大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述
1‘ DFS
分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。该系统架构于网络之上,势必会引入网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂。
2‘ HDFS
借此,关于GFS和HDFS的区别与联系查看 我于博客园找到的前辈的博客>>http://www.cnblogs.com/liango/p/7136448.html
HDFS(Hadoop Distributed File System)为大数据平台其它所有组件提供了最基本的存储功能。
特征:高容错、高可靠、可扩展、高吞吐率等,为大数据存储和处理提供了强大的底层存储架构。
HDFS是一个主/从(master/slave)体系结构,从最终用户的角度来看,它就像传统的文件系统,可通过目录路径对文件执行CRUD操作。由于其分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNodes,NameNode管理文件系统的元数据,DataNode存储实际的数据。
HDFS开放文件系统的命名空间以便用户以文件形式存储数据,秉承“一次写入、多次读取”的原则。客户端通过NameNode和DataNodes的交互访问文件系统,联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
3‘ 适用场景
HDFS 提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序,以下是一些常用的应用场景:
数据密集型并行计算:数据量极大,但是计算相对简单的并行处理,如大规模Web信息搜索;
计算密集型并行计算:数据量相对不是很大,但是计算较为复杂的并行计算,如3D建模与渲染、气象预报和科学计算;
数据密集与计算密集混合型的并行计算,如3D电影的渲染。
HDFS在使用过程中有以下限制:
HDFS不适合大量小文件的存储,因NameNode将文件系统的元数据存放在内存中,因此存储的文件数目受限于NameNode的内存大小;
HDFS适用于高吞吐量,而不适合低时间延迟的访问;
流式读取的方式,不适合多用户写入一个文件(一个文件同时只能被一个客户端写),以及任意位置写入(不支持随机写);
HDFS更加适合写入一次,读取多次的应用场景。
3’ 基本命令
格式: hadoop fs -cmd args 其中,cmd为具体的操作,args为参数
常用命令:
hadoop fs -mkdir /user/trunk #建立目录/user/trunk
hadoop fs -ls /user #查看/user目录下的目录和文件
hadoop fs -lsr /user #递归查看/user目录下的目录和文件
hadoop fs -put test.txt /user/trunk #上传test.txt文件至/user/trunk
hadoop fs -get /user/trunk/test.txt #获取/user/trunk/test.txt文件
hadoop fs -cat /user/trunk/test.txt #查看/user/trunk/test.txt文件内容
