Python的几个爬虫代码整理(网易云、微信、淘宝、今日头条)
时间:2017-06-03 22:37:51
收藏:0
阅读:3924
整理了一下网易云歌曲评论抓取、分析好友信息抓取、淘宝宝贝抓取、今日头条美图抓取的一些代码
抓取网易云评论
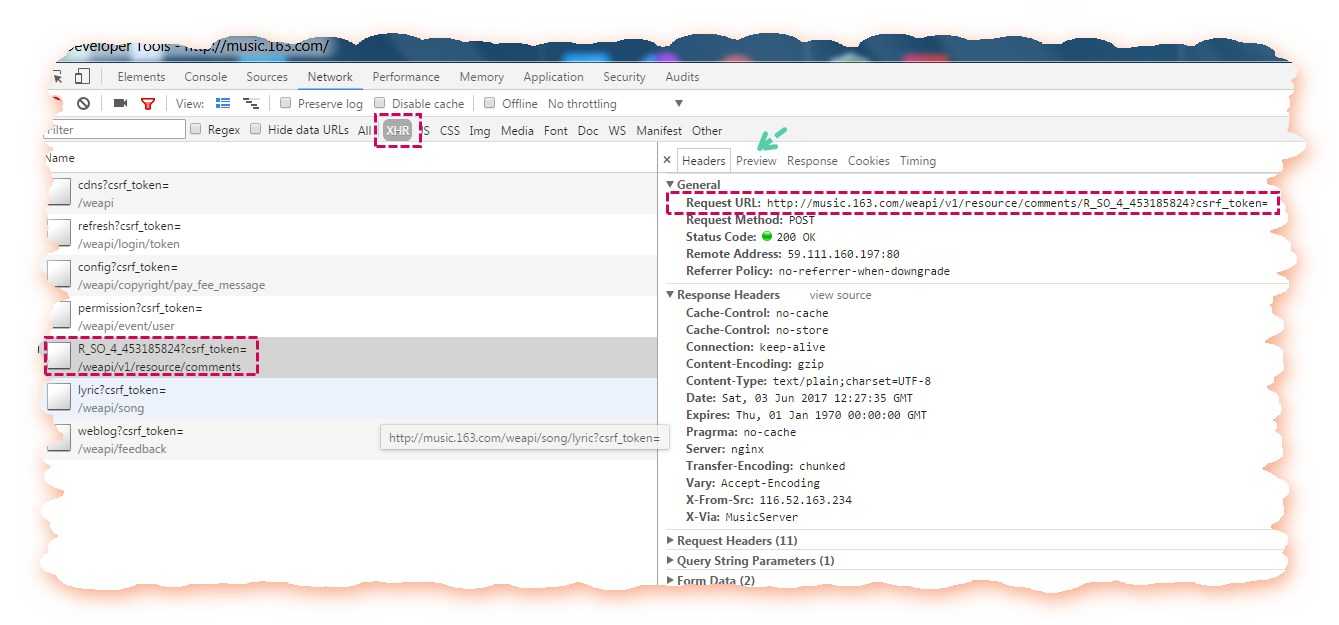
进入歌曲界面:
找到如下的数据源:
贴一段Lyrichu的代码:
(运行环境为P2.7)
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py
‘‘‘
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章(地址:https://www.zhihu.com/question/36081767)
post加密部分也给出了,可以参考原帖:
作者:平胸小仙女
链接:https://www.zhihu.com/question/36081767/answer/140287795
来源:知乎
‘‘‘
from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
‘Host‘:"music.163.com",
‘Accept-Language‘:"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
‘Accept-Encoding‘:"gzip, deflate",
‘Content-Type‘:"application/x-www-form-urlencoded",
‘Cookie‘:"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
‘Connection‘:"keep-alive",
‘Referer‘:‘http://music.163.com/‘
}
# 设置代理服务器
proxies= {
‘http:‘:‘http://121.232.146.184‘,
‘https:‘:‘https://144.255.48.197‘
}
# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false
# first_param = ‘{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}‘ # 第一个参数
second_param = "010001" # 第二个参数
# 第三个参数
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数
forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数
def get_params(page): # page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * ‘F‘
if(page == 1): # 如果为第一页
first_param = ‘{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}‘
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = ‘{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}‘ %(offset,‘false‘)
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict[‘hotComments‘] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item[‘content‘] # 评论内容
likedCount = item[‘likedCount‘] # 点赞总数
comment_time = item[‘time‘] # 评论时间(时间戳)
userID = item[‘user‘][‘userID‘] # 评论者id
nickname = item[‘user‘][‘nickname‘] # 昵称
avatarUrl = item[‘user‘][‘avatarUrl‘] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u"\n"
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict[‘total‘])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict[‘comments‘]:
comment = item[‘content‘] # 评论内容
likedCount = item[‘likedCount‘] # 点赞总数
comment_time = item[‘time‘] # 评论时间(时间戳)
userID = item[‘user‘][‘userId‘] # 评论者id
nickname = item[‘user‘][‘nickname‘] # 昵称
avatarUrl = item[‘user‘][‘avatarUrl‘] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u"\n"
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,‘a‘,encoding=‘utf-8‘) as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_453185824?csrf_token="
filename = u"On_My_Way.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))
