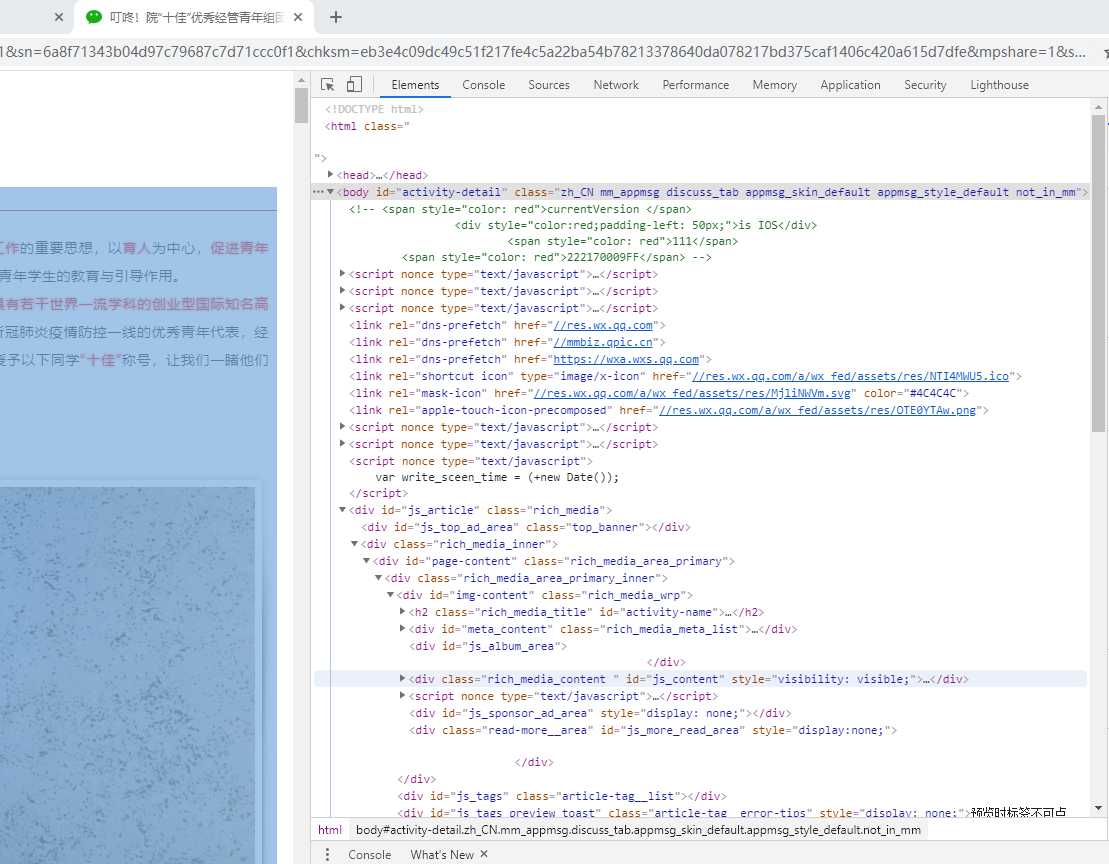
以下为代码片段,把正文部分爬取下来之后存储到txt文件中,方便接下来的词频词云分析。
#叮咚!院“十佳”优秀经管青年组团出道,快来打call~ import requests import re from bs4 import BeautifulSoup url = "https://mp.weixin.qq.com/s?__biz=MzI3MTc1NDExOQ==&mid=2247498465&idx=1&sn=6a8f71343b04d97c79687c7d71ccc0f1&chksm=eb3e4c09dc49c51f217fe4c5a22ba54b78213378640da078217bd375caf1406c420a615d7dfe&mpshare=1&scene=23&srcid=&sharer_sharetime=1591921147875&sharer_shareid=b9489319d498f78fa93ed3b25882d1f9#rd" headers={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36‘ } r = requests.get(url,headers=headers,timeout=5) soup1 = BeautifulSoup(r.text,"lxml") text1 = soup.find_all("div" , class_ = "rich_media_content") print(text1[0].get_text()) jgxytext = text[0].get_text() txt = open("jgxysj.txt" , "a+" , encoding = "utf-8") txt.write(jgxytext) txt.close()
代码运行的部分结果如下图所示:

对《喜讯 | 我院三个团支部荣获“福州大学十佳团支部立项”荣誉称号》这篇文章的分析也是类似的过程,正文部分也是在<div class = “rich_media_content”>的标签下,网页源代码如下图所示:
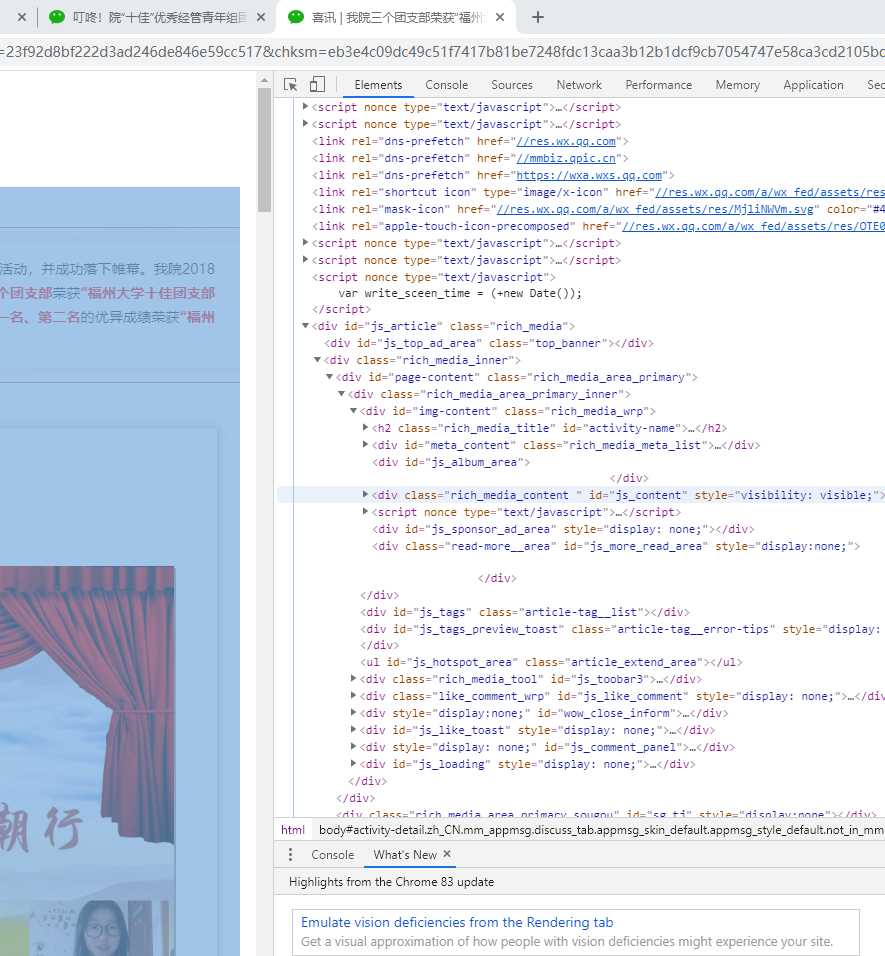
代码片段如下,把爬取到的文字部分追加到jgxysj.txt的文件下。
#喜讯 | 我院三个团支部荣获“福州大学十佳团支部立项”荣誉称号 import requests import re from bs4 import BeautifulSoup url = "https://mp.weixin.qq.com/s?__biz=MzI3MTc1NDExOQ==&mid=2247498465&idx=2&sn=23f92d8bf222d3ad246de846e59cc517&chksm=eb3e4c09dc49c51f7417b81be7248fdc13caa3b12b1dcf9cb7054747e58ca3cd2105bd4a77cd&mpshare=1&scene=23&srcid=&sharer_sharetime=1591921420851&sharer_shareid=b9489319d498f78fa93ed3b25882d1f9#rd" headers={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36‘ } r = requests.get(url,headers=headers,timeout=5) soup2 = BeautifulSoup(r.text,"lxml") text2 = soup.find_all("div" , class_ = "rich_media_content") print(text2[0].get_text()) jgxytext = text[0].get_text() txt = open("jgxysj.txt" , "a+" , encoding = "utf-8") txt.write(jgxytext) txt.close()

接下来进行词频分析,关键是使用jieba库进行分割词组,并统计各个词出现的出现频率。代码中的jgxy_list列表用于保存分割得到的词语,count字典的key为各词语,values为各个词语出现的次数,在统计的过程中过滤掉长度为1的词语。代码如下所示:
#词频分析 import jieba jgxy = open(‘jgxysj.txt‘,"r",encoding = "utf-8").read() text = jieba.lcut(jgxy) counts = {} jgxy_list = [] for word in text: if len(word) == 1: #退出一个字的词 continue else: counts[word]=counts.get(word,0)+1 jgxy_list.append(word.replace(" ","")) cloud_text=",".join(jgxy_list) items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(200): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))
代码执行结果如下图所示:
可以看到,两篇文章中出现最多的几个词语是“福州大学”、“学生”、“学院”等词语,但是有一些词对文本的分析可能会有干扰,在绘制词云图时选择把这些词设置为stopwords。同时,把中国地图作为词云图的背景进行绘制。词云绘制的代码如下:
#绘制云图 from PIL import Image import numpy as np from wordcloud import WordCloud,ImageColorGenerator from matplotlib import pyplot as plt cloud_mask = np.array(Image.open("ChinaMap.jpg")) st = set(["福州大学","同学","学院","获奖","感言","学生"]) jgxywd = WordCloud( background_color = "white", mask = cloud_mask, max_words = 200, font_path = "STXINGKA.TTF", min_font_size = 10, max_font_size = 50, width = 600, height = 600, stopwords = st ) jgxywd.generate(cloud_text) jgxywd.to_file("jgxywordcloud.PNG")
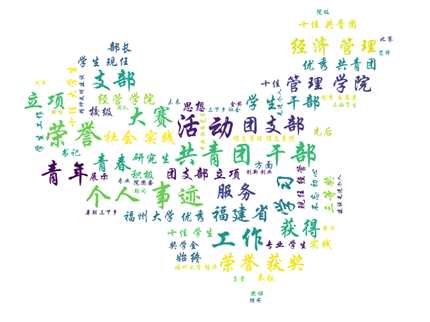
可以看到,两篇文章合成的文本所绘制的词云中,出现比较多的词语有“个人事迹”、“荣誉”、“共青团干部”、“大赛”、“工作”等,我们可以推断,取得院十佳大学生的同学们大都做过一些学生工作,多为共青团干部,参加过一些比赛,取得过一定的荣誉。所以,希望自己能多参与学生活动,积极学习,让自己变得更加优秀。