目标检测 — two-stage检测
目前主流的目标检测算法主要是基于深度学习模型,其可以分成两大类:two-stage检测算法;one-stage检测算法。本文主要介绍第一类检测算法,第二类在下一篇博文中介绍。
目标检测模型的主要性能指标是检测准确度和速度,对于准确度,目标检测要考虑物体的定位准确性,而不单单是分类准确度。一般情况下,two-stage算法在准确度上有优势,而one-stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进。
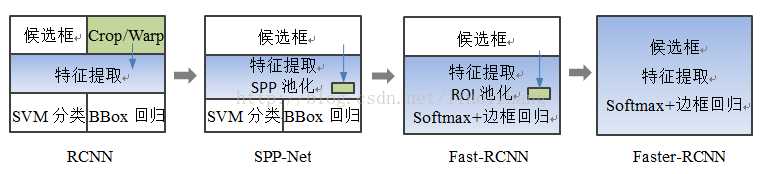
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修),这类算法的典型代表是基于region proposal的R-CNN系算法,如R-CNN,SPPNet ,Fast R-CNN,Faster R-CNN,FPN等;
1、R-CNN(13)
R-CNN算法分为4个步骤 :
- 一张图像生成1K~2K个候选区域 ,Selective search方法(使用了Selective Search方法从一张图像生成约2000-3000个候选区域。基本思路如下: 使用一种过分割手段,将图像分割成小区域 ;查看现有小区域,合并可能性最高的两个区域(基于颜色、纹理等)。重复直到整张图像合并成一个区域位置; 输出所有曾经存在过的区域,所谓候选区域);
- 对每个候选区域,归一化为同一尺寸,使用深度网络提取特征 ;
- 特征送入每一类的SVM 分类器(二分类),判别是否属于该类 ;
- 使用回归器精细修正候选框位置 ;
RCNN存在三个明显的问题:
1)多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2)针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3)每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
4)方法中的三个模型是分别训练的——CNN提取图像特征、分类器预测类别、回归模型tighten bounding box的边界,这也导致流程不易训练。
2、SPPNet (14)
SPP-Net在RCNN的基础上做了实质性的改进:
(1)取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题;
在R-CNN中,由于每个候选区域大小是不同,所以需要先resize成固定大小才能送入CNN网络,SPP-net正好可以解决这个问题。采用空间金字塔池化(SpatialPyramid Pooling )替换了 全连接层之前的最后一个池化层。为了适应不同分辨率的特征图,定义一种可伸缩的池化层,不管输入分辨率是多大,都可以划分成m*n个部分。这是SPP-net的第一个显著特征,它的输入是conv5特征图 以及特征图候选框(原图候选框 通过stride映射得到),输出是固定尺寸(m*n)特征;
SPP层原理如下所示,假定CNN层得到的特征图大小为a×a(比如13×13,随输入图片大小而变化),设定的金字塔尺度为n×n bins(对于不同大小图片是固定的),那么SPP层采用一种滑动窗口池化,窗口大小win_size=?a/n?,步为stride=?a/n?stride=?a/n?,采用max pooling,本质上将特征图均分为n×n个子区域,然后对各个子区域max pooling,这样不论输入图片大小,经过SPP层之后得到是固定大小的特征。一般设置多个金字塔级别,文中使用了4×4,2×2和1×1三个尺度。每个金字塔都得一个特征,将它们连接在一起送入后面的全连接层即可,这样就解决了变大小图片输入的问题了。
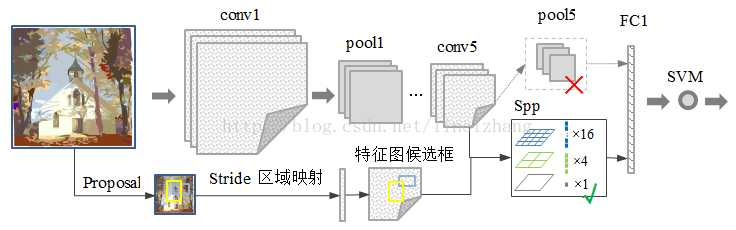
(2)只对原图提取一次特征:SPP的位置,放在所有的卷积层之后,有效解决了卷积层的重复计算问题(速度提高了24~102倍),这是论文的核心贡献。
R-CNN每次都要挨个使用CNN模型计算各个候选区域的特征,这是极其费时的,不如直接将整张图片送入CNN网络,然后抽取候选区域的对应的特征区域,采用SPP层,这样可以大大减少计算量,并提升速度。基于SPP层的R-CNN模型在准确度上提升不是很大,但是速度却比原始R-CNN模型快24-102倍。
尽管SPP-Net贡献很大,仍然存在很多问题:
