(原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用。包括随机梯度下降法、维批量梯度下降法、梯度下降法的收敛、在线学习、map reduce以及应用实例:photo OCR。课程地址为:https://www.coursera.org/course/ml
(一)大规模机器学习
从前面的课程我们知道,如果我们的系统是high variance的,那么增加样本数会改善我们的系统,假设现在我们有100万个训练样本,可想而知,如果使用梯度下降法,那么每次迭代都要计算这100万训练集的误差,计算代价显然很大。那么有没有什么办法来解决呢?
随机梯度下降(Stochastic gradient descent)
之前的批量梯度下降法定义代价函数为所有训练样本的误差和:
![]()
对比在前面的梯度下降法,我们重新定义代价函数为一个单一训练样本的误差:
![]()
算法流程:
首先对训练集随机“洗牌”,让训练数据乱序;
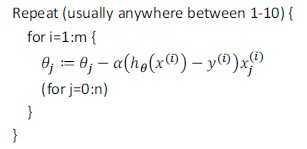
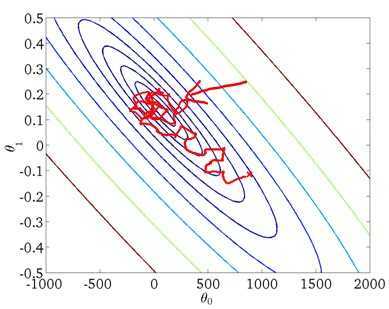
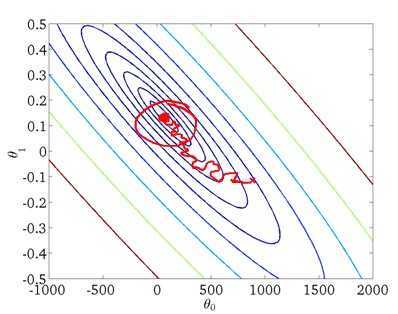
每次迭代只计算单一误差,然后更新θ,这样不是每一步都是“正确”的方向,因此算法虽然会“走近”全局最小,但可能只是在最小值附近徘徊,如下图所示:
微批量梯度下降法(Mini‐batch gradient descent)
微批量梯度下降法介于批量梯度下降和随机梯度下降之间,每次迭代计算b个训练样本的误差。
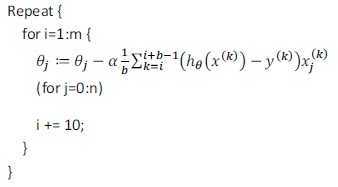
PS:通常令b介于2-200。
随机梯度下降收敛(Stochastic gradient descent convergence)
在批量梯度下降中,我们可以通过绘制J与迭代次数的函数来判断是否收敛。但是在大规模机器学习中,计算代价过大。
在随机梯度下降中,每次迭代前都计算cost(θ,(x(i),y(i))),比如每进行1000次迭代,绘制cost(θ,(x(i),y(i)))的平均值。
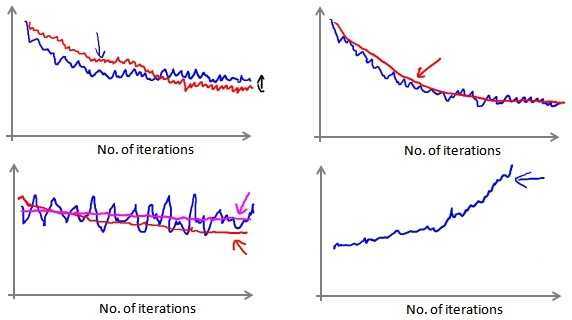
- 有时,我们会得到一个颠簸但不明显减少的图像(左下图),这样可以通过增加迭代间隔(比如2000次迭代计算平均)来使图像平缓;如果函数图仍然木有改善,则说明模型存在错误。
- 有时,我们会得到不断上升的图像(右下图),这样可以通过减小学习率α解决。
另外,我们也可以随迭代次数增加而减小学习率α,可用如下的算式:

这样在接近最小值点时,通过学习率,我们可以使算法收敛,如下图所示:
在线学习(online learning)
假设我们经营一家物流公司,当用户询问从A地到B地的快递费用时,我们会给出报价,用户可能会接受(y=1)或拒绝(y=0)。现在我们要建立模型,来预测用户接受报价的可能性。

在online learning中,许多网站都会有持续不断的用户流,在构建模型时,我们对单一实例进行学习,一旦该实例学习完了,便可以丢弃该数据。这样我们的模型可以很好适应并更新用户的倾向。
Map reduce 和 并行运算(data parallelism)
如果我们有多台计算机(或有一台多核的计算机),让每台计算机(或计算机的每个cpu)处理数据一个子集,然后再将计算结果求和,这样可以加速学习算法。计算流程如下所示:
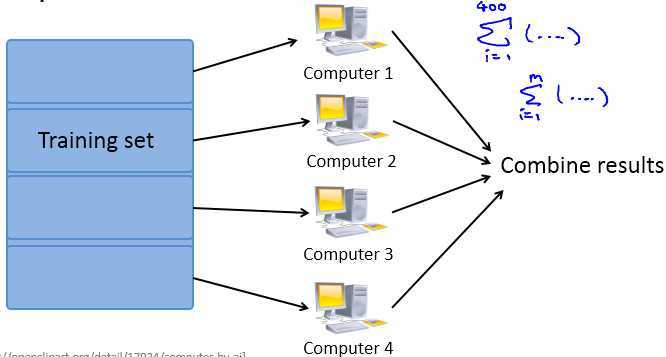
例如,有400个训练样本和4台计算机,我们可以使用批量梯度下降法将数据分给这4台计算机:

(二)应用实例(photo OCR)
问题描述:photo OCR的目标是从一张图像中识别文字。

算法步骤:
- 文字检测(Text detection)
- 字符切分(Character segmentation)
- 字符分类(Character classification)
其中每一项任务都由单独的团队负责,如下流程:

滑动窗口(Sliding windows)
1. 通过滑动窗口可以从图像中抽取对象,比如要在下图中识别行人,可以选择之前训练得到的行人的图片尺寸来对该图进行剪裁,然后对切片进行识别,判断其是否是行人。

2. 下面进行文字分割,即将文字分割成单个字符,训练集是单个字符的图片和两个相连字符之间的图片。
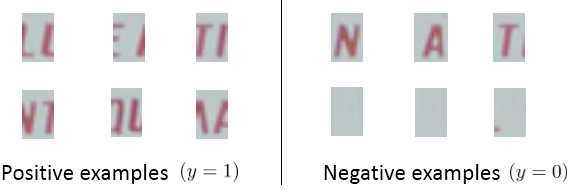
3. 最后进行字符识别,可以通过我们之前的神经网络、逻辑回归算法来实现。
获取数据(Getting lots of data: Artificial data synthesis)
对于high variance问题,我们需要获取更多的训练数据,那么怎样在有限的条件下获取数据呢?
在OCR问题中,我们可以下载各种字体,然后搭配不同的背景从而创造一些训练数据;另外,我们也可以通过利用已有的数据,对其进行修改,如对字符图片进行变形、旋转、模糊等处理,从而得到大量训练数据。
下一步该怎样做?(Ceiling analysis)
在机器学习的一些应用中,通常需要多个步骤来实现最终的预测,那么我们应该投入精力改善那一部分呢?
以OCR问题为例,流程如下:
我们可以选取每个流程的一部分,手动提供100%的正确输出结果,然后看看整体的提升效果。假设我们的模型整体效果为72%,若Text detection输出结果正确,模型效果为89%;若另character segmentation的输出结果正确,模型效果为90%(即只提高了1%)。这就意味着我们应该投入更大的精力在Text detection上面。
练习
这是本课程的最后一节课,没有作业,下面就罗列一些练习题目吧:










