【MobileNet V1】2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications-论文阅读
MobileNet V1
- 2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications
- Andrew Howard、Hartwig Adam(Google)
- GitHub: 1.4k stars
- Citation:4203
Introduction
本文介绍了一种新的网络结构,MobileNet(V1),网络结构上与VGG类似,都属于流线型架构,但使用了新的卷积层——深度可分离卷积(depthwise separable convonlution)替换了原始的全卷积层,使得网络参数和计算量都大大减小,在0.12倍的计算量和0.14倍的参数量的情况下,精度仅下降1%,引入两个超参数(宽度乘数、分辨率乘数),可以方便的构建更小的MobileNet,在模型大小和精度之间平衡。属于网络压缩中的轻量化网络设计的方法。
Motivation
随着深度学习的流行,卷积网络的计算开销越来越大,因此人们开始寻找减少网络参数/计算量的方法,设计更高效的模型。
Contribution
轻量化网络(较小的计算开销和存储开销)主流的方法有两种
- 减少模型参数,既可以减少模型计算开销,也可减少模型存储开销
- 量化模型参数,可以减少存储开销
MobileNet使用深度可分离卷积来替代传统的全卷积,有效的地降低了模型参数量和计算量。
Method
深度可分离卷积(depthwise separable convolution)
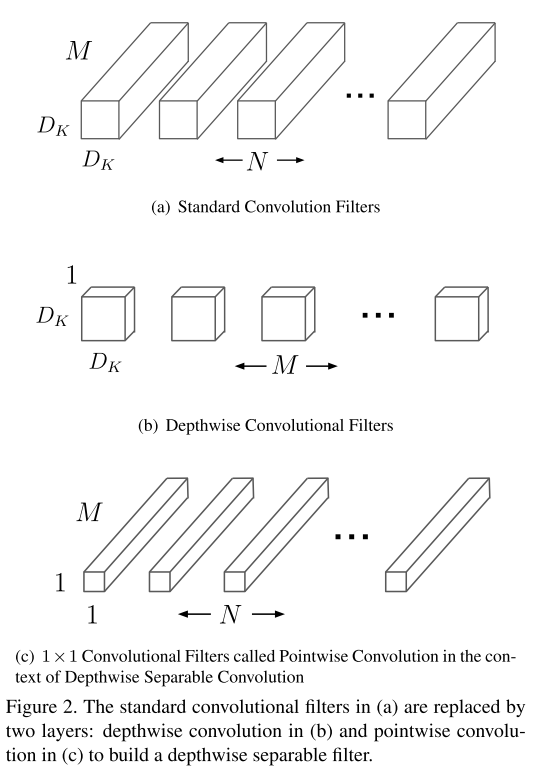
深度可分离卷积是MobileNet的核心。深度可分离卷积是因子卷积(将大卷积分解为小的卷积?)的一种,将标准的全卷积分解为通道深度卷积(depthwise convolution)+1x1逐点卷积(pointwise convolution);其中深度卷积是将同一个filter应用到所有的input channels上,点卷积是将1x1的卷积核,应用在深度卷积的output channels上。传统的conv是将滤波乘法(feature map元素乘法)和通道合并(将多个channels map整合成一个channels)两个步骤在一步完成;而深度可分离卷积是将两个步骤分开,一层用于滤波乘法,一层用于通道合并。
标准卷积:
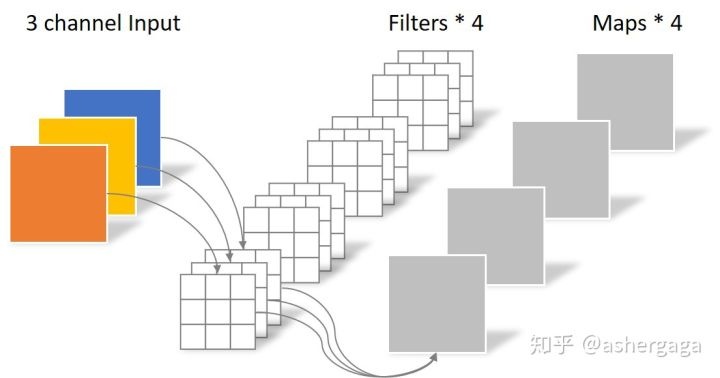
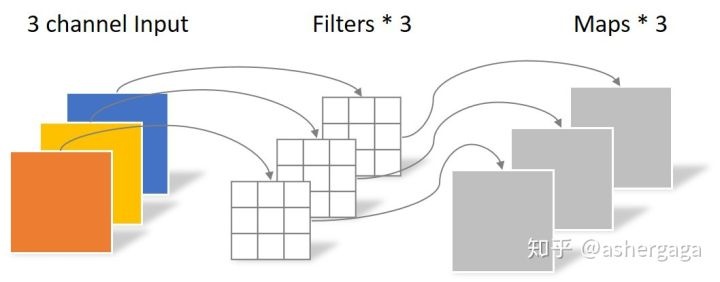
通道卷积:
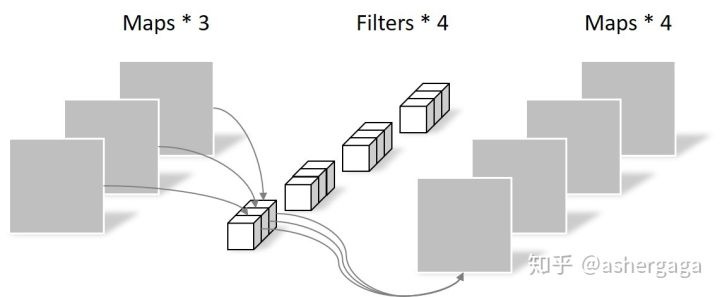
逐点卷积:
计算开销对比:
标准卷积的计算开销: \(D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}\)
深度可分离卷积的计算开销: \(D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}+M \cdot N \cdot D_{F} \cdot D_{F}\)
&&计算开销的计算:参数数量×一个feature map的大小
计算开销对比: $\frac{D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}+M \cdot N \cdot D_{F} \cdot D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}} = \frac{1}{N}+\frac{1}{D_{K}^{2}} $
网络结构
MobileNet的除了第一个卷积层是标准卷积,其余的卷积层都是深度可分离卷积。
表1为MobileNet的网络结构,将通道卷积层和点卷积层看做单独的层,则MobileNet共有28层(1全卷积 + 2 × 13深度可分离卷积 + 1全连接 = 28)。
&&有参数的层才算入?
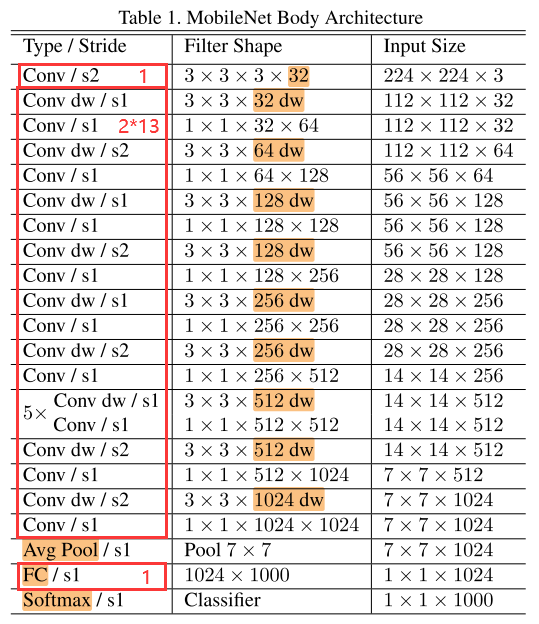
图3对比了标准卷积层和可分离卷积层(通道卷积层+逐点卷积层),每个卷积层后都跟着BN层和ReLU层。

