
几个月前,我写了一篇关于如何使用已经训练好的卷积(预训练)神经网络模型(特别是VGG16)对图像进行分类的教程,这些已训练好的模型是用Python和Keras深度学习库对ImageNet数据集进行训练得到的。
这些已集成到(先前是和Keras分开的)Keras中的预训练模型能够识别1000种类别对象(例如我们在日常生活中见到的小狗、小猫等),准确率非常高。
先前预训练的ImageNet模型和Keras库是分开的,需要我们克隆一个单独github repo,然后加到项目里。使用单独的github repo来维护就行了。
不过,在预训练的模型(VGG16、VGG19、ResNet50、Inception V3 与 Xception)完全集成到Keras库之前(不需要克隆单独的备份),我的教程已经发布了,通过下面链接可以查看集成后的模型地址。我打算写一个新的教程,演示怎么使用这些最先进的模型。
https://github.com/fchollet/keras/blob/master/keras/applications/vgg16.py
具体来说,是先写一个Python脚本,能加载使用这些网络模型,后端使用TensorFlow或Theano,然后预测你的测试集。
在本教程前半部分,我们简单说说Keras库中包含的VGG、ResNet、Inception和Xception模型架构。
然后,使用Keras来写一个Python脚本,可以从磁盘加载这些预训练的网络模型,然后预测测试集。
最后,在几个示例图像上查看这些分类的结果。
Keras上最好的深度学习图像分类器
下面五个卷积神经网络模型已经在Keras库中,开箱即用:
1、VGG16
2、VGG19
3、ResNet50
4、Inception V3
5、Xception
我们从ImageNet数据集的概述开始,之后简要讨论每个模型架构。
ImageNet是个什么东东
ImageNet是一个手动标注好类别的图片数据库(为了机器视觉研究),目前已有22,000个类别。
然而,当我们在深度学习和卷积神经网络的背景下听到“ImageNet”一词时,我们可能会提到ImageNet视觉识别比赛,称为ILSVRC。
这个图片分类比赛是训练一个模型,能够将输入图片正确分类到1000个类别中的某个类别。训练集120万,验证集5万,测试集10万。
这1,000个图片类别是我们在日常生活中遇到的,例如狗,猫,各种家居物品,车辆类型等等。ILSVRC比赛中图片类别的完整列表如下:
http://image-net.org/challenges/LSVRC/2014/browse-synsets
在图像分类方面,ImageNet比赛准确率已经作为计算机视觉分类算法的基准。自2012年以来,卷积神经网络和深度学习技术主导了这一比赛的排行榜。
在过去几年的ImageNet比赛中,Keras有几个表现最好的CNN(卷积神经网络)模型。这些模型通过迁移学习技术(特征提取,微调(fine-tuning)),对ImaegNet以外的数据集有很强的泛化能力。
VGG16 与 VGG19
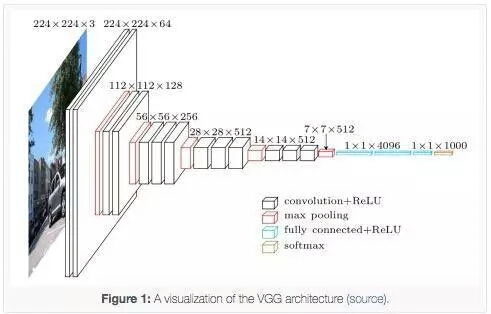
在2014年,VGG模型架构由Simonyan和Zisserman提出,在“极深的大规模图像识别卷积网络”(Very Deep Convolutional Networks for Large Scale Image Recognition)这篇论文中有介绍。
论文地址:https://arxiv.org/abs/1409.1556
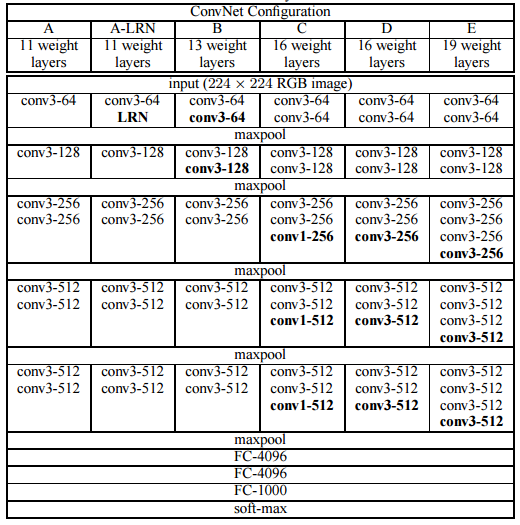
VGG模型结构简单有效,前几层仅使用3×3卷积核来增加网络深度,通过max pooling(最大池化)依次减少每层的神经元数量,最后三层分别是2个有4096个神经元的全连接层和一个softmax层。
“16”和“19”表示网络中的需要更新需要weight(要学习的参数)的网络层数(下面的图2中的列D和E),包括卷积层,全连接层,softmax层:
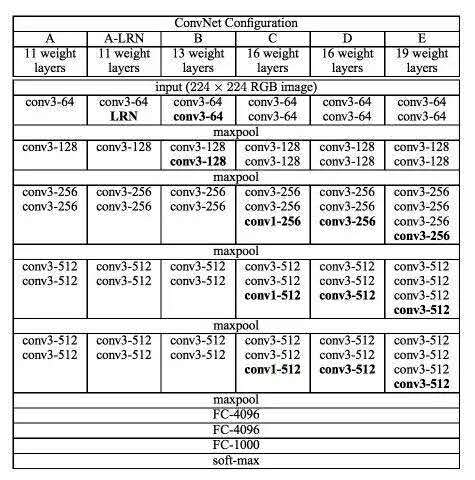
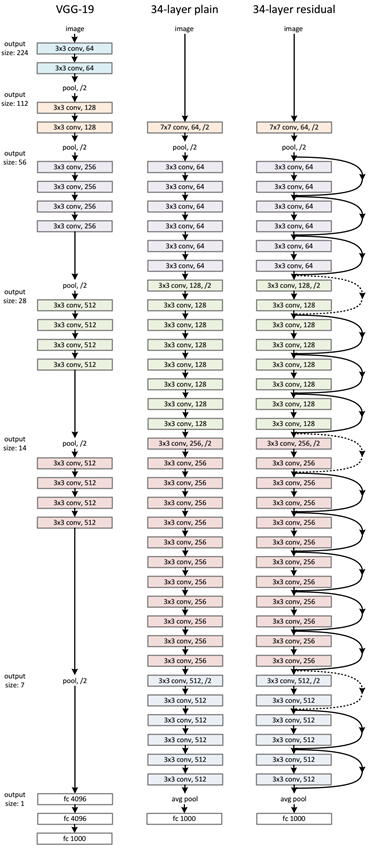
在2014年,16层和19层的网络被认为已经很深了,但和现在的ResNet架构比起来已不算什么了,ResNet可以在ImageNet上做到50-200层的深度,而对于CIFAR-10了来说可以做到1000+的深度。
Simonyan和Zisserman发现训练VGG16和VGG19有些难点(尤其是深层网络的收敛问题)。因此为了能更容易进行训练,他们减少了需要更新weight的层数(图2中A列和C列)来训练较小的模型。
