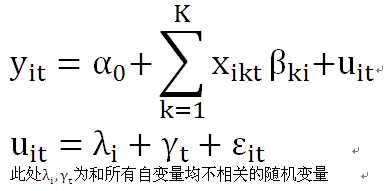面板数据、截面数据、时间序列数据
截面数据、时间序列数据、面板数据是最常见的三种样本数据形式,网上对于此类数据的介绍比较零散,我在此做一个汇总归纳,如有错误,欢迎指正,我在此只做简单介绍,并不涉及具体分析,特别是面板数据,分析比较复杂,有专门的书籍可以参阅。
一、截面数据(Cross Section data)
1.概念:
截面数据是指由同一时期、不同个体的一个或多个统计指标所组成的数据集。该数据强调同一时期,因此也称为静态数据,我们平时获取的样本数据,大都具有同期性,因此截面数据也是最常见的
样本数据。
例如:
2016年各省份人口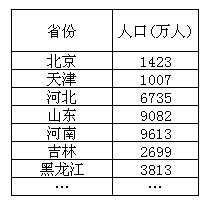
同一时期:2016年
不同个体:不同省份
一个统计指标:人口数
不同治疗方法的疼痛水平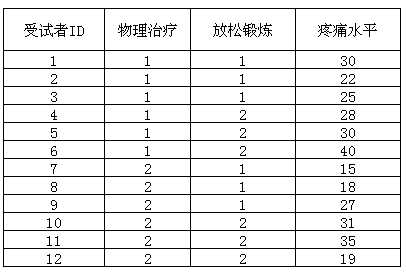
这是一组常见的方差分析数据,
同一时期:此处虽然没有明确告知测量时间,一般是默认为同期测量或忽略时间效应,如果时间效应明确不能忽略,那么数据中要增加时间变量,此时就不再是截面数据了。
不同个体:不同的受试者
多个统计指标:此处有三个统计指标,其中包括两个分组测量,物理测试分为1组-拉伸锻炼,2组-力量锻炼,放松测试分为1组-肌肉放松,2组-意念引导,外加一个疼痛水平的测量数值。
2.分析方法
绝大多数统计分析方法都可以分析截面数据,可根据分析目的和截面数据类型做出选择,比如数据类型为连续型数据且为单个统计指标,可以使用描述性分析;数据类型为连续但是有多个统计指标,可以使用聚类分析、因子分析、回归分析等;统计指标有分组数据的,可使用方差分析、回归分析等。
3.注意的问题
<1>截面数据是不同个体,有时这些个体差异很大,比如不同的省份,由此很容易产生异方差问题,因此做回归分析时,需要对此进行检验
<2>要注意不同个体测量数据的一致性,这种一致性包括时期一致和统计指标一致。
==========================================================
二、时间序列数据(Time Series data)
1.概念:
时间序列数据是指不同时期,同一个体的一个或多个统计指标做组成的数据集。该数据强调不同时期,并且数据严格按照时间顺序排序,时期可以人为指定,如月、日、季度、年度甚至分秒等。由于时间序列数据存在先后顺序,而这种顺序前后相承,当中必然隐含了一些信息,因此时间序列数据可用来研究分析事物的发展变化规律,在某些领域如经济学中非常常见。
例如:
北京市各年份GDP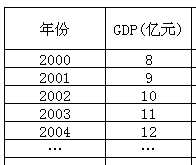
不同时期:2000、2001、2002、2003、2004各年
同一个体:北京市
一个统计指标:GDP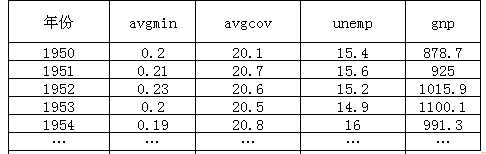
不同时期:1950-1954...各年
同一个体:某地区
多个统计指标:avgmin、avgcov、unemp、gnp
2.分析方法
由于时间序列数据只针对单个个体,所有的测量实验都是围绕单个个体展开的,并且时间作为一个重要变量和因素,因此对时间序列数据基本上采用回归分析,并且有专门的时间序列模型。
3.注意的问题
由于时间序列数据使用回归分析,因此回归分析中需要注意的问题,在时间序列数据中也要注意,此外,时间序列数据还有一些自身的特点,如平稳性、模式识别等。
==========================================================
三、面板数据(panel data)
1.概念:
无论截面数据的同一时期,还是时间序列数据的同一个体,都说明这两类数据只有一个维度,而面板数据是二者的结合,是指在不同时期、不同个体的一个或多个统计指标做组成的数据集。具有个体和时间两个维度,也称为时间序列与截面混合数据或平行数据,是二维数据。面板数据可以理解为截面上的个体在不同时点的重复观测数据。如图
由于面板数据同时具有时间和个体两个维度,样本容量更大,携带的变异信息更多,既可以分析个体间的差异,也可以分析个体随时间的变化情况。此外,这种大量的变异信息也可以解决共线性问题。
2.分析方法
面板数据的分析主要是建立回归模型,一般形式如下:
上式中,由于样本量容量(自由度)=i*t,远小于参数个数=i*t*(K+1)+描述随机误差分布的参数个数,这使得模型无法估计,为了解决此问题,我们可以建立以下两类模型:
(1)以个体角度考虑,建立包含i个个体方程的面板数据模型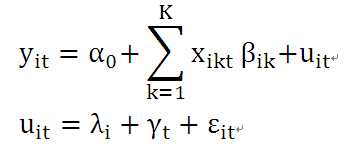
(2)以时间角度考虑,建立包含t个时间点截面方程的面板数据模型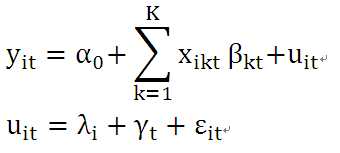
上面两类模型在估计方法上类似,我们以(1)为例,根据不同的假设情况,又分为以下几种形式:
<1>.混合估计模型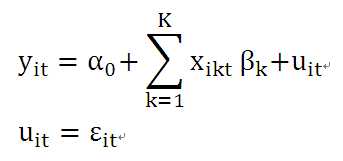
该模型假设解释变量与随机误差不相关,随机误差项中既没有个体差异和没有时间差异,这样就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。
混合估计模型的特点是无论对任何个体或截面,截距α和回归系数β都相同。混合估计模型的假设过于简单,既没有个体差异也没有时间差异的情况在实际中极少遇到。我们需要模型中能够体现出差异,无论是个体差异还是时间差异,因此衍生出下面的固定效应模型和随机效应模型
<2>.固定效应模型
固定效应是指随机误差项中的个体差异λi或时间差异γt和自变量存在相关性。分为个体固定、时间固定、个体+时间双固定三种。
个体固定是指模型中加入不随时间变化但个体间不同的变量,并分析其效应
时间固定是指模型中加入不随个体变化但时间不同的变量,并分析其效应
个体+时间双固定是指模型中同时加入个体固定变量和时间固定变量,并分析这些变量的效应
变截距是指模型在截面上存在个体差异的影响,而在时间上不存在差异,即不同的个体或不同的时
点有不同的截距项,但是斜率相同
变系数是指模型在截面上存在个体差异的影响,同时在时间上也存在差异,即不同的个体或不同的
时点截距不同,斜率也不同。
·变截距的个体固定效应模型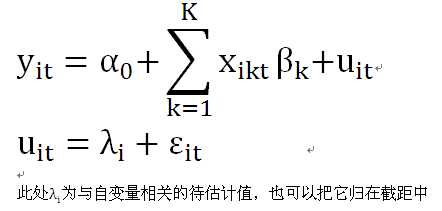
·变系数的个体固定效应模型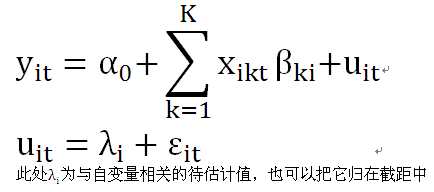
·变截距的时间固定效应模型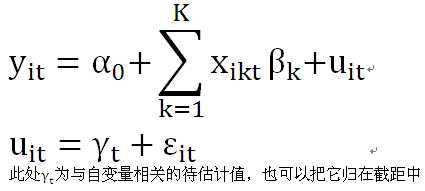
·变系数的时间固定效应模型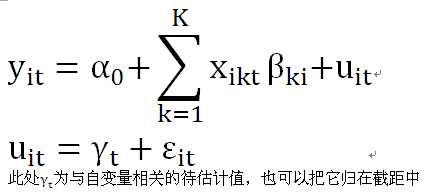
·变截距的个体+时间双固定效应模型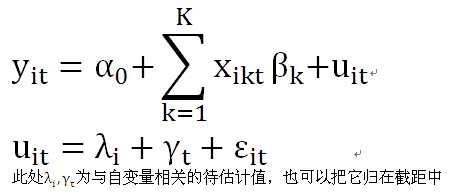
·变系数的个体+时间双固定效应模型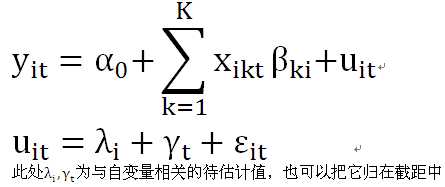
<3>随机效应模型
所谓随机效应是指随机误差项中的个体差异λi或时间差异γt和所有自变量均不存在相关性,是随机出现的。
其余概念同固定效应模型,相应的,也可以分为和固定效应模型一样的类型
·变截距的个体随机效应模型
·变系数的个体随机效应模型
·变截距的时间随机效应模型
·变系数的时间随机效应模型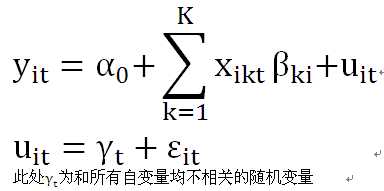
·变截距的个体+时间双随机效应模型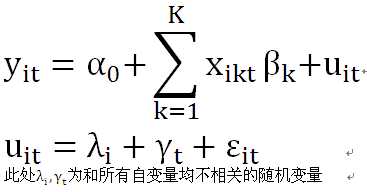
·变系数的个体+时间双随机效应模型