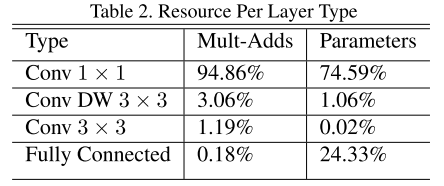
表2为MobileNet中不同类型的层的计算量和参数量对比:
宽度乘数 α(Width Multiplier)
为了构建更小的MobileNet,引入第一个超参数——Width Multiplier α,在α的作用下,网络的计算代价变为: \(D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{F} \cdot D_{F}+\alpha M \cdot \alpha N \cdot D_{F} \cdot D_{F}\)
α的取值范围(0,1],取1时就是baseline MobileNet
应用宽度乘数可以将计算开销和存储开销变为为原来的 \(\alpha^2\) 倍
分辨率乘数 ρ(Resolution Multiplier)
分辨率乘数可以减小输入图片的分辨率,一般通过设置输入图片的分辨率来隐式地设置 \(\rho\)
同时应用宽度乘数和分辨率乘数,计算代价变为:
\(D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F}+\alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F}\)
其中,ρ∈(0, 1],通常隐式设置网络的输入分辨率为224、192、160或128。
应用宽度乘数可以将计算开销和存储开销变为为原来的 \(\rho^2\) 倍。
表3对比了全卷积、深度可分离卷积、应用了α和ρ的深度可分离卷积的模型的计算量和参数量:

Experiments
全卷积的MobileNet VS MobileNet:

在相近的计算量下,瘦长的MobileNet 和 胖矮的MobileNet 的精度对比,瘦长的MobileNet效果更好,说明层数更重要(所以是使用宽度层数α,改变模型宽度,而不是减少模型的层数):

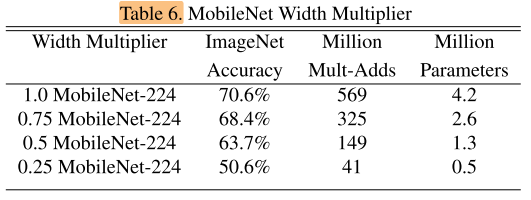
应用了宽度乘数α的MobileNet效果对比:
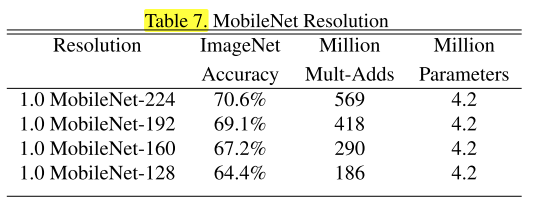
应用了分辨率乘数ρ(输入分辨率不同)的MobileNet效果对比:
在ImageNet上与经典网络的对比:
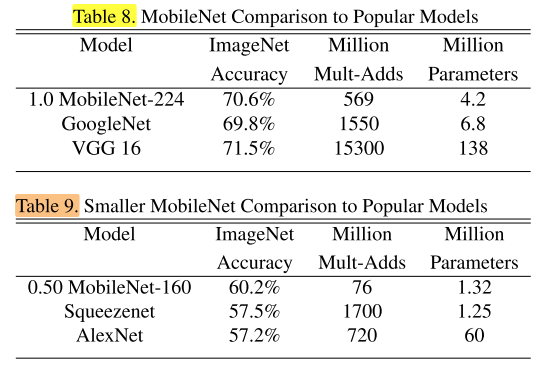
在Stanford Dogs数据集上与经典网络的对比:

其他实验:
细粒度识别实验、大规模地理定位实验、Face Attributes实验、Object Detection实验、Face Embeddings实验
Conclusion
-
提出了新的轻量模型MobileNet,核心是使用深度可分离卷积代替标准全卷积,大大减少计算量和参数量
-
通过宽度乘数和分辨率乘数2个超参数很好的在baseline MobileNet的基础上构建更小的MobileNet模型
Summary
-
想法很简单,效果很好!
-
实验非常丰富!
Reference
【深度可分离卷积】https://zhuanlan.zhihu.com/p/92134485
【薰风读论文:MobileNet 详解深度可分离卷积,它真的又好又快吗?】https://zhuanlan.zhihu.com/p/80177088