其中AES需要安装pycrypto库,在安装时报错,点击more,可以找到需要安装的C类库即可(直接复制相应的网址,下载并安装即可,好像是VCForPython27.msi)
结果如下:


代码文件:

******************************?******************************
抓取微信好友信息
代码如下:
#!/usr/bin/env python
# encoding=utf-8
from __future__ import print_function
import os
import requests
import re
import time
import xml.dom.minidom
import json
import sys
import math
import subprocess
import ssl
import threading
import urllib, urllib2
DEBUG = False
MAX_GROUP_NUM = 2 # 每组人数
INTERFACE_CALLING_INTERVAL = 5 # 接口调用时间间隔, 间隔太短容易出现"操作太频繁", 会被限制操作半小时左右
MAX_PROGRESS_LEN = 50
QRImagePath = os.path.join(os.getcwd(), ‘qrcode.jpg‘)
tip = 0
uuid = ‘‘
base_uri = ‘‘
redirect_uri = ‘‘
push_uri = ‘‘
skey = ‘‘
wxsid = ‘‘
wxuin = ‘‘
pass_ticket = ‘‘
deviceId = ‘e000000000000000‘
BaseRequest = {}
ContactList = []
My = []
SyncKey = []
try:
xrange
range = xrange
except:
# python 3
pass
def responseState(func, BaseResponse):
ErrMsg = BaseResponse[‘ErrMsg‘]
Ret = BaseResponse[‘Ret‘]
if DEBUG or Ret != 0:
print(‘func: %s, Ret: %d, ErrMsg: %s‘ % (func, Ret, ErrMsg))
if Ret != 0:
return False
return True
def getUUID():
global uuid
url = ‘https://login.weixin.qq.com/jslogin‘
params = {
‘appid‘: ‘wx782c26e4c19acffb‘,
‘fun‘: ‘new‘,
‘lang‘: ‘zh_CN‘,
‘_‘: int(time.time()),
}
r = myRequests.get(url=url, params=params)
r.encoding = ‘utf-8‘
data = r.text
# print(data)
# window.QRLogin.code = 200; window.QRLogin.uuid = "oZwt_bFfRg==";
regx = r‘window.QRLogin.code = (\d+); window.QRLogin.uuid = "(\S+?)"‘
pm = re.search(regx, data)
code = pm.group(1)
uuid = pm.group(2)
if code == ‘200‘:
return True
return False
def showQRImage():
global tip
url = ‘https://login.weixin.qq.com/qrcode/‘ + uuid
params = {
‘t‘: ‘webwx‘,
‘_‘: int(time.time()),
}
r = myRequests.get(url=url, params=params)
tip = 1
f = open(QRImagePath, ‘wb+‘)
f.write(r.content)
f.close()
time.sleep(1)
if sys.platform.find(‘darwin‘) >= 0:
subprocess.call([‘open‘, QRImagePath])
else:
os.startfile(QRImagePath)
print(‘请使用微信扫描二维码以登录‘)
def waitForLogin():
global tip, base_uri, redirect_uri, push_uri
url = ‘https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login?tip=%s&uuid=%s&_=%s‘ % (
tip, uuid, int(time.time()))
r = myRequests.get(url=url)
r.encoding = ‘utf-8‘
data = r.text
# print(data)
# window.code=500;
regx = r‘window.code=(\d+);‘
pm = re.search(regx, data)
code = pm.group(1)
if code == ‘201‘: # 已扫描
print(‘成功扫描,请在手机上点击确认以登录‘)
tip = 0
elif code == ‘200‘: # 已登录
print(‘正在登录...‘)
regx = r‘window.redirect_uri="(\S+?)";‘
pm = re.search(regx, data)
redirect_uri = pm.group(1) + ‘&fun=new‘
base_uri = redirect_uri[:redirect_uri.rfind(‘/‘)]