hadoop fs -tail /user/trunk/test.txt #查看/user/trunk/test.txt文件的最后1000行
hadoop fs -rm /user/trunk/test.txt #删除/user/trunk/test.txt文件
hadoop fs -help ls #查看ls命令的帮助文档
二 HDFS部署
主要步骤如下:
1. 配置Hadoop的安装环境;
2. 配置Hadoop的配置文件;
3. 启动HDFS服务;
4. 验证HDFS服务可用。
1‘ 查看是否存在hadoop安装目录 ls /usr/cstor/hadoop 如果没有,利用 工具从本地导入hadoop安装文件。
工具从本地导入hadoop安装文件。

查看jdk是否存在,如果没有同上方法导入

2’ 确认集群服务器之间可SSH免密登录
使用ssh工具登录到每一台服务器,执行命令ssh 主机名,确认每台集群服务器均可SSH免密登录。方法查看我的博客 >> http://www.cnblogs.com/1996swg/p/7270728.html
3‘  查看hadoop_env.sh 文件,此文件只需修改JAVA_HOME
查看hadoop_env.sh 文件,此文件只需修改JAVA_HOME
用vim编辑器修改此文件,将export JAVA_HOME=${JAVA_HOME}改为jdk的目录,例如在我的电脑上是export JAVA_HOME=/usr/local/jdk1.7.0_79/
4’ 指定HDFS主节点
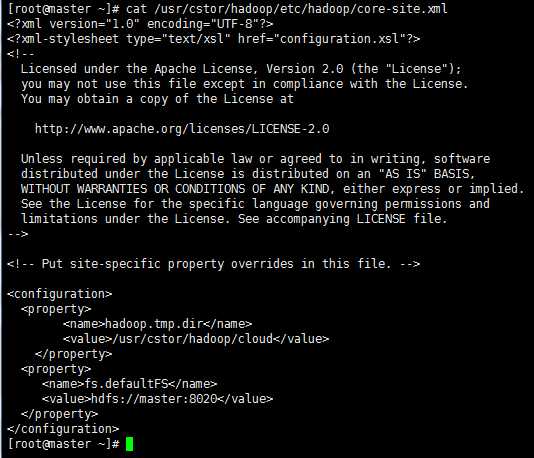
此处需要配置文件 core-site.xml ,查看该文件,并<configuration></configuration>标签之间修改如图所示的配置:
5‘ 拷贝该配置到集群其他子集上,首先查看你的集群所有子集
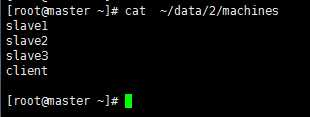
输入命令 for x in `cat ~/data/2/machines` ; do echo $x ; scp -r /usr/cstor/hadoop/etc $x:/usr/cstor/hadoop ; done; 实现拷贝
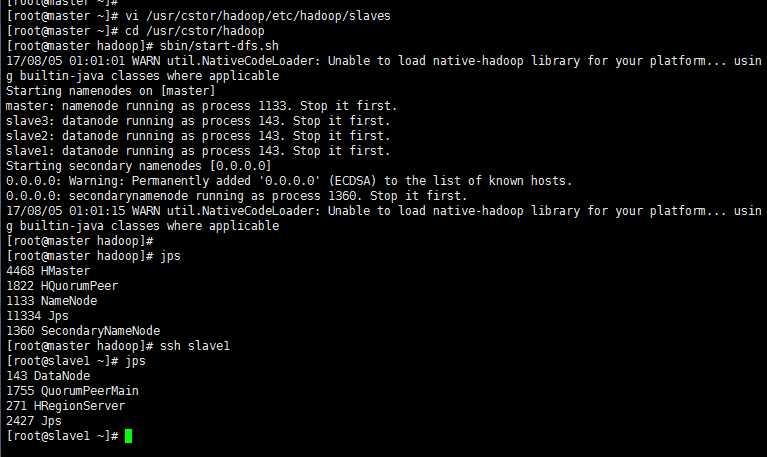
6’ 启动HDFS节点
首先在master服务器上格式化主节点 hdfs namenode -format
其次配置slaves文件,将localhost修改为slave1~3;
最后在hadoop安装目录下统一启动HDFS;
用jps 命令在各个子集检验是否启动节点成功;
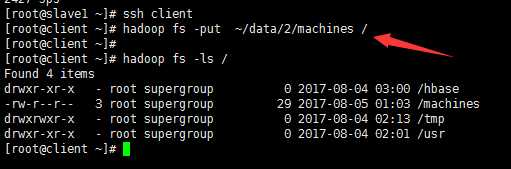
7‘ hdfs配置成功后可以在client上向HDFS上传文件:
三 读写HDFS文件
1’ 配置client服务器classpath
(1) 使用ssh工具登录client服务器,执行命令vi /etc/profile,编辑该文件。Linux 中/etc/profile文件的改变会涉及到系统的环境,也就是有关Linux环境变量。
修改设置Classpath的目的,在于告诉Java执行环境,在哪些目录下可以找到您所要执行的Java程序(.class文件)。
将末尾的如下几行:
JAVA_HOME=/usr/local/jdk1.7.0_79/
export JRE_HOME=/usr/local/jdk1.7.0_79//jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/usr/cstor/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
用下列行进行替换(注意路径不同自行修改):
JAVA_HOME=/usr/local/jdk1.7.0_79/
export HADOOP_HOME=/usr/cstor/hadoop
export JRE_HOME=/usr/local/jdk1.7.0_79//jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
(2) 执行命令source /etc/profile,使刚才的环境变量修改生效;
2’ 在client服务器编写HDFS写程序
(1)在client服务器上执行命令vi WriteFile.java,编写HDFS写文件程序:


1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.FSDataOutputStream; 3 import org.apache.hadoop.fs.FileSystem; 4 import org.apache.hadoop.fs.Path; 5 public class WriteFile { 6 public static void main(String[] args)throws Exception{ 7 Configuration conf=new Configuration(); 8 FileSystem hdfs = FileSystem.get(conf); 9 Path dfs = new Path("/weather.txt"); 10 FSDataOutputStream outputStream = hdfs.create(dfs); 11 outputStream.writeUTF("nj 20161009 23\n"); 12 outputStream.close(); 13 } 14 }
(2)编译并打包HDFS写程序
使用javac编译刚刚编写的代码,并使用jar命令打包为hdpAction.jar
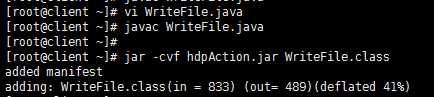
(3)执行HDFS写程序
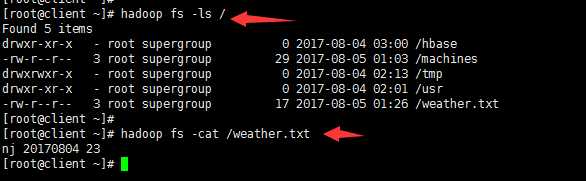
在client服务器上使用hadoop jar命令执行hdpAction.jar:

查看是否已生成weather.txt文件,若已生成,则查看文件内容是否正确:
3‘ 在client服务器编写HDFS读程序
(1)在client服务器上执行命令vi ReadFile.java,编写HDFS读WriteFile.txt文件程序:
1 import java.io.IOException; 2 3 import org.apache.Hadoop.conf.Configuration; 4 import org.apache.Hadoop.fs.FSDataInputStream; 5 import org.apache.Hadoop.fs.FileSystem; 6 import org.apache.Hadoop.fs.Path; 7 8 public class ReadFile { 9 public static void main(String[] args) throws IOException { 10 Configuration conf = new Configuration(); 11 Path inFile = new Path("/weather.txt"); //读取WriteFile.txt文件 12 FileSystem hdfs = FileSystem.get(conf); 13 FSDataInputStream inputStream = hdfs.open(inFile); 14 System.out.println("myfile: " + inputStream.readUTF()); 15 inputStream.close(); 16 } 17 }
(2)编译文件并打包,然后执行;
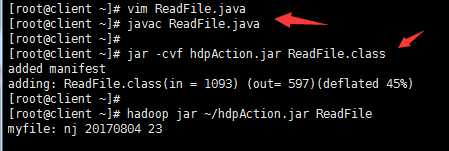
四 配置eclipase Hadoop插件并进行打包上传
1’ 首先下载eclipse hadoop插件,解压为jar文件 ,将其放置在eclipse文件位置的plugins文件夹下,例如D:\eclipse-standard-kepler-SR2-win32\eclipse\plugins
,将其放置在eclipse文件位置的plugins文件夹下,例如D:\eclipse-standard-kepler-SR2-win32\eclipse\plugins
2‘ 配置本地的hadoop环境,需下载hadoop组件(到阿帕奇下吧^_^,http://hadoop.apache.org/),解压为
3‘ 打开eclipase新建project查看是否已经有Map/Reduce Project的选项。第一次新建Map/Reduce项目时,需要指定hadoop解压后的位置(即第二部组件解压的位置),在新建时项目填写界面右中间有hadoop的路径填写;
4’ 编写java文件,例如上述的ReadFile.java
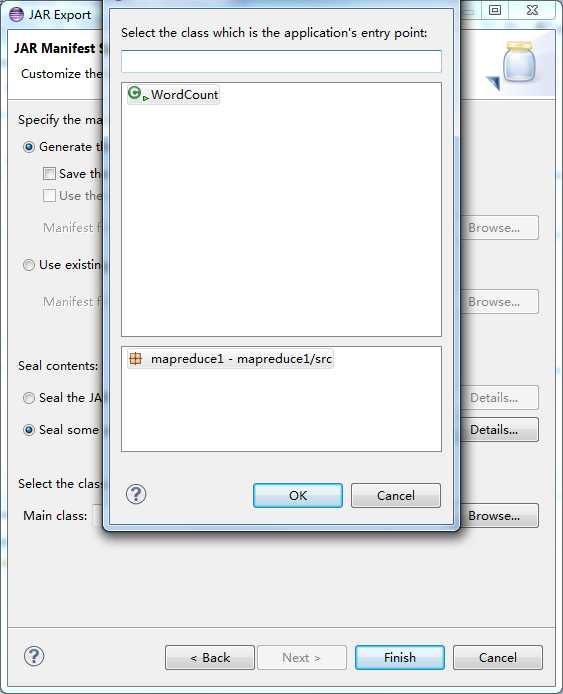
5‘ 打包成jar文件,右击项目的export的jar file,然后选择所需的文件打包成jar文件,(此步骤是重点)
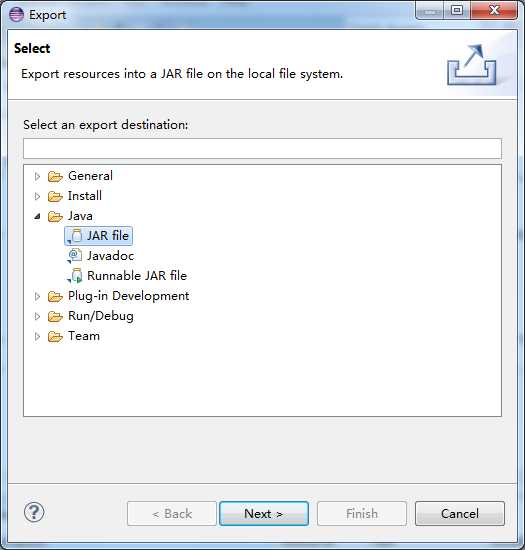 >>>>>>
>>>>>>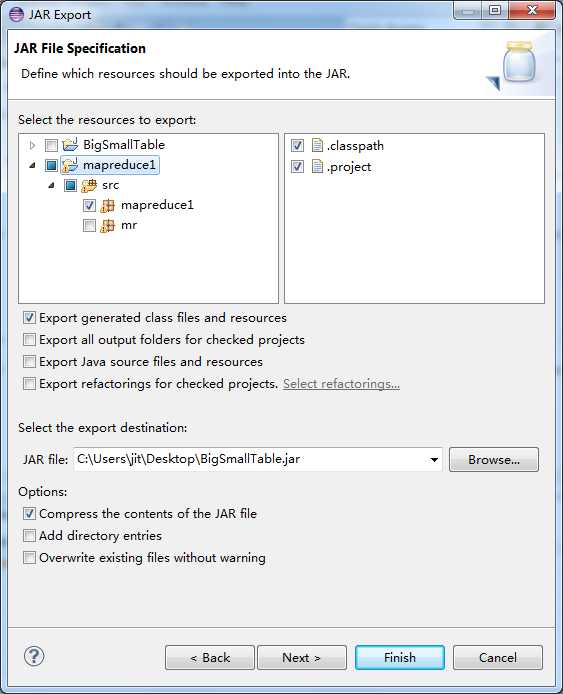 >>>>>>
>>>>>>
6’ 使用WinSCP、XManager或其它SSH工具的sftp工具上传刚刚生成的hdpAction.jar包至client服务器(我用的是 工具),并在client服务器上使用hadoop jar命令执行hdpAction.jar,查看程序运行结果。
工具),并在client服务器上使用hadoop jar命令执行hdpAction.jar,查看程序运行结果。
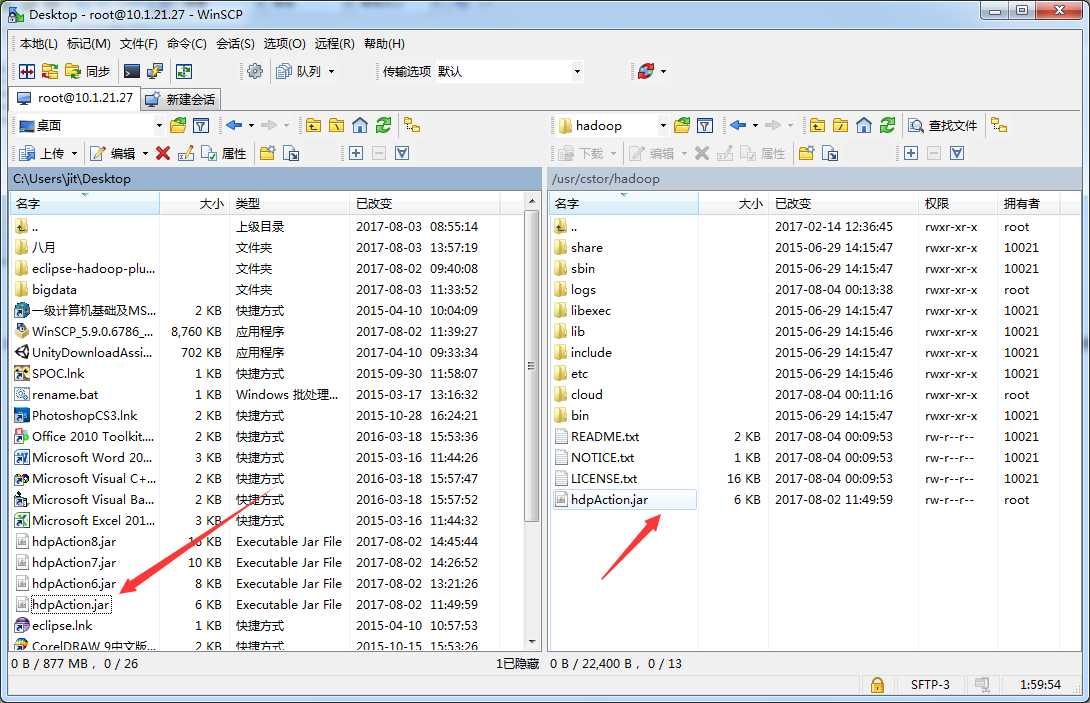
>运行该jar文件 hadoop jar ~/hdpAction.jar ReadFile

总结:
对于HDFS文件读写的学习,很基础同时也很重要,在后面关于yarn,mapreduce等的学习都要基于此处之上才能逐步了解。
只有一种失败就是半途而废。所以每天的学习会逐步积累,潜移默化。