CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212
环境:Win8.1 TensorFlow1.0.1
软件:Anaconda3 (集成Python3及开发环境)
TensorFlow安装:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
TFLearn安装:pip install tflearn
参考:
Deep Residual Learning for Image Recognition Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
1. 前言
ResNet(Residual Neural Network)由前微软研究院的 Kaiming He 等4名华人提出,通过使用 Residual Blocks 成功训练152层深的神经网络,在 ILSVRC 2015 比赛中获得了冠军,取得 3.57% 的 top-5 错误率,同时参数量却比 VGGNet 低,效果非常突出。ResNet 的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。上一篇博文讲解了 Inception,而 Inception V4 则是将 Inception Module 和 ResNet 相结合。可以看到 ResNet 是一个推广性非常好的网络结构,甚至可以直接应用到 Inception Net 中。
在 CVPR16 上何凯明、张祥雨、任少卿和孙剑四人的 Deep Residual Learning for Image Recognition 毫无争议地获得了 Best Paper。
关于这篇文章细节可参考:
2. 问题
作者首先提出的问题是,深度神经网络是不是越深越好?
- 理想情况下,只要网络不过拟合,应该是越深越好。
- 实际情况是网络加深,accuracy 却下降了,称这种情况为 Degradation。(cnn中文汉字手写识别构建网络遇到过!)
LSTM 的提出者 Schmidhuber 早在 Highway Network 里指出神经网络的深度对其性能非常重要,但是网络越深其训练难度越大,Highway Network 的目标就是解决极深的神经网络难以训练的问题。Highway Network 相当于修改了每一层的激活函数,此前的激活函数只是对输入做一个非线性变换,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network:
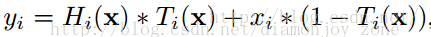
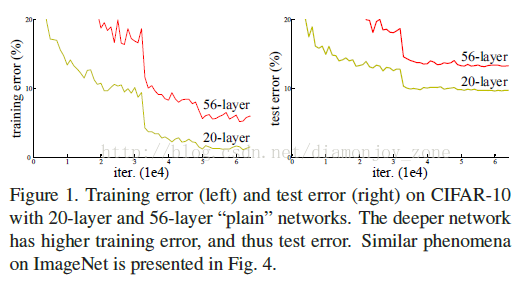
ResNet 最初的灵感出自这个问题:在不断加神经网络的深度时,会出现一个 Degradation 的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。
假设有一个比较浅的网络(Shallow Net)达到了饱和的准确率,那么后面再加上几个的全等映射层(Identity mapping),起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是 ResNet 的灵感来源。
3. 组成
作者提出一个 Deep residual learning 框架来解决这种因为深度增加而导致性能下降问题。
假定某段神经网络的输入是 x,期望输出是 H(x),即 H(x)
是期望的复杂潜在映射,但学习难度大;如果我们直接把输入 x 传到输出作为初始结果,通过下图“shortcut connections”,那么此时我们需要学习的目标就是 F(x)=H(x)-x,于是 ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是最优解 H(X) 和全等映射 x 的差值,即残差
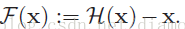
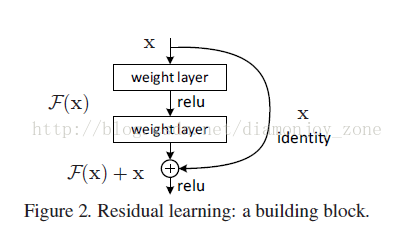
Shortcut 原意指捷径,在这里就表示越层连接,在 Highway Network 在设置了一条从 x 直接到 y 的通路,以 T(x, Wt) 作为 gate 来把握两者之间的权重;而 ResNet shortcut
没有权值,传递 x 后每个模块只学习残差F(x),且网络稳定易于学习,作者同时证明了随着网络深度的增加,性能将逐渐变好。可以推测,当网络层数够深时,优化 Residual Function:F(x)=H(x)?x,易于优化一个复杂的非线性映射 H(x)。
4. 网络结构
下图所示为 VGGNet-19,以及一个34层深的普通卷积网络,和34层深的 ResNet 网络的对比图。可以看到普通直连的卷积神经网络和 ResNet 的最大区别在于,ResNet 有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为 shortcut connections。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
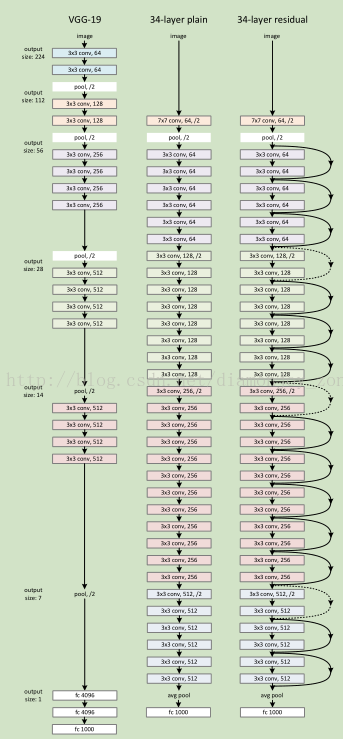
同时34层 residual network 取消了最后几层 FC,通过 avg pool 直接接输出通道为1000的 Softmax,使得 ResNet 比16-19层 VGG 的计算量还低。
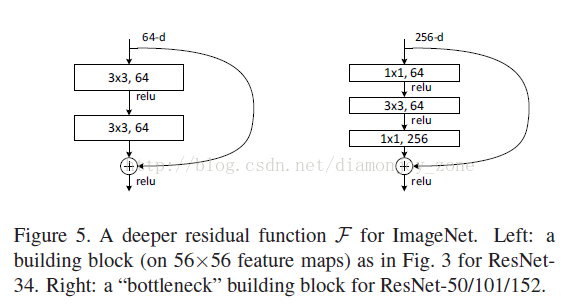
在 ResNet 的论文中,除了提出残差学习单元的两层残差学习单元,还有三层的残差学习单元。两层的残差学习单元中包含两个相同输出通道数(因为残差等于目标输出减去输入,即,因此输入、输出维度需保持一致)的3′3卷积;而3层的残差网络则使用了 Network In Network 和 Inception Net 中的1′1卷积,并且是在中间3′3的卷积前后都使用了1′1卷积,先降维再升维的操作,降低计算复杂度。另外,如果有输入、输出维度不同的情况,我们可以对
x 做一个线性映射变换,再连接到后面的层。
5. 实验
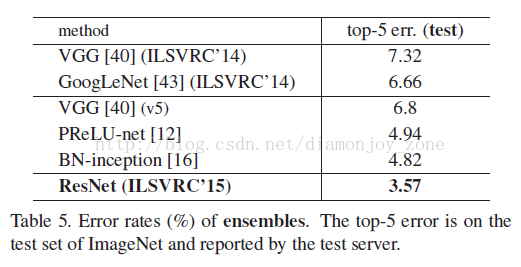
在使用了 ResNet 的结构后,可以发现层数不断加深导致的训练集上误差增大的现象被消除了,ResNet 网络的训练误差会随着层数增大而逐渐减小,并且在测试集上的表现也会变好。最终在 ILSVRC 2015 比赛中获得了冠军,取得 3.57% 的 top-5 错误率。
tflearn 给出了 ResNet 在 CIFAR-10 上的实例 residual_network_cifar10.py,tflearn 通过 tflearn.residual_block 可以方便定义残差学习单元:
- # -*- coding: utf-8 -*-
- """ Deep Residual Network.
- Applying a Deep Residual Network to CIFAR-10 Dataset classification task.
- References:
- - K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image
- Recognition, 2015.
- - Learning Multiple Layers of Features from Tiny Images, A. Krizhevsky, 2009.
- Links:
- - [Deep Residual Network](http://arxiv.org/pdf/1512.03385.pdf)
- - [CIFAR-10 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html)
- """
- from __future__ import division, print_function, absolute_import
- import tflearn
- # Residual blocks
- # 32 layers: n=5, 56 layers: n=9, 110 layers: n=18
- n = 5
- # Data loading
- from tflearn.datasets import cifar10
- (X, Y), (testX, testY) = cifar10.load_data()
- Y = tflearn.data_utils.to_categorical(Y, 10)
- testY = tflearn.data_utils.to_categorical(testY, 10)
- # Real-time data preprocessing
- img_prep = tflearn.ImagePreprocessing()
- img_prep.add_featurewise_zero_center(per_channel=True)
- # Real-time data augmentation
- img_aug = tflearn.ImageAugmentation()
- img_aug.add_random_flip_leftright()
- img_aug.add_random_crop([32, 32], padding=4)
- # Building Residual Network
- net = tflearn.input_data(shape=[None, 32, 32, 3],
- data_preprocessing=img_prep,
- data_augmentation=img_aug)
- net = tflearn.conv_2d(net, 16, 3, regularizer=‘L2‘, weight_decay=0.0001)
- net = tflearn.residual_block(net, n, 16)
- net = tflearn.residual_block(net, 1, 32, downsample=True)
- net = tflearn.residual_block(net, n-1, 32)
- net = tflearn.residual_block(net, 1, 64, downsample=True)
- net = tflearn.residual_block(net, n-1, 64)
- net = tflearn.batch_normalization(net)
- net = tflearn.activation(net, ‘relu‘)
- net = tflearn.global_avg_pool(net)
- # Regression
- net = tflearn.fully_connected(net, 10, activation=‘softmax‘)
- mom = tflearn.Momentum(0.1, lr_decay=0.1, decay_step=32000, staircase=True)
- net = tflearn.regression(net, optimizer=mom,
- loss=‘categorical_crossentropy‘)
- # Training
- model = tflearn.DNN(net, checkpoint_path=‘model_resnet_cifar10‘,
- max_checkpoints=10, tensorboard_verbose=0,
- clip_gradients=0.)
- model.fit(X, Y, n_epoch=200, validation_set=(testX, testY),
- snapshot_epoch=False, snapshot_step=500,
- show_metric=True, batch_size=128, shuffle=True,
- run_id=‘resnet_cifar10‘)
6. 后续
在 ResNet 推出后不久,Google 就借鉴了 ResNet 的精髓,提出了 Inception V4 和 Inception-ResNet-V2,并通过融合这两个模型,在 ILSVRC 数据集上取得了惊人的 3.08%的错误率。可见,ResNet 及其思想对卷积神经网络研究的贡献确实非常显著,具有很强的推广性。
在 ResNet 的作者的第二篇相关论文 Identity Mappings in Deep Residual Networks中,ResNet V2被提出。ResNet V2 和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此shortcut connection 的非线性激活函数(如ReLU)替换为 Identity Mappings。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。