(1)和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
(2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
(3)在整个过程中,Proposal Region仍然很耗时。
3、Fast R-CNN(15)
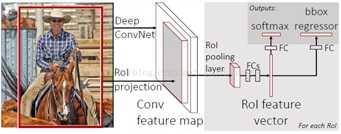
Fast RCNN 在 RCNN的基础上做了实质性的改进:
(1)共享卷积层:输入一张完整的图片,再把候选框映射到conv5上,得到每个候选框的特征。提出简化版的ROI池化层(注意,没用金字塔)。
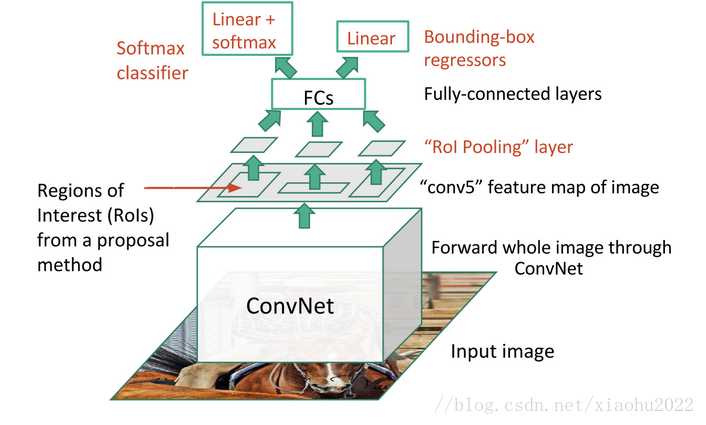
(2)多任务Loss层:把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
在实现上是使用两个不同的全连接层,第一个全连接层有N+1个输出(N是类别总数,1是背景),表示各个类别的概率值;第二个全连接层有4N个输出,表示坐标回归值(tx,ty,tw,th),这个与R-CNN是一样的,每个类别都预测4个位置坐标值。Fast R-CNN采用了softmax分类器而不是SVM分类器(softmax性能好一些),定位误差采用smooth L1 而不是R-CNN中的L2。
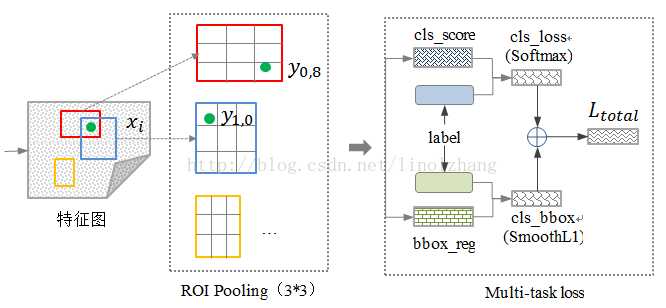
总代价为两者加权和,如果分类为背景则不考虑定位代价。损失函数:
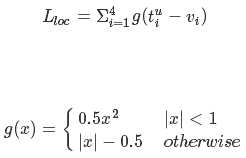
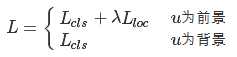
4、Faster R-CNN(15)
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?解决:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。做这样的任务的神经网络叫做Region Proposal Network(RPN)。
Faster R-CNN的主要贡献是设计了提取候选区域的网络RPN,代替了费时的选择性搜索,将候选框提取合并到深度网络中,使得检测速度大幅提高。
具体做法:将RPN放在最后一个卷积层的后面;RPN直接训练得到候选区域。RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,在feature map上滑动窗口,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。 目标分类只需要区分候选框内特征为前景或者背景,边框回归确定更精确的目标位置。
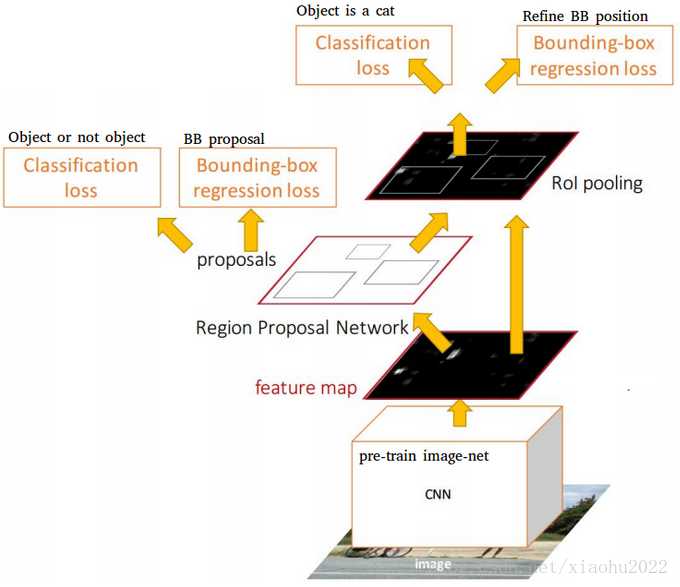
一种网络,四个损失函数:RPN calssification(anchor good.bad);RPN regression(anchor->propoasal);Fast R-CNN classification(over classes);Fast R-CNN regression(proposal ->box)。
Faster R-CNN模型采用一种4步迭代的训练策略:(1)首先在ImageNet上预训练RPN,并在PASCAL VOC数据集上finetuning;(2)使用训练的PRN产生的region proposals单独训练一个Fast R-CNN模型,这个模型也先在ImageNet上预训练;(3)用Fast R-CNN的CNN模型部分(特征提取器)初始化RPN,然后对RPN中剩余层进行finetuning,此时Fast R-CNN与RPN的特征提取器是共享的;(4)固定特征提取器,对Fast R-CNN剩余层进行finetuning。这样经过多次迭代,Fast R-CNN可以与RPN有机融合在一起,形成一个统一的网络。
其实还有另外一中近似联合训练策略,将RPN的2个loss和Fast R-CNN的2个loss结合在一起,然后共同训练。注意这个过程,Fast R-CNN的loss不对RPN产生的region proposals反向传播,所以这是一种近似(如果考虑这个反向传播,那就是非近似联合训练)。应该来说,联合训练速度更快,并且可以训练出同样的性能。
5、最后总结一下各大算法的步骤:
- RCNN解决的是,“为什么不用CNN做classification呢?”
