索引优化数据库(原理篇)
时间:2020-05-21 00:11:55
收藏:0
阅读:83
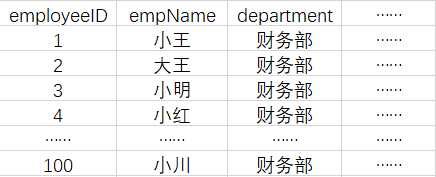
如图,这是一张有一百行数据的employee数据表。
假设每行占128Bytes,那么存入磁盘的时候,是怎么存储的呢?
磁盘由磁道和扇区组成,磁盘和扇区组成一个基本的存储单位,我们称之为“块”,块的存储空间一般默认为512Bytes。
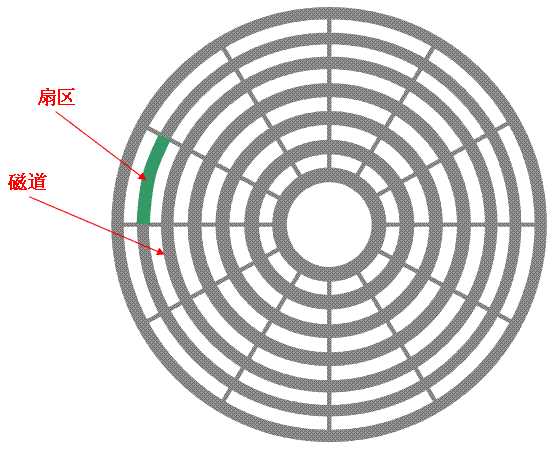
刚才的employee数据表有一百行,每行128Bytes,那么就要占用(100*128)/512 = 25个块。
如果我们想要查询某个员工的信息,比如查询名字为张三的员工,大约需要访问多少个块呢?
答案是:最少访问一个块,最多访问25个块。
我们在考虑问题的时候要做最坏的打算,所以这里我们认为是访问25个块。
我们知道,读取磁盘的时候,我们是需要旋转磁盘来确定其扇区,通过前后移动磁头来确定其磁道,这样就能定位到一个具体的块。
可以想象,这样的读取速度是很慢的,而且要读取很多个块,才能查找到一条信息,对于现在的大企业来说,信息可能不止我这里的100行,可能是上万行,十万行....那么怎样才能优化查询的速度呢?这里我们就引入了索引。
下图我们建立了一个索引,并且假设索引表的每行占16Bytes,那么索引表1需要存入1个块当中,索引表2需要存入(16*100)/512<4,所以要存入四个块当中。
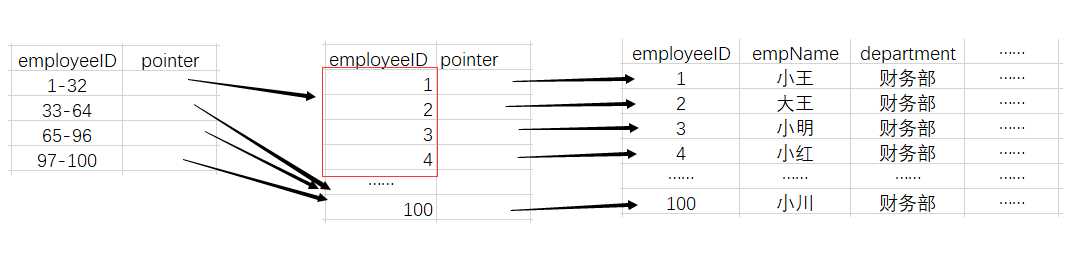
回到例子中,我们要查询的张三的employeeID=66,我们先查找索引表1,可以得到它在索引表2中的位置,进而就访问到了张三的信息所在的块。
这里,访问索引表1和索引表2各访问一次块,最后查找张三信息也访问了一次块,因此总共只访问了3次块。
并且这个访问块的次数是稳定的,不管查询哪条信息,都是3次。
所以我们可以看到,为数据表建立索引提升了查询速度。
在实际操作中,我们可以用B树或者B+树来实现这一操作。
这篇文章只是理论介绍,具体实操,不知道啥时候会做。。。
评论(0)