较小的网络收敛后,用较小网络学到的weight初始化更深网络的weight,这就是预训练。这样做看起没有问题,不过预训练模型在能被使用之前,需要长时间训练。
在大多数情况下,我们可以不用预训练模型初始化,而是更倾向于采用Xaiver/Glorot初始化或MSRA初始化。读All you need is a good init这篇论文可以更深了解weight初始化和深层神经网络收敛的重要性。
MSRA初始化: https://arxiv.org/abs/1502.01852
All you need is a good init: https://arxiv.org/abs/1511.06422
不幸的是,VGG有两个很大的缺点:
1、网络架构weight数量相当大,很消耗磁盘空间。
2、训练非常慢
由于其全连接节点的数量较多,再加上网络比较深,VGG16有533MB+,VGG19有574MB。这使得部署VGG比较耗时。我们仍然在很多深度学习的图像分类问题中使用VGG,然而,较小的网络架构通常更为理想(例如SqueezeNet、GoogLeNet等)。
ResNet(残差网络)
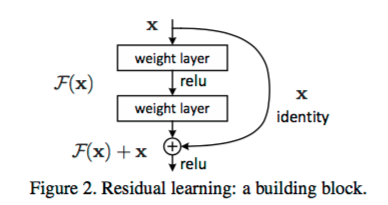
与传统的顺序网络架构(如AlexNet、OverFeat和VGG)不同,其加入了y=x层(恒等映射层),可以让网络在深度增加情况下却不退化。下图展示了一个构建块(build block),输入经过两个weight层,最后和输入相加,形成一个微架构模块。ResNet最终由许多微架构模块组成。
在2015年的“Deep Residual Learning for Image Recognition”论文中,He等人首先提出ResNet,ResNet架构已经成为一项有意义的模型,其可以通过使用残差模块和常规SGD(需要合理的初始化weight)来训练非常深的网络:
论文地址:https://arxiv.org/abs/1512.03385
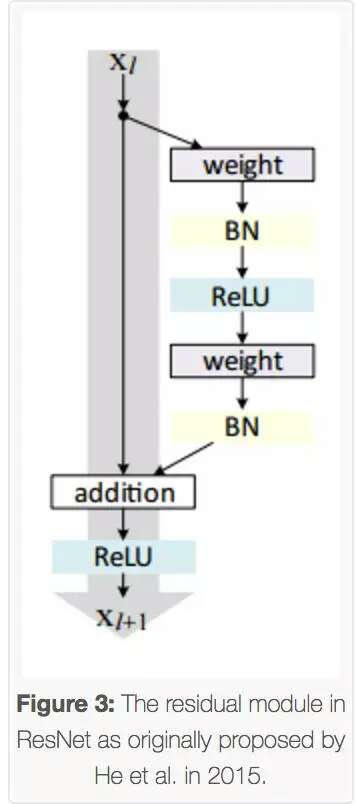
其在2016年后发表的文章“Identity Mappings in Deep Residual Networks”中表明,通过使用identity mapping(恒等映射)来更新残差模块,可以获得很高的准确性。
论文地址:https://arxiv.org/abs/1603.05027
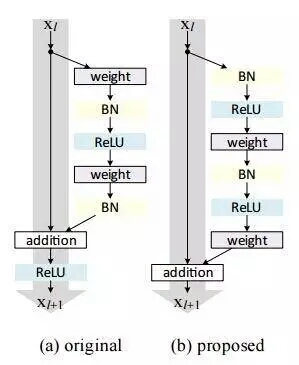