- Fast R-CNN解决的是,“为什么不一起输出bounding box和label呢?”
- Faster R-CNN解决的是,“为什么还要用selective search呢?”
(1)RCNN
- 在图像中确定约1000-2000个候选框 (使用选择性搜索)
- 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
- 对候选框中提取出的特征,使用分类器(SVM二分类)判别是否属于一个特定类
- 对于属于某一类特征的候选框,用回归器进一步调整其位置
(2)Fast RCNN
- 在图像中确定约1000-2000个候选框 (使用选择性搜索)
- 对整张图片输进CNN,得到feature map
- 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
- 对于属于某一特征的候选框,用回归器进一步调整其位置
(3)Faster RCNN
- 对整张图片输进CNN,得到feature map
- 卷积特征输入到RPN,得到候选框的特征信息
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
- 对于属于某一特征的候选框,用回归器进一步调整其位置
5、FPN (17)
原有的目标检测算法通常都是只采用顶层特征做检测,原因是网络顶层特征的语义信息比较丰富。然而,虽顶层特征的语义信息丰富,但其中的目标位置信息却比较粗略,不利于目标包围框的准确定位;相反,虽然底层特征的语义信息比较少,但其中目标的位置信息却非常准确。
FPN 主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量情况下,大幅度提升了小物体检测的性能。
一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。侧向连接通过 1x1 的卷积进行连接(减少特征图维度同时保证尺寸不变),通过 Add 操作进行 Merge。
同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的。
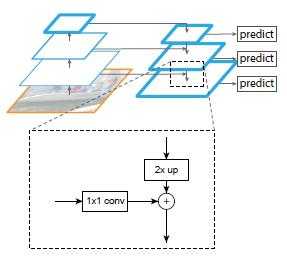
论文实验结论:
<1> 如果没有top-down的语义增强分支(仍然从不同的层输出),那么RPN的AR(average recall)会下降6%左右;
<2> 如果不进行特征的融合(也就是说去掉所有的1x1侧连接),虽然理论上分辨率没变,语义也增强了,但是AR下降了10%左右!作者认为这些特征上下采样太多次了,导致它们不适于定位。Bottom-up的特征包含了更精确的位置信息。
<3> 如果不利用多个层进行输出呢?作者尝试只在top-down的最后一层(分辨率最高、语义最强)设置anchors,仍然比FPN低了5%。需要注意的是这时的anchors多了很多,但是并没有提高AR。
<4> 在RPN和object detection任务中,FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
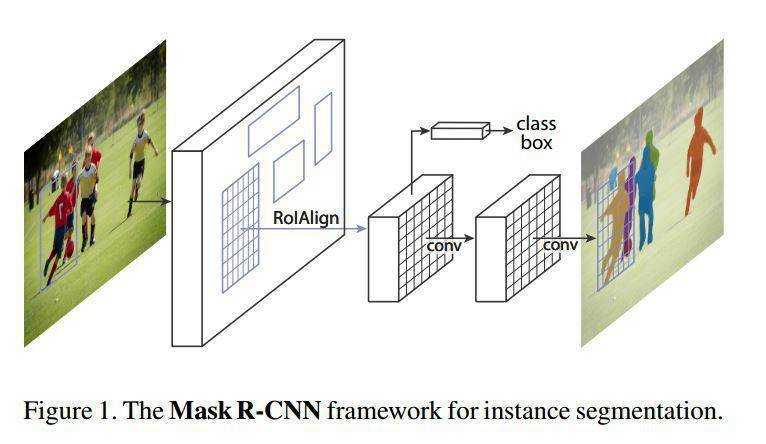
6、Mask R-CNN(17)
Mask R-CNN在此基础上更进一步:得到像素级别的检测结果。 对每一个目标物体,不仅给出其边界框,并且对边界框内的各个像素是否属于该物体进行标记。
主要贡献其实就是RoIAlign以及加了一个mask分支。 RoIAlign,是将RoIPooling的插值方式,从最近邻插值(INTER_NEAREST)方式变为双线性插值。
参考博客:https://blog.csdn.net/xiaohu2022/article/details/79600037
https://www.cnblogs.com/skyfsm/p/6806246.html
https://blog.csdn.net/xyfengbo/article/details/70227173