# push_uri与base_uri对应关系(排名分先后)(就是这么奇葩..)
services = [
(‘wx2.qq.com‘, ‘webpush2.weixin.qq.com‘),
(‘qq.com‘, ‘webpush.weixin.qq.com‘),
(‘web1.wechat.com‘, ‘webpush1.wechat.com‘),
(‘web2.wechat.com‘, ‘webpush2.wechat.com‘),
(‘wechat.com‘, ‘webpush.wechat.com‘),
(‘web1.wechatapp.com‘, ‘webpush1.wechatapp.com‘),
]
push_uri = base_uri
for (searchUrl, pushUrl) in services:
if base_uri.find(searchUrl) >= 0:
push_uri = ‘https://%s/cgi-bin/mmwebwx-bin‘ % pushUrl
break
# closeQRImage
if sys.platform.find(‘darwin‘) >= 0: # for OSX with Preview
os.system("osascript -e ‘quit app \"Preview\"‘")
elif code == ‘408‘: # 超时
pass
# elif code == ‘400‘ or code == ‘500‘:
return code
def login():
global skey, wxsid, wxuin, pass_ticket, BaseRequest
r = myRequests.get(url=redirect_uri)
r.encoding = ‘utf-8‘
data = r.text
# print(data)
doc = xml.dom.minidom.parseString(data)
root = doc.documentElement
for node in root.childNodes:
if node.nodeName == ‘skey‘:
skey = node.childNodes[0].data
elif node.nodeName == ‘wxsid‘:
wxsid = node.childNodes[0].data
elif node.nodeName == ‘wxuin‘:
wxuin = node.childNodes[0].data
elif node.nodeName == ‘pass_ticket‘:
pass_ticket = node.childNodes[0].data
# print(‘skey: %s, wxsid: %s, wxuin: %s, pass_ticket: %s‘ % (skey, wxsid,
# wxuin, pass_ticket))
if not all((skey, wxsid, wxuin, pass_ticket)):
return False
BaseRequest = {
‘Uin‘: int(wxuin),
‘Sid‘: wxsid,
‘Skey‘: skey,
‘DeviceID‘: deviceId,
}
return True
def webwxinit():
url = (base_uri +
‘/webwxinit?pass_ticket=%s&skey=%s&r=%s‘ % (
pass_ticket, skey, int(time.time())))
params = {‘BaseRequest‘: BaseRequest}
headers = {‘content-type‘: ‘application/json; charset=UTF-8‘}
r = myRequests.post(url=url, data=json.dumps(params), headers=headers)
r.encoding = ‘utf-8‘
data = r.json()
if DEBUG:
f = open(os.path.join(os.getcwd(), ‘webwxinit.json‘), ‘wb‘)
f.write(r.content)
f.close()
# print(data)
global ContactList, My, SyncKey
dic = data
ContactList = dic[‘ContactList‘]
My = dic[‘User‘]
SyncKey = dic[‘SyncKey‘]
state = responseState(‘webwxinit‘, dic[‘BaseResponse‘])
return state
def webwxgetcontact():
url = (base_uri +
‘/webwxgetcontact?pass_ticket=%s&skey=%s&r=%s‘ % (
pass_ticket, skey, int(time.time())))
headers = {‘content-type‘: ‘application/json; charset=UTF-8‘}
r = myRequests.post(url=url, headers=headers)
r.encoding = ‘utf-8‘
data = r.json()
if DEBUG:
f = open(os.path.join(os.getcwd(), ‘webwxgetcontact.json‘), ‘wb‘)
f.write(r.content)
f.close()
dic = data
MemberList = dic[‘MemberList‘]
