Nginx" upstream prematurely closed connection while reading response header from upstream"问题排查
问题背景
我们这边是一个基于Nginx的API网关(以下标记为A),最近两天有调用方反馈,偶尔会出现502错误,我们从Nginx的error日志里看,就会发现有" upstream prematurely closed connection while reading response header from upstream"这么一条错误日志,翻译过来其实就是上游服务过早的关闭了连接,意思很清楚,但是为什么会出现这种情况呢。而且是在业务低峰出现这种情况(也只是小概率的出现),在业务高峰的时候没有出现这种情况,而且上游服务方(以下标记为B)说出问题的请求他们那边没有收到,也就是没有任何记录,这就比较诡异了。测试环境不知道如何去复现,也就不好排查。
排查过程
1、在服务器上开启tcpdump抓包 tcpdump -nps0 -iany -w /tmp/20180617.pcap net [ip] and net [ip],如果不知道tcpdump怎么使用的同学可以百度一下。
2、在nginx的error.log中观察到到有两条" upstream prematurely closed connection while reading response header from upstream"错误日志,分别是2018/06/07 20:41:27和2018/06/08 09:10:46两个时间点,如下图
3、然后查看抓包数据,找到了对应时间点的包数据,从这个可以看出,A向B发送了一个1060-2143的包,,而服务端发送了一个Fin断开连接。为什么服务端会断开连接了,我们不得而知。
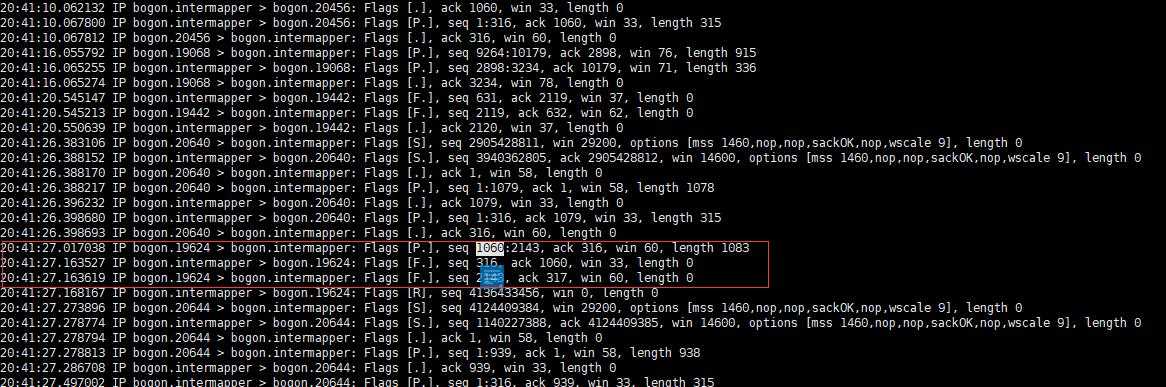
4、上一步A发送包首字节数是1060,那必然前面肯定发送过包,那我们继续往上查,发现了如下图所示的现象。在20:40:22的时候3次握手建立连接并发送了第一个包;而且也查了在20:40:22到20:41:27中间这条长连接没有发送任何包

5、和B沟通,他们的Nginx中的keepalive_timeout配置为65秒,keepalive_timeout这个配置的意思是说长连接保持的时间,如果没有任何数据传输的话,超过这个时间,服务端会关闭这个连接。那这就对上了,说明在这65秒没有任何数据传输,也正好在这个点,A向B发送了数据,而B关闭了这个连接,于是就出现了上面的现象。
6、当然这是我根据抓包分析出来的结果,我也自己模拟了这种情况,写了一个定时任务,每隔一分钟向第一台nginx发送请求,转发到第二台nginx上。第二台nginx的keepalive_timeout配置为60,在发送第七次的时候,出现了同样的问题,nginx打印同样的错误日志,抓包的结果也和上述情况一致。验证了我上述的分析过程。
问题总结
1、如果系统并发量不大,没有必要开启长连接,有两种方式,一、第一台nginx可以去除proxy_http_version 1.1; proxy_set_header Connection "0";这两个配置;二、第二台nginx的keepalive_timeout可以配置为0(默认是75)。
2、上述问题我的解决方案是:暂时调大keepalive_timeout的值,先观察,但很有可能还是会有这个问题。
后记
1、网络问题的排查过程是很痛苦了,再一次验证了基础知识的重要性。
2、偶然报出的问题,一定不要忽视,说不定以后就是系统的瓶颈。