英文分词可以使用空格,中文就不同了,一些分词的原理后面再来说,先说下python中常用的jieba这个工具。
首先要注意自己在做练习时不要使用jieba.Py命名文件,否则会出现
jieba has no attribute named cut …等这些,如果删除了自己创建的jieba.py还有错误是因为没有删除jieba.pyc文件。
(1)基本分词函数和用法
首先介绍下分词的三种模式:
精确模式:适合将句子最精确的分开,适合文本分析;
全模式:把句子中所有可以成词的词语都扫描出来,速度快,但是不能解决歧义;
搜索引擎模式:在精确模式的基础上,对长词再次进行切分,提高召回率,适用于搜索引擎分词;
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语
jieba.cut 方法接受三个输入参数:
- 需要分词的字符串
- cut_all 参数用来控制是否采用全模式
- HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数
- 需要分词的字符串
- 是否使用 HMM 模型。

1 import jieba 2 seg_list = jieba.cut("我爱学习自然语言处理", cut_all=True) 3 print("Full Mode: " + "/ ".join(seg_list)) # 全模式 4 5 seg_list = jieba.cut("我爱自然语言处理", cut_all=False) 6 print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 7 8 seg_list = jieba.cut("他毕业于上海交通大学,在百度深度学习研究院进行研究") # 默认是精确模式 9 print(", ".join(seg_list)) 10 11 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") # 搜索引擎模式 12 print(", ".join(seg_list))

jieba.lcut以及jieba.lcut_for_search直接返回 list

1 import jieba 2 result_lcut = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") 3 result_lcut_for_search = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造",cut_all=True) 4 print (‘result_lcut:‘,result_lcut) 5 print (‘result_lcut_for_search:‘,result_lcut_for_search) 6 7 print (" ".join(result_lcut)) 8 print (" ".join(result_lcut_for_search))

添加用户自定义字典:
很多时候我们需要针对自己的场景进行分词,会有一些领域内的专有词汇。
- 1.可以用jieba.load_userdict(file_name)加载用户字典
- 2.少量的词汇可以自己用下面方法手动添加:
- 用 add_word(word, freq=None, tag=None) 和 del_word(word) 在程序中动态修改词典
- 用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
1 import jieba 2 result_cut=jieba.cut(‘如果放到旧字典中将出错。‘, HMM=False) 3 print(‘/‘.join(result_cut)) 4 jieba.suggest_freq((‘中‘, ‘将‘), True) 5 result_cut=jieba.cut(‘如果放到旧字典中将出错。‘, HMM=False) 6 print(‘/‘.join(result_cut))
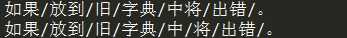
(2)关键词提取
基于TF-IDF的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选