# 倒序遍历,不然删除的时候出问题..
SpecialUsers = ["newsapp", "fmessage", "filehelper", "weibo", "qqmail", "tmessage", "qmessage", "qqsync",
"floatbottle", "lbsapp", "shakeapp", "medianote", "qqfriend", "readerapp", "blogapp", "facebookapp",
"masssendapp",
"meishiapp", "feedsapp", "voip", "blogappweixin", "weixin", "brandsessionholder", "weixinreminder",
"wxid_novlwrv3lqwv11", "gh_22b87fa7cb3c", "officialaccounts", "notification_messages", "wxitil",
"userexperience_alarm"]
for i in range(len(MemberList) - 1, -1, -1):
Member = MemberList[i]
if Member[‘VerifyFlag‘] & 8 != 0: # 公众号/服务号
MemberList.remove(Member)
elif Member[‘UserName‘] in SpecialUsers: # 特殊账号
MemberList.remove(Member)
elif Member[‘UserName‘].find(‘@@‘) != -1: # 群聊
MemberList.remove(Member)
elif Member[‘UserName‘] == My[‘UserName‘]: # 自己
MemberList.remove(Member)
return MemberList
def syncKey():
SyncKeyItems = [‘%s_%s‘ % (item[‘Key‘], item[‘Val‘])
for item in SyncKey[‘List‘]]
SyncKeyStr = ‘|‘.join(SyncKeyItems)
return SyncKeyStr
def syncCheck():
url = push_uri + ‘/synccheck?‘
params = {
‘skey‘: BaseRequest[‘Skey‘],
‘sid‘: BaseRequest[‘Sid‘],
‘uin‘: BaseRequest[‘Uin‘],
‘deviceId‘: BaseRequest[‘DeviceID‘],
‘synckey‘: syncKey(),
‘r‘: int(time.time()),
}
r = myRequests.get(url=url, params=params)
r.encoding = ‘utf-8‘
data = r.text
# print(data)
# window.synccheck={retcode:"0",selector:"2"}
regx = r‘window.synccheck={retcode:"(\d+)",selector:"(\d+)"}‘
pm = re.search(regx, data)
retcode = pm.group(1)
selector = pm.group(2)
return selector
def webwxsync():
global SyncKey
url = base_uri + ‘/webwxsync?lang=zh_CN&skey=%s&sid=%s&pass_ticket=%s‘ % (
BaseRequest[‘Skey‘], BaseRequest[‘Sid‘], urllib.quote_plus(pass_ticket))
params = {
‘BaseRequest‘: BaseRequest,
‘SyncKey‘: SyncKey,
‘rr‘: ~int(time.time()),
}
headers = {‘content-type‘: ‘application/json; charset=UTF-8‘}
r = myRequests.post(url=url, data=json.dumps(params))
r.encoding = ‘utf-8‘
data = r.json()
# print(data)
dic = data
SyncKey = dic[‘SyncKey‘]
state = responseState(‘webwxsync‘, dic[‘BaseResponse‘])
return state
def heartBeatLoop():
while True:
selector = syncCheck()
if selector != ‘0‘:
webwxsync()
time.sleep(1)
def main():
global myRequests
if hasattr(ssl, ‘_create_unverified_context‘):
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
‘User-agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.125 Safari/537.36‘}
myRequests = requests.Session()
myRequests.headers.update(headers)
if not getUUID():
print(‘获取uuid失败‘)
return
print(‘正在获取二维码图片...‘)
showQRImage()
while waitForLogin() != ‘200‘:
pass
os.remove(QRImagePath)
if not login():
print(‘登录失败‘)
return
if not webwxinit():
print(‘初始化失败‘)
return
MemberList = webwxgetcontact()
threading.Thread(target=heartBeatLoop)
MemberCount = len(MemberList)
print(‘通讯录共%s位好友‘ % MemberCount)
d = {}
imageIndex = 0
for Member in MemberList:
imageIndex = imageIndex + 1
# name = ‘C:\\Users\\Public\\Pictures\\‘ + str(imageIndex) + ‘.jpg‘
# imageUrl = ‘http://wx2.qq.com‘ + Member[‘HeadImgUrl‘]
# r = myRequests.get(url=imageUrl, headers=headers)
# imageContent = (r.content)
# fileImage = open(name, ‘wb‘)
# fileImage.write(imageContent)
# fileImage.close()
# print(‘正在下载第:‘ + str(imageIndex) + ‘位好友头像‘)
d[Member[‘UserName‘]] = (Member[‘NickName‘], Member[‘RemarkName‘])
city = Member[‘City‘]
city = ‘nocity‘ if city == ‘‘ else city
name = Member[‘NickName‘]
name = ‘noname‘ if name == ‘‘ else name
sign = Member[‘Signature‘]
sign = ‘nosign‘ if sign == ‘‘ else sign
remark = Member[‘RemarkName‘]
remark = ‘noremark‘ if remark == ‘‘ else remark
alias = Member[‘Alias‘]
alias = ‘noalias‘ if alias == ‘‘ else alias
nick = Member[‘NickName‘]
nick = ‘nonick‘ if nick == ‘‘ else nick
print(name, ‘|||‘, city, ‘|||‘, Member[‘Sex‘], ‘|||‘, Member[‘StarFriend‘], ‘|||‘, sign,
‘|||‘, remark, ‘|||‘, alias, ‘|||‘, nick)
if __name__ == ‘__main__‘:
main()
print(‘回车键退出...‘)
input()
程序运行过程中会跳出二维码,需要我们扫描登录
作者原文基于mac,所以我自己修改成了这个样子(红色加粗和蓝色底纹部分)
subprocess.call([‘open‘, QRImagePath]) 是给linux或mac下用来打开文件的
而windows下要用os.startfile(QRImagePath)(不要问我怎么知道的,我运行报错后猜出它的作用然后百度的)

(感谢好友的一路陪伴和困厄之时的支持)
微信头像被保存在对应的文件路径C:\\Users\\Public\\Pictures\\中
在CSV中:

经过分析(借助了EasyChart的配色):
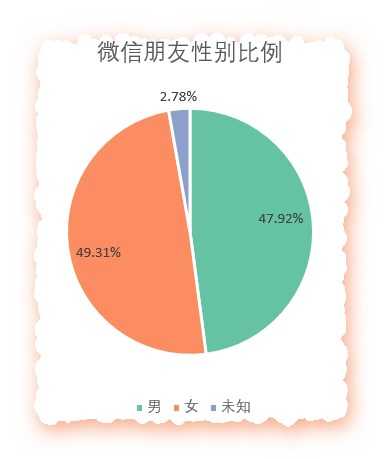
神奇,居然还是女生多?难道是最近加我的微信或者骗子比较多嘛?
文件


Python对微信好友进行简单统计分析当Python遇上微信,可以这么玩
******************************?******************************
抓取淘宝宝贝信息
代码如下:
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from taobao.config import *
import pymongo
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
wait = WebDriverWait(browser, 10)
#设置窗口大小,以免默认的相对较小的窗口影响操作
browser.set_window_size(1400, 900)
def search():
print(‘正在搜索‘)
try:
browser.get(‘https://www.taobao.com‘)
# http://selenium-python.readthedocs.io/waits.html#explicit-waits
# 输入框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, ‘#q‘))
)
#搜索提交按钮
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, ‘#J_TSearchForm > div.search-button > button‘)))
input.send_keys(KEYWORD)
submit.click()
#等待搜索内容加载,表示为共x页
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.total‘)))
#total中就是总共有多少页
get_products()
return total.text
except TimeoutException:
# wait在网速过慢的时候会出现超时错误,所以我们递归调用重新请求
return search()
def next_page(page_number):
#进入下一页有多种方式,比如点击xx页,比如点击下一页按钮
#比如在输入框中设置页码,点击确定
#我们采用最后一种,因为第一章容易错乱
#而最后一种相比于第二种方便我们在出错的时候递归
print(‘正在翻页‘, page_number)
try:
#输入页码框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.form > input‘))
)
#提交按钮
submit = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit‘)))
#清楚原先的页码
input.clear()
input.send_keys(page_number)
submit.click()
#判断翻页是否成功(判断条件是高亮的当前代码)
wait.until(EC.text_to_be_present_in_element(
(By.CSS_SELECTOR, ‘#mainsrp-pager > div > div > div > ul > li.item.active > span‘), str(page_number)))
get_products()
except TimeoutException:
#出错则递归,重新执行
next_page(page_number)
#解析
def get_products():
#判断所有的宝贝信息是否传递成功
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ‘#mainsrp-itemlist .items .item‘)))
html = browser.page_source
doc = pq(html)
items = doc(‘#mainsrp-itemlist .items .item‘).items()
for item in items:
product = {
‘image‘: item.find(‘.pic .img‘).attr(‘src‘),
‘price‘: item.find(‘.price‘).text(),
‘deal‘: item.find(‘.deal-cnt‘).text()[:-3],
‘title‘: item.find(‘.title‘).text(),
‘shop‘: item.find(‘.shop‘).text(),
‘location‘: item.find(‘.location‘).text()
}
print(product)
save_to_mongo(product)
#保存
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print(‘存储到MONGODB成功‘, result)
except Exception:
print(‘存储到MONGODB失败‘, result)
def main():
try:
total = search()
#提取总页数
total = int(re.compile(‘(\d+)‘).search(total).group(1))
for i in range(2, total + 1):
#从第二页才开始需要点击下一页
next_page(i)
except Exception:
print(‘出错啦‘)
finally:
browser.close()
if __name__ == ‘__main__‘:
main()
注意,是在Python3下
config文件(上面标红的config的引入路径要根据实际情况修改)
MONGO_URL = ‘localhost‘
MONGO_DB = ‘taobao‘
MONGO_TABLE = ‘product‘
# http://phantomjs.org/api/command-line.html
#第一个参数是不加载图片,使程序运行更快
#第二个的开启缓存
SERVICE_ARGS = [‘--load-images=false‘, ‘--disk-cache=true‘]
KEYWORD = ‘汉服‘
******************************?******************************
抓取今日头条
代码如下:
import json
import os
from urllib.parse import urlencode
import pymongo
import requests
from bs4 import BeautifulSoup
from requests.exceptions import ConnectionError
import re
from multiprocessing import Pool
from hashlib import md5
from json.decoder import JSONDecodeError
from spider_basic.config import *
#
client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB]
#获取主页,offse是ajax动态加载的偏移量,keyword是搜索的关键字
def get_page_index(offset, keyword):
data = {
‘autoload‘: ‘true‘,
‘count‘: 20,
‘cur_tab‘: 3,
‘format‘: ‘json‘,
‘keyword‘: keyword,
‘offset‘: offset,
}
params = urlencode(data)
base = ‘http://www.toutiao.com/search_content/‘
url = base + ‘?‘ + params
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print(‘Error occurred‘)
return None
#下载
def download_image(url):
print(‘Downloading‘, url)
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content)
return None
except ConnectionError:
return None
#保存
def save_image(content):
# 文件名
# 路径 名称 后缀
# 名称md5 这是为了当我们运行一次程序出错时,第二次不再保存重复图片
file_path = ‘{0}/{1}/{2}.{3}‘.format(os.getcwd(),‘pic‘,md5(content).hexdigest(), ‘jpg‘)
print(file_path)
# 如果文件不存在则保存
# content是二进制形式的网页内容
if not os.path.exists(file_path):
with open(file_path, ‘wb‘) as f:
f.write(content)
f.close()
#解析搜索后返回的网页(就是图集XHR中的那些)
def parse_page_index(text):
try:
#转化为JSON
data = json.loads(text)
#如果JSON数据中含有data这个键
if data and ‘data‘ in data.keys():
for item in data.get(‘data‘):
yield item.get(‘article_url‘)
except JSONDecodeError:
pass
#获取详情页
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
print(‘Error occurred‘)
return None
#解析详情页
def parse_page_detail(html, url):
soup = BeautifulSoup(html, ‘lxml‘)
#获取标题
result = soup.select(‘title‘)
title = result[0].get_text() if result else ‘‘
#获取图片地址(定义正则规则,并search)
images_pattern = re.compile(‘var gallery = (.*?);‘, re.S)
result = re.search(images_pattern, html)
#如果非空
if result:
#转化为JSON格式
data = json.loads(result.group(1))
#如果sub_images这个键的值对应了各种url
if data and ‘sub_images‘ in data.keys():
sub_images = data.get(‘sub_images‘)
images = [item.get(‘url‘) for item in sub_images]
#下载图片
for image in images: download_image(image)
return {
‘title‘: title,
‘url‘: url,
‘images‘: images
}
#存储到数据库
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print(‘Successfully Saved to Mongo‘, result)
return True
return False
def main(offset):
text = get_page_index(offset, KEYWORD)
#生成器返回图集中每一个图集的URL的遍历器
urls = parse_page_index(text)
#遍历每一个图集,获取详情页信息
for url in urls:
#获取详情页
html = get_page_detail(url)
#解析详情页
result = parse_page_detail(html, url)
#保存到MongoDB
if result: save_to_mongo(result)
# if __name__ == ‘__main__‘:
# main(60)
# 注意,如果不在if __name__ == ‘__main__‘:中运行的话,会爆出一堆多线程的错误
if __name__ == ‘__main__‘:
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
config文件
MONGO_URL = ‘localhost‘
MONGO_DB = ‘toutiao‘
MONGO_TABLE = ‘toutiao‘
GROUP_START = 1
GROUP_END = 20
KEYWORD=‘萌宠‘
附件列表
评论(0)