需要注意的是,Keras库中的ResNet50(50个weight层)的实现是基于2015年前的论文。
即使是RESNET比VGG16和VGG19更深,模型的大小实际上是相当小的,用global average pooling(全局平均水平池)代替全连接层能降低模型的大小到102MB。
Inception V3
“Inception”微架构由Szegedy等人在2014年论文"Going Deeper with Convolutions"中首次提出。
论文地址:https://arxiv.org/abs/1409.4842
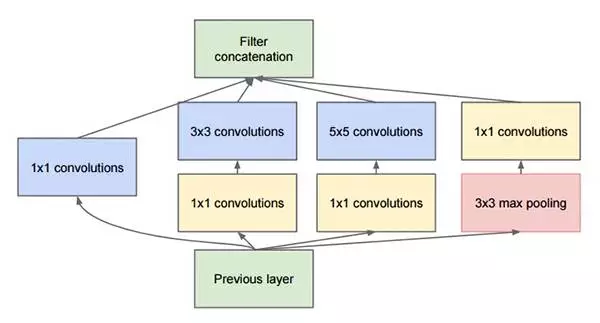
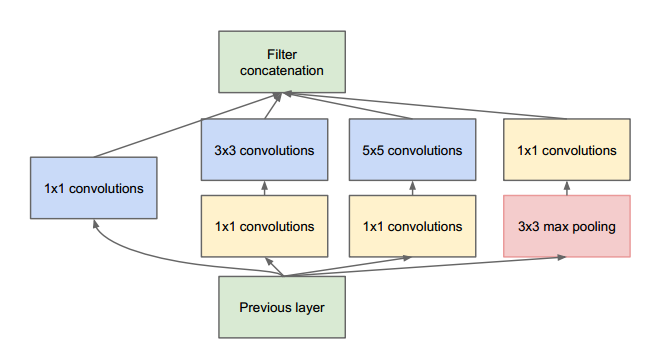
Inception模块的目的是充当“多级特征提取器”,使用1×1、3×3和5×5的卷积核,最后把这些卷积输出连接起来,当做下一层的输入。
这种架构先前叫GoogLeNet,现在简单地被称为Inception vN,其中N指的是由Google定的版本号。Keras库中的Inception V3架构实现基于Szegedy等人后来写的论文"Rethinking the Inception Architecture for Computer Vision",其中提出了对Inception模块的更新,进一步提高了ImageNet分类效果。Inception V3的weight数量小于VGG和ResNet,大小为96MB。
论文地址:https://arxiv.org/abs/1512.00567
Xception
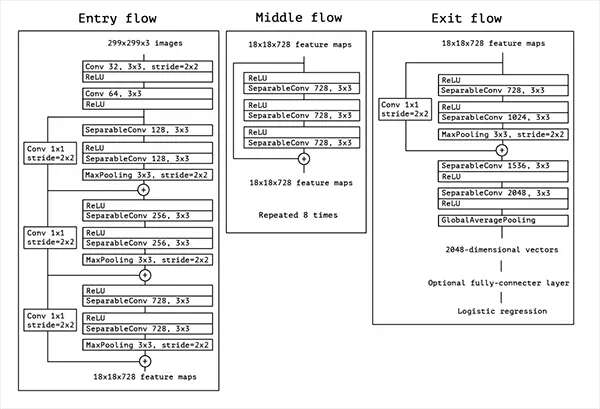
Xception是由Fran?ois Chollet本人(Keras维护者)提出的。Xception是Inception架构的扩展,它用深度可分离的卷积代替了标准的Inception模块。
原始论文“Xception: Deep Learning with Depthwise Separable Convolutions”在这里:
论文地址:https://arxiv.org/abs/1610.02357
Xception的weight数量最少,只有91MB。
至于说SqueezeNet?
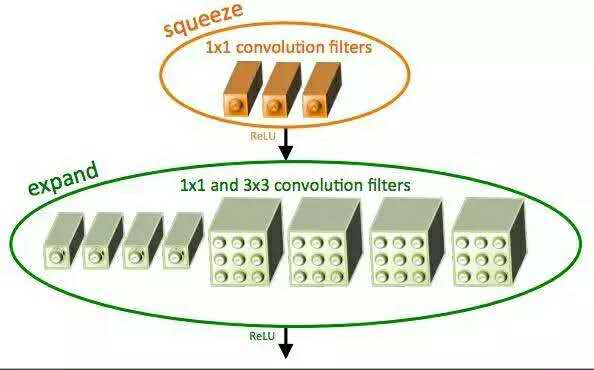
SqueezeNet架构通过使用squeeze卷积层和扩展层(1x1和3X3卷积核混合而成)组成的fire moule获得了AlexNet级精度,且模型大小仅4.9MB。
虽然SqueezeNet模型非常小,但其训练需要技巧。在我即将出版的书“深度学习计算机视觉与Python”中,详细说明了怎么在ImageNet数据集上从头开始训练SqueezeNet。
让我们学习如何使用Keras库中预训练的卷积神经网络模型进行图像分类吧。
新建一个文件,命名为classify_image.py,并输入如下代码:
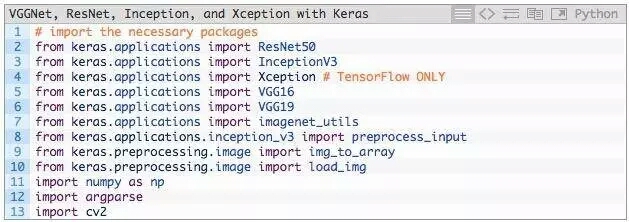
第2-13行的作用是导入所需Python包,其中大多数包都属于Keras库。
具体来说,第2-6行分别导入ResNet50,Inception V3,Xception,VGG16和VGG19。
需要注意,Xception网络只能用TensorFlow后端(如果使用Theano后端,该类会抛出错误)。
第7行,使用imagenet_utils模块,其有一些函数可以很方便的进行输入图像预处理和解码输出分类。
除此之外,还导入的其他辅助函数,其次是NumPy进行数值处理,cv2进行图像编辑。
接下来,解析命令行参数:
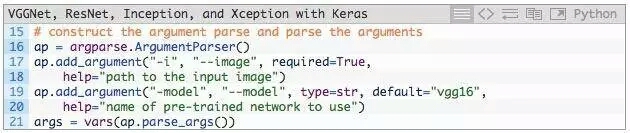
我们只需要一个命令行参数--image,这是要分类的输入图像的路径。
还可以接受一个可选的命令行参数--model,指定想要使用的预训练模型,默认使用vgg16。
通过命令行参数得到指定预训练模型的名字,我们需要定义一个Python字典,将模型名称(字符串)映射到其真实的Keras类。
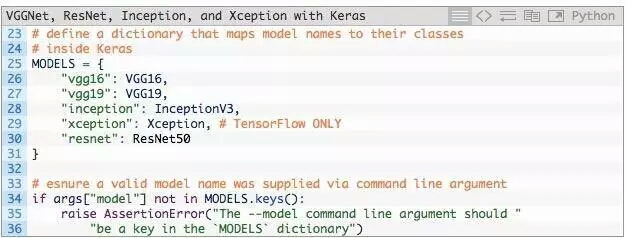
第25-31行定义了MODELS字典,它将模型名称字符串映射到相应的类。
如果在MODELS中找不到--model名称,将抛出AssertionError(第34-36行)。
卷积神经网络将图像作为输入,然后返回与类标签相对应的一组概率作为输出。
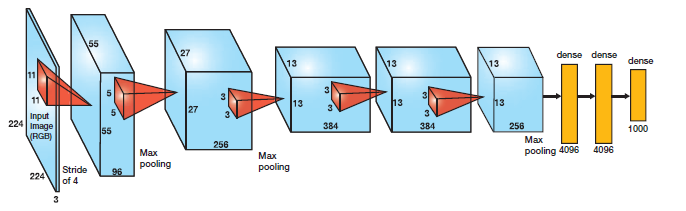
经典的CNN输入图像的尺寸,是224×224、227×227、256×256和299×299,但也可以是其他尺寸。
