MySQL redo log及recover过程浅析
时间:2014-05-08 12:47:11
收藏:0
阅读:573
写在前面:作者水平有限,欢迎不吝赐教,一切以最新源码为准。
InnoDB redo log
首先介绍下Innodb redo log是什么,为什么需要记录redo log,以及redo
log的作用都有哪些。这些作为常识,只是为了本文完整。
InnoDB有buffer
pool(简称bp)。bp是数据库页面的缓存,对InnoDB的任何修改操作都会首先在bp的page上进行,然后这样的页面将被标记为dirty并被放到专门的flush
list上,后续将由master thread或专门的刷脏线程阶段性的将这些页面写入磁盘(disk or
ssd)。这样的好处是避免每次写操作都操作磁盘导致大量的随机IO,阶段性的刷脏可以将多次对页面的修改merge成一次IO操作,同时异步写入也降低了访问的时延。然而,如果在dirty
page还未刷入磁盘时,server非正常关闭,这些修改操作将会丢失,如果写入操作正在进行,甚至会由于损坏数据文件导致数据库不可用。为了避免上述问题的发生,Innodb将所有对页面的修改操作写入一个专门的文件,并在数据库启动时从此文件进行恢复操作,这个文件就是redo
log file。这样的技术推迟了bp页面的刷新,从而提升了数据库的吞吐,有效的降低了访问时延。带来的问题是额外的写redo
log操作的开销(顺序IO,当然很快),以及数据库启动时恢复操作所需的时间。
接下来将结合MySQL 5.6的代码看下Log文件的结构、生成过程以及数据库启动时的恢复流程。
Log文件结构
Redo log文件包含一组log files,其会被循环使用。Redo log文件的大小和数目可以通过特定的参数设置,详见:innodb_log_file_size 和 innodb_log_files_in_group 。每个log文件有一个文件头,其代码在"storage/innobase/include/log0log.h"中,我们看下log文件头都记录了哪些信息:

669 /* Offsets of a log file header */ 670 #define LOG_GROUP_ID 0 /* log group number */ 671 #define LOG_FILE_START_LSN 4 /* lsn of the start of data in this 672 log file */ 673 #define LOG_FILE_NO 12 /* 4-byte archived log file number; 674 this field is only defined in an 675 archived log file */ 676 #define LOG_FILE_WAS_CREATED_BY_HOT_BACKUP 16 677 /* a 32-byte field which contains 678 the string ‘ibbackup‘ and the 679 creation time if the log file was 680 created by ibbackup --restore; 681 when mysqld is first time started 682 on the restored database, it can 683 print helpful info for the user */ 684 #define LOG_FILE_ARCH_COMPLETED OS_FILE_LOG_BLOCK_SIZE 685 /* this 4-byte field is TRUE when 686 the writing of an archived log file 687 has been completed; this field is 688 only defined in an archived log file */ 689 #define LOG_FILE_END_LSN (OS_FILE_LOG_BLOCK_SIZE + 4) 690 /* lsn where the archived log file 691 at least extends: actually the 692 archived log file may extend to a 693 later lsn, as long as it is within the 694 same log block as this lsn; this field 695 is defined only when an archived log 696 file has been completely written */ 697 #define LOG_CHECKPOINT_1 OS_FILE_LOG_BLOCK_SIZE 698 /* first checkpoint field in the log 699 header; we write alternately to the 700 checkpoint fields when we make new 701 checkpoints; this field is only defined 702 in the first log file of a log group */ 703 #define LