facenet 代码阅读笔记:如何训练基于triplet-loss的模型
facenet是一个基于tensorflow的人脸识别代码,它实现了基于center-loss+softmax-loss 和 tripletloss两种训练方法,两者的上层的网络结构可以是一样的,主要区别在于最后的loss的计算,center-loss+softmax-loss的实现方法相对来说比较好理解一些,而triplet-loss则比较复杂,具体的思想可以参考https://arxiv.org/abs/1503.03832,这里整理一下facenet中是如何基于triplet-loss进行训练的。
一. 如何选择一个三元组
从论文中可以知道,triplet-loss优化的目的是使得同一个人的embedding距离尽可能近,不同的人之间embedding尽可能远。如下图所示:
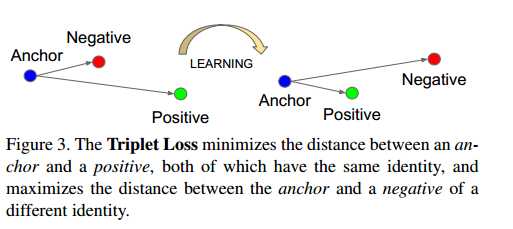
选择一张图片作为anchor,Positive是跟anchor同一个人的,Negative是跟anchor不一样的人的,那我们希望通过学习使得anchor与positive的距离近一些,与negative的距离远一些,我这里直接将这样的三张图片的组合称为三元组。
对于整个训练数据集,希望模型能达到以下效果
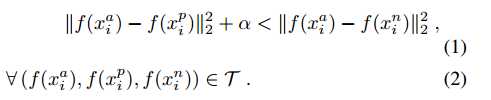
那么loss就可以定义为
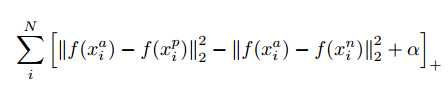
对于整个数据集来说,这样的三元组的数量是非常多的,假设总共有N张图片,每个人有K张图,那么数量级大概是N*N*K, 而且这些组合当中有一些是非常容易满足上述条件的,那么对于优化的意义不大,所以应该通过更加合理的方式来选择这样的三元组。

如论文中所说,我们应该选择违背上述条件最严重的组合(有点像SVM吧。。。),是否违背上述条件是要通过计算图片之间的embedding的欧式距离得到,但是embedding又是不断在优化更新,也就是说违背条件最严重的组合是有可能不断变化的,如果每次更新都重新选择一次,那么对训练效率会有很大影响。文中提到了两种替代的方案:

一是每经过特定的迭代次数,选用最新的checkpoint,在一个训练数据子集上面选择一次三元组。
二是一种在线方法,每训练一次minibatch,选择一次三元组。
而facenet中选用的就是第二种,这样训练的思路就很清晰了,在一个minibatch中,我们根据当时的embedding,选择一次三元组,在这些三元组上计算triplet-loss, 再对embedding进行更新,不断重复,直到收敛或训练到指定迭代次数。那接下来就看一下facenet中是怎么具体操作的。
1. 首先,每次minibatch开始的时候,facenet会从训练数据集中抽样出一组图片。
#从数据集中进行抽样图片,参数为训练数据集,每一个batch抽样多少人,每个人抽样多少张 def sample_people(dataset, people_per_batch, images_per_person): #总共应该抽样多少张 nrof_images = people_per_batch * images_per_person #数据集中一共有多少人的图像 nrof_classes = len(dataset) #每个人的索引 class_indices = np.arange(nrof_classes) #随机打乱一下 np.random.shuffle(class_indices) i = 0 #保存抽样出来的图像的路径 image_paths = [] #抽样的样本是属于哪一个人的,作为label num_per_class = [] sampled_class_indices = [] # Sample images from these classes until we have enough # 不断抽样直到达到指定数量 while len(image_paths)<nrof_images: #从第i个人开始抽样 class_index = class_indices[i] #第i个人有多少张图片 nrof_images_in_class = len(dataset[class_index]) #这些图片的索引 image_indices = np.arange(nrof_images_in_class) np.random.shuffle(image_indices) #从第i个人中抽样的图片数量 nrof_images_from_class = min(nrof_images_in_class, images_per_person, nrof_images-len(image_paths)) idx = image_indices[0:nrof_images_from_class] #抽样出来的人的路径 image_paths_for_class = [dataset[class_index].image_paths[j] for j in idx] #图片的label sampled_class_indices += [class_index]*nrof_images_from_class image_paths += image_paths_for_class #第i个人抽样了多少张 num_per_class.append(nrof_images_from_class) i+=1 return image_paths, num_per_class
然后就会计算这些anchor图片在当时的网络模型中得到的embedding,保存在emb_array当中,那么根据得到的emb_array,就可以通过计算图片的embedding之间的欧式距离得到三元组了。
#多少人,alpha参数 def select_triplets(embeddings, nrof_images_per_class, image_paths, people_per_batch, alpha): """ Select the triplets for training """ trip_idx = 0 #某个人的图片的embedding在emb_arr中的开始的索引 emb_start_idx = 0 num_trips = 0 triplets = [] # VGG Face: Choosing good triplets is crucial and should strike a balance between # selecting informative (i.e. challenging) examples and swamping training with examples that # are too hard. This is achieve by extending each pair (a, p) to a triplet (a, p, n) by sampling # the image n at random, but only between the ones that violate the triplet loss margin. The # latter is a form of hard-negative mining, but it is not as aggressive (and much cheaper) than # choosing the maximally violating example, as often done in structured output learning. #遍历每一个人 for i in xrange(people_per_batch): #这个人有多少张图片 nrof_images = int(nrof_images_per_class[i]) #遍历第i个人的所有图片 for j in xrange(1,nrof_images): #第j张图的embedding在emb_arr 中的位置 a_idx = emb_start_idx + j - 1 #第j张图跟其他所有图片的欧氏距离 neg_dists_sqr = np.sum(np.square(embeddings[a_idx] - embeddings), 1) #遍历每一对可能的(anchor,postive)图片,记为(a,p)吧 for pair in xrange(j, nrof_images): # For every possible positive pair. #第p张图片在emb_arr中的位置 p_idx = emb_start_idx + pair #(a,p)之前的欧式距离 pos_dist_sqr = np.sum(np.square(embeddings[a_idx]-embeddings[p_idx])) #同一个人的图片不作为negative,所以将距离设为无穷大 neg_dists_sqr[emb_start_idx:emb_start_idx+nrof_images] = np.NaN #all_neg = np.where(np.logical_and(neg_dists_sqr-pos_dist_sqr<alpha, pos_dist_sqr<neg_dists_sqr))[0] # FaceNet selection #其他人的图片中有哪些图片与a之间的距离-p与a之间的距离小于alpha的 all_neg = np.where(neg_dists_sqr-pos_dist_sqr<alpha)[0] # VGG Face selecction #所有可能的negative nrof_random_negs = all_neg.shape[0] #如果有满足条件的negative if nrof_random_negs>0: #从中随机选取一个作为n rnd_idx = np.random.randint(nrof_random_negs) n_idx = all_neg[rnd_idx] # 选到(a,p,n)作为三元组 triplets.append((image_paths[a_idx], image_paths[p_idx], image_paths[n_idx])) #print(‘Triplet %d: (%d, %d, %d), pos_dist=%2.6f, neg_dist=%2.6f (%d, %d, %d, %d, %d)‘ % # (trip_idx, a_idx, p_idx, n_idx, pos_dist_sqr, neg_dists_sqr[n_idx], nrof_random_negs, rnd_idx, i, j, emb_start_idx)) trip_idx += 1 num_trips += 1 emb_start_idx += nrof_images np.random.shuffle(triplets) return triplets, num_trips, len(triplets)
然后根据得到的三元组就可以计算triplet-loss,优化参数,更新embedding,不断重复这个过程。下面是其他一些细节。
2.facenet的网络结构
facenet中有两个选择,一个是inception_resnet_v1,一个是inception_resnet_v2
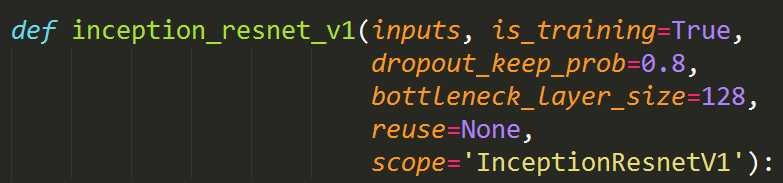
他们的参数如图所示,跟普通的网络结构一样,它的输入是图片,bottleneck_layer_size 是最后一层全连接层输出的大小,也就是对于每张人脸提取的特征的维度。
三.构造计算图
# 构造计算图,prelogits为最后一层的输出 prelogits, _ = network.inference(image_batch, args.keep_probability, phase_train=phase_train_placeholder, bottleneck_layer_size=args.embedding_size, weight_decay=args.weight_decay) # 对最后的输出进行标准化,即为该图像的embedding embeddings = tf.nn.l2_normalize(prelogits, 1, 1e-10, name=‘embeddings‘) # Split embeddings into anchor, positive and negative and calculate triplet loss # 将输出的embeddings分为anchor,正样本, 负样本三个部分 anchor, positive, negative = tf.unstack(tf.reshape(embeddings, [-1,3,args.embedding_size]), 3, 1) #根据上面三个部分计算triplet-loss triplet_loss = facenet.triplet_loss(anchor, positive, negative, args.alpha) #定义优化方法 learning_rate = tf.train.exponential_decay(learning_rate_placeholder, global_step, args.learning_rate_decay_epochs*args.epoch_size, args.learning_rate_decay_factor, staircase=True) tf.summary.scalar(‘learning_rate‘, learning_rate) # Calculate the total losses # 加入正则化损失 regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES) # 整体的损失即为triplet-loss+正则损失 total_loss = tf.add_n([triplet_loss] + regularization_losses, name=‘total_loss‘) # Build a Graph that trains the model with one batch of examples and updates the model parameters # 用上述定义的优化方法和loss进行优化 train_op = facenet.train(total_loss, global_step, args.optimizer, learning_rate, args.moving_average_decay, tf.global_variables())
其他一些细节之后再继续补充:)