VGG16,VGG19和ResNet均接受224×224输入图像,而Inception V3和Xception需要299×299像素输入,如下面的代码块所示:
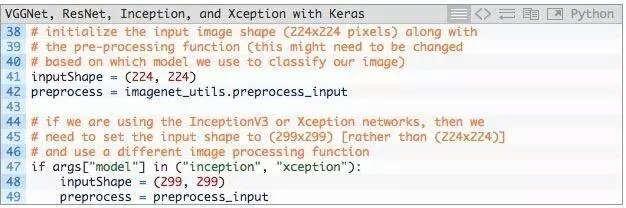
将inputShape初始化为224×224像素。我们还使用函数preprocess_input执行平均减法。
然而,如果使用Inception或Xception,我们需要把inputShape设为299×299像素,接着preprocess_input使用separate pre-processing function,图片可以进行不同类型的缩放。
下一步是从磁盘加载预训练的模型weight(权重)并实例化模型:
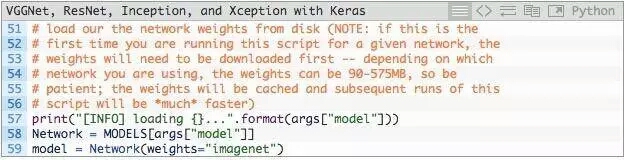
第58行,从--model命令行参数得到model的名字,通过MODELS词典映射到相应的类。
第59行,然后使用预训练的ImageNet权重实例化卷积神经网络。
注意:VGG16和VGG19的权重文件大于500MB。ResNet为?100MB,而Inception和Xception在90-100MB之间。如果是第一次运行此脚本,这些权重文件自动下载并缓存到本地磁盘。根据您的网络速度,这可能需要一些时间。然而,一旦权重文件被下载下来,他们将不需要重新下载,再次运行classify_image.py会非常快。
模型现在已经加载并准备好进行图像分类 - 我们只需要准备图像进行分类:
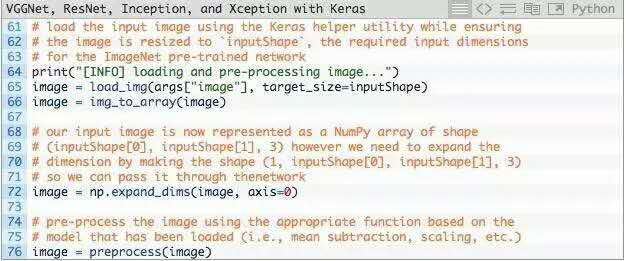
第65行,从磁盘加载输入图像,inputShape调整图像的宽度和高度。
第66行,将图像从PIL/Pillow实例转换为NumPy数组。
输入图像现在表示为(inputShape[0],inputShape[1],3)的NumPy数组。
第72行,我们通常会使用卷积神经网络分批对图像进行训练/分类,因此我们需要通过np.expand_dims向矩阵添加一个额外的维度(颜色通道)。
经过np.expand_dims处理,image具有的形状(1,inputShape[0],inputShape[1],3)。如没有添加这个额外的维度,调用.predict会导致错误。
最后,第76行调用相应的预处理功能来执行数据归一化。
经过模型预测后,并获得输出分类:
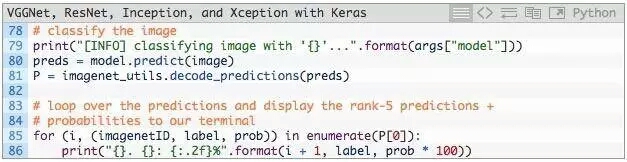
第80行,调用CNN中.predict得到预测结果。根据这些预测结果,将它们传递给ImageNet辅助函数decode_predictions,会得到ImageNet类标签名字(id转换成名字,可读性高)以及与标签相对应的概率。
然后,第85行和第86行将前5个预测(即具有最大概率的标签)输出到终端 。
在我们结束示例之前,我们将在此处执行的最后一件事情,通过OpenCV从磁盘加载我们的输入图像,在图像上绘制#1预测,最后将图像显示在我们的屏幕上:
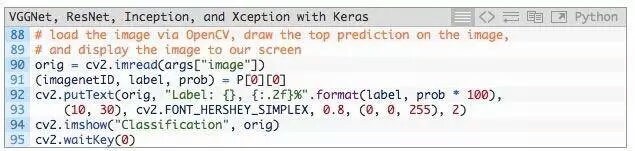
查看预训练模型的实际运行,请看下节。
这篇博文中的所有示例都使用Keras>=2.0和TensorFlow后端。如果使用TensorFlow,请确保使用版本>=1.0,否则将遇到错误。我也用Theano后端测试了这个脚本,并确认可以使用Theano。
安装TensorFlow/Theano和Keras后,点击底部的源代码+示例图像链接就可下载。
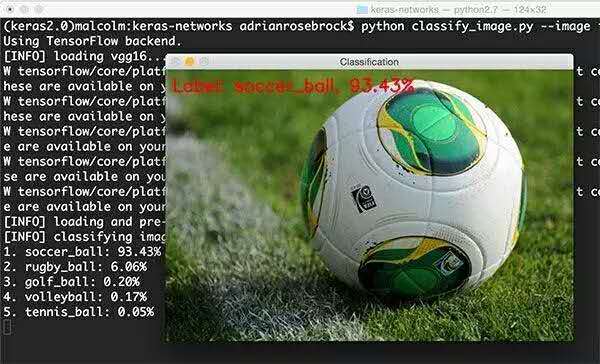
现在我们可以用VGG16对图像进行分类:
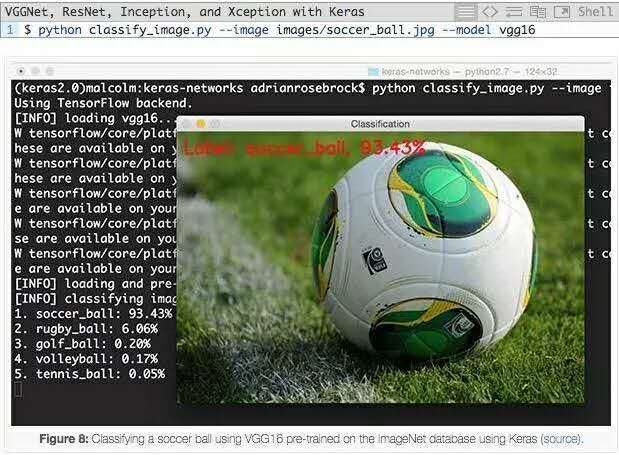
我们可以看到VGG16正确地将图像分类为“足球”,概率为93.43%。
要使用VGG19,我们只需要更改--network命令行参数:
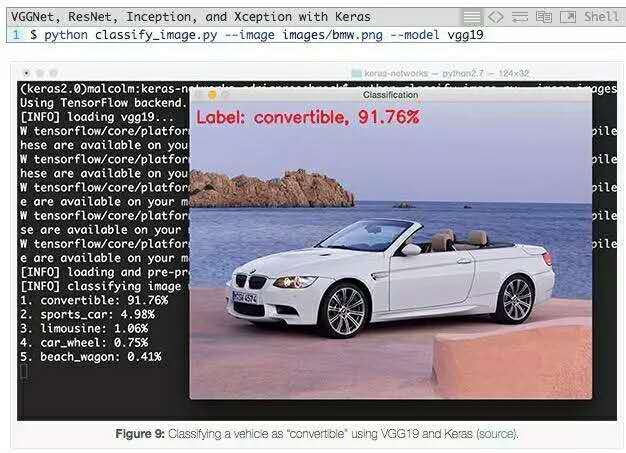
VGG19能够以91.76%的概率将输入图像正确地分类为“convertible”。看看其他top-5预测:“跑车”的概率为4.98%(其实是轿车),“豪华轿车”为1.06%(虽然不正确但看着合理),“车轮”为0.75%(从模型角度来说也是正确的,因为图像中有车轮)。
在以下示例中,我们使用预训练ResNet架构,可以看下top-5概率值:
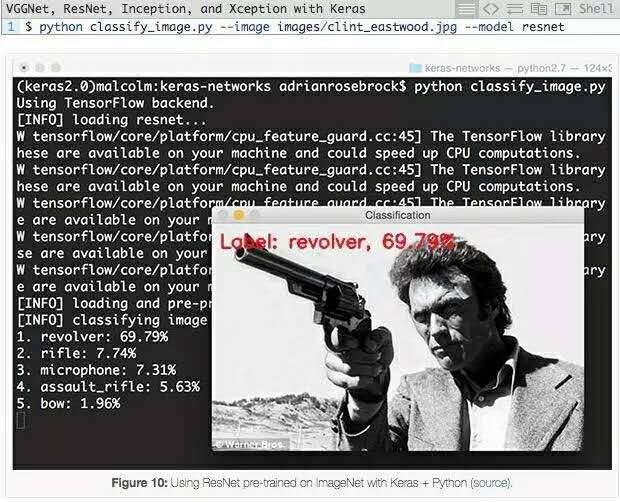
ResNet正确地将ClintEastwood持枪图像分类为“左轮手枪”,概率为69.79%。在top-5中还有,“步枪”为7.74%,“冲锋枪”为5.63%。由于"左轮手枪"的视角,枪管较长,CNN很容易认为是步枪,所以得到的步枪也较高。
下一个例子用ResNet对狗的图像进行分类:
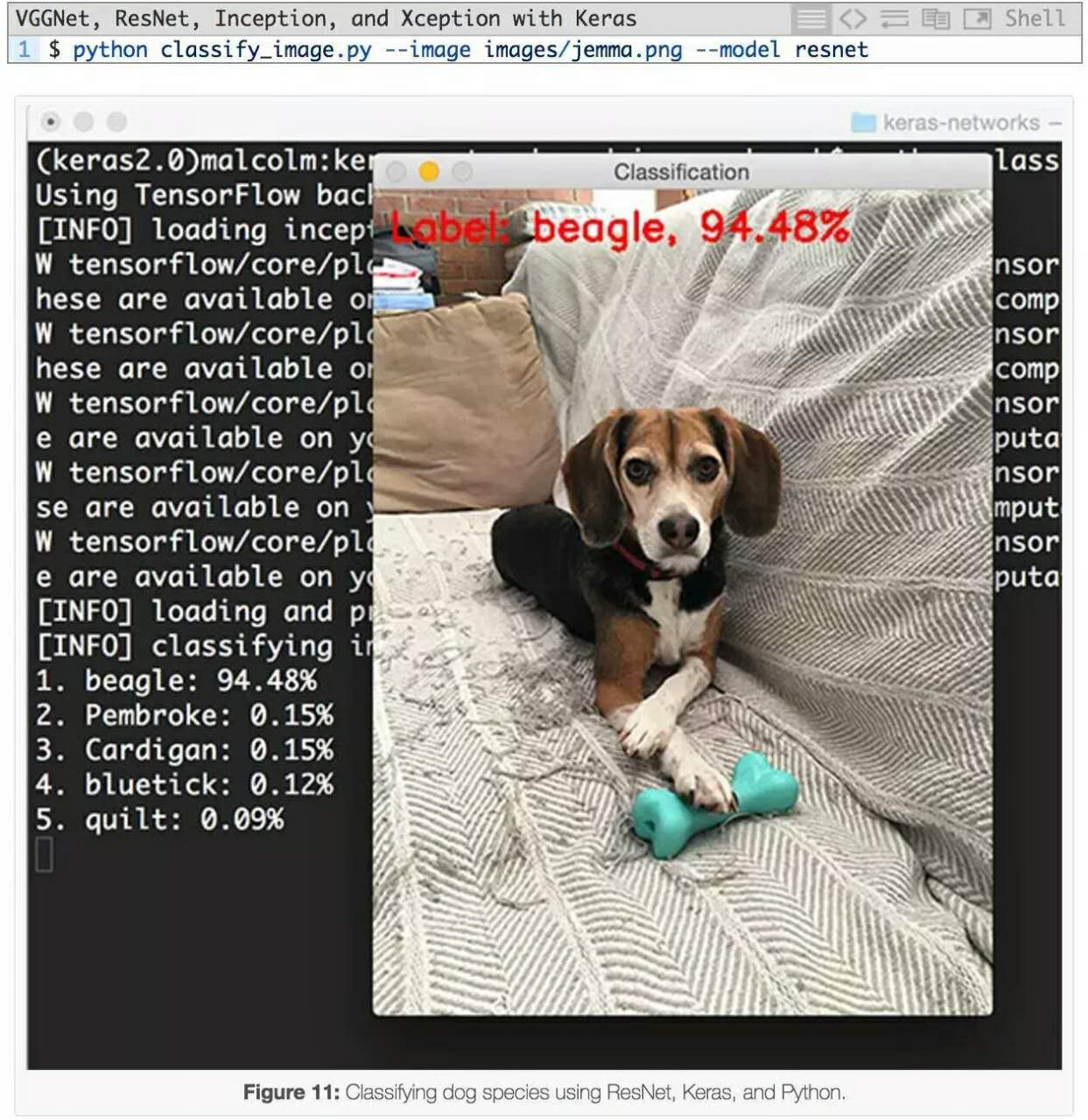
狗的品种被正确识别为“比格犬”,具有94.48%的概率。
然后,我尝试从这个图像中分出《加勒比海盗》演员约翰尼?德普:
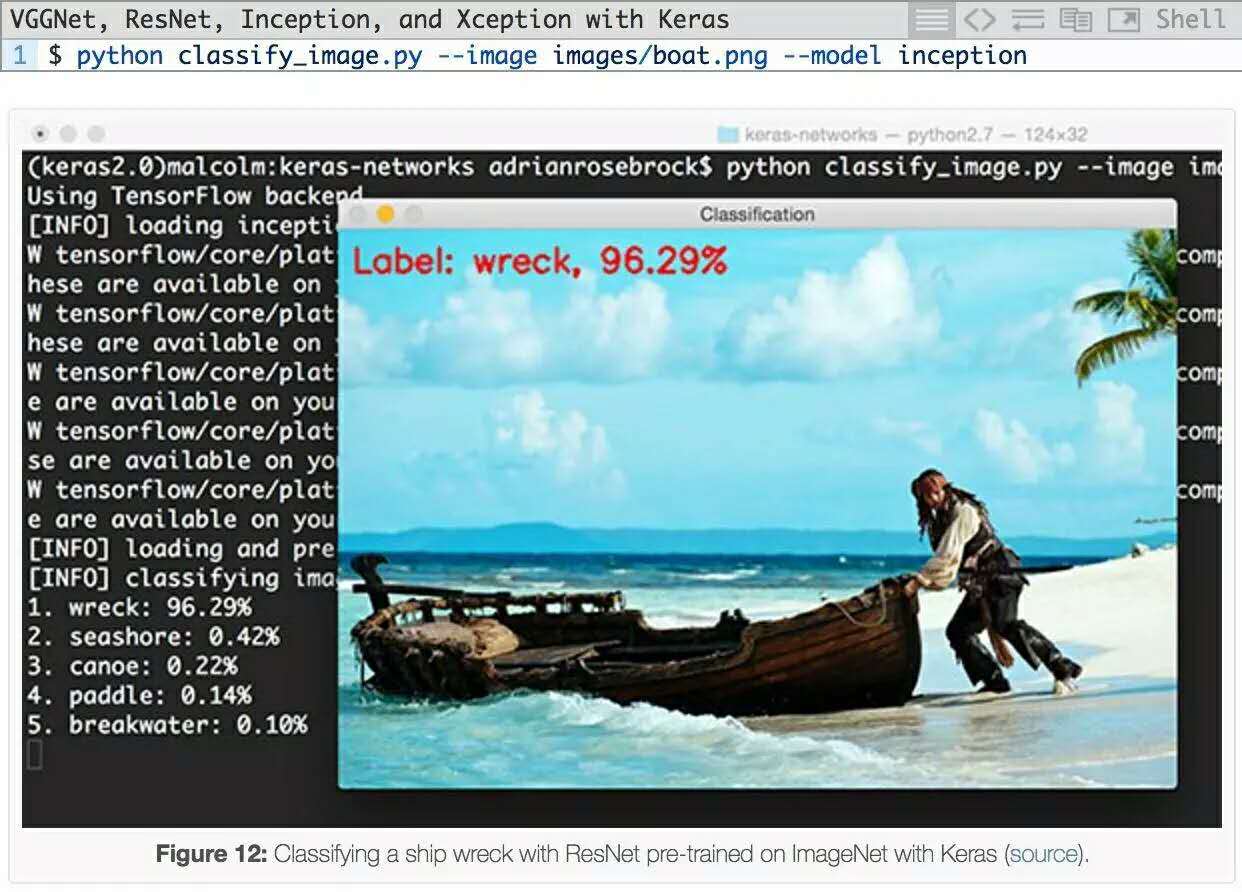
虽然ImageNet中确实有一个“船”类,但有趣的是,Inception网络能够正确地将场景识别为“(船)残骸”,且有具有96.29%概率的。所有其他预测标签,包括 “海滨”,“独木舟”,“桨”和“防波堤”都是相关的,在某些情况下也是绝对正确的。
对于Inception网络的另一个例子,我给办公室的沙发拍摄了照片:
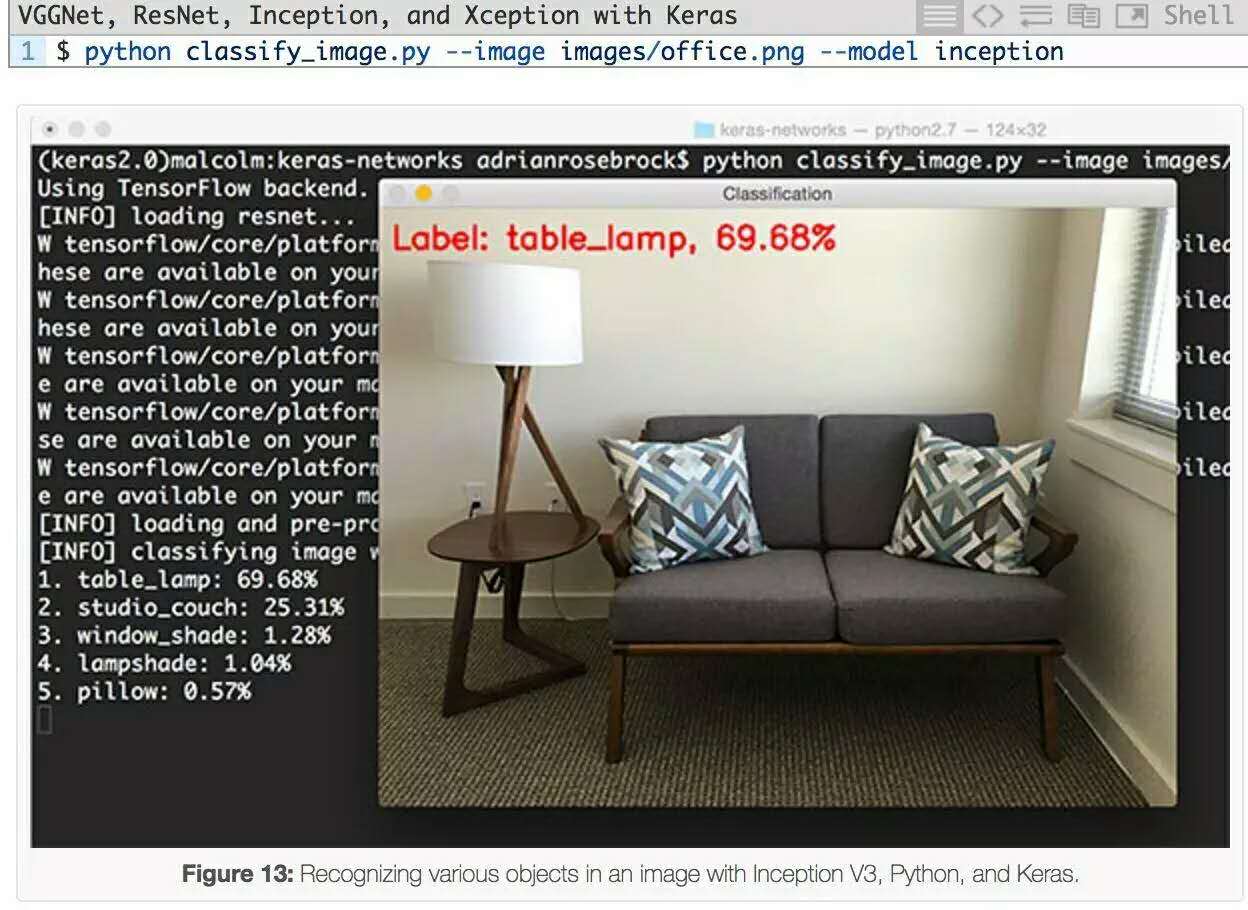
Inception正确地预测出图像中有一个“桌灯”,概率为69.68%。其他top-5预测也是完全正确的,包括“工作室沙发”、“窗帘”(图像的最右边,几乎不显眼)“灯罩”和“枕头”。
Inception虽然没有被用作对象检测器,但仍然能够预测图像中的前5个对象。卷积神经网络可以做到完美的对物体进行识别!
再来看下Xception:
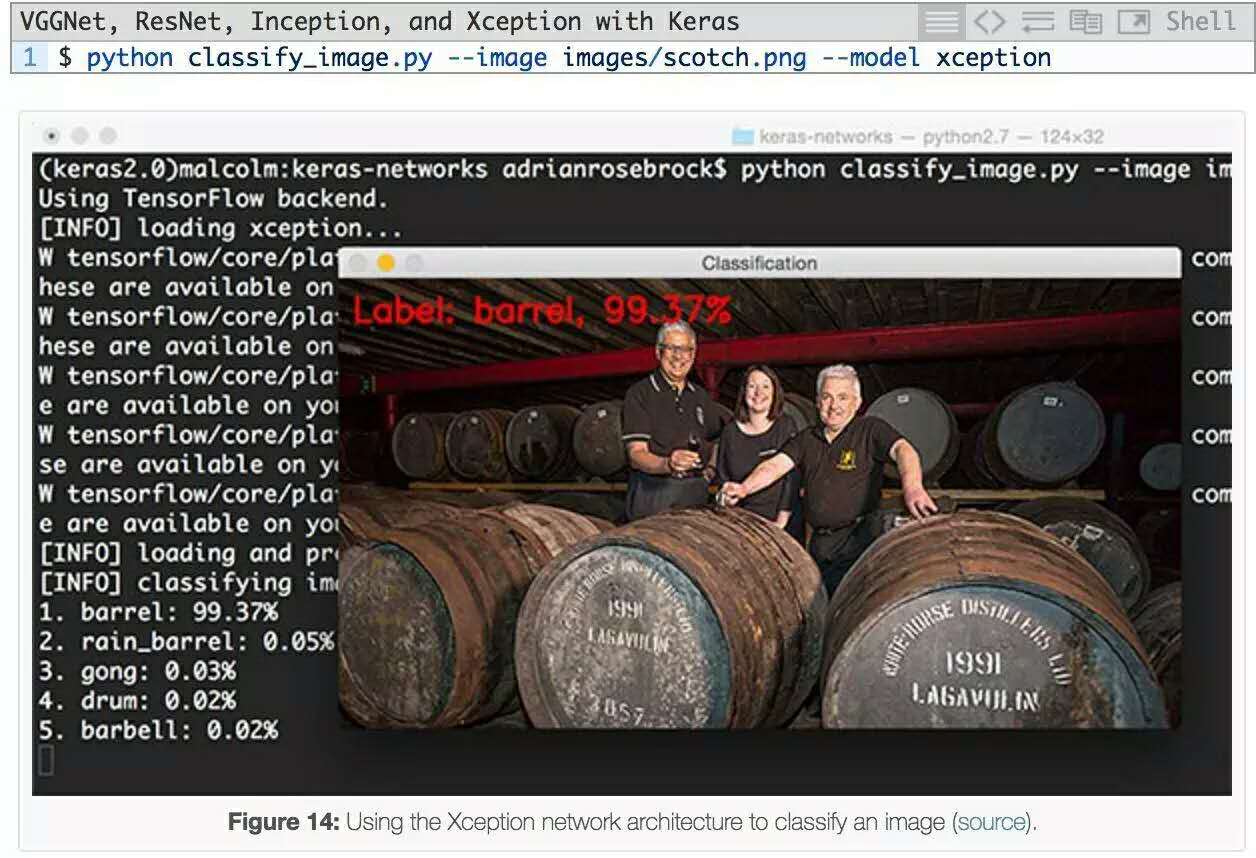
这里我们有一个苏格兰桶的图像,尤其是我最喜欢的苏格兰威士忌,拉加维林。Xception将此图像正确地分类为 “桶”。
最后一个例子是使用VGG16进行分类:
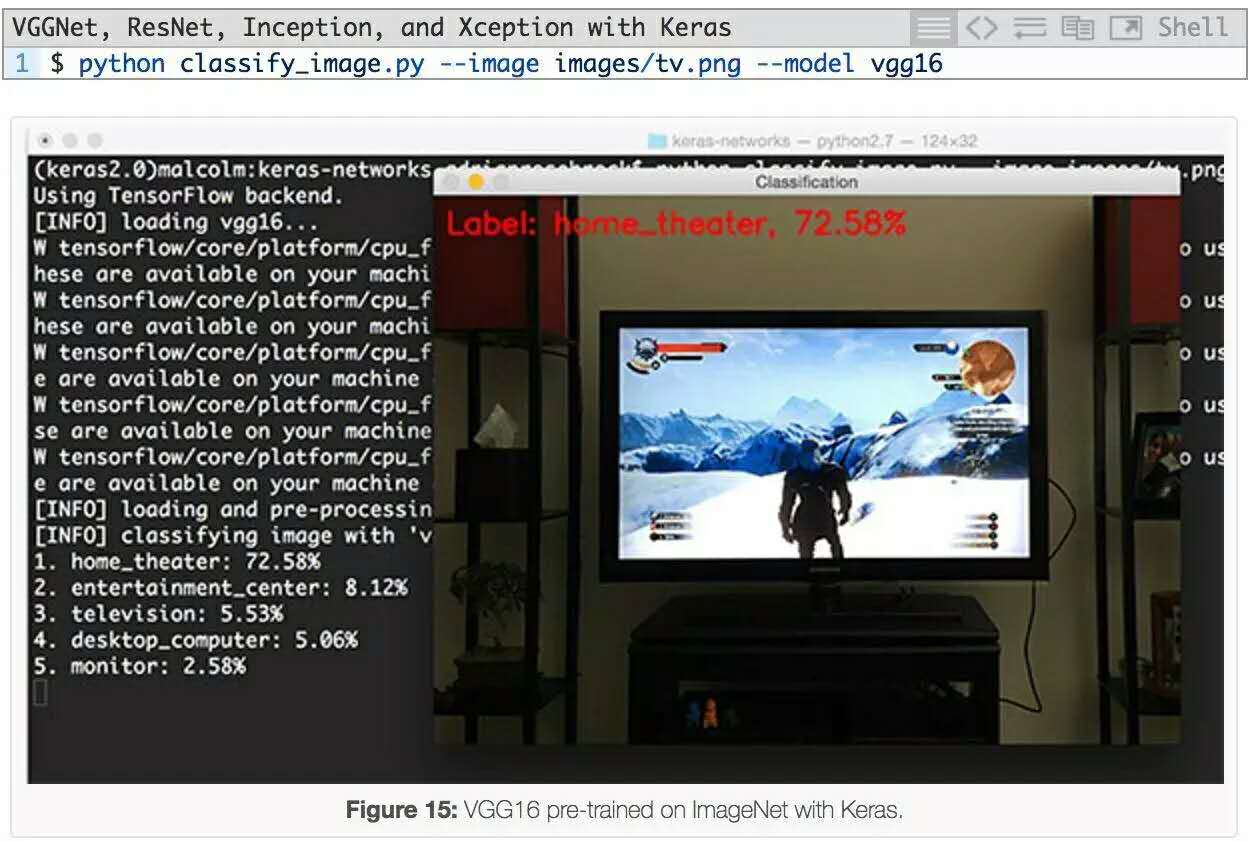
几个月前,当我打完《巫师 III》(The Wild Hunt)这局游戏之后,我给显示器照了这个照片。VGG16的第一个预测是“家庭影院”,这是一个合理的预测,因为top-5预测中还有一个“电视/监视器”。
从本文章的示例可以看出,在ImageNet数据集上预训练的模型能够识别各种常见的日常对象。你可以在你自己的项目中使用这个代码!
简单回顾一下,在今天的博文中,我们介绍了在Keras中五个卷积神经网络模型:
VGG16
VGG19
ResNet50
Inception V3
Xception
此后,我演示了如何使用这些神经网络模型来分类图像。希望本文对你有帮助。
原文地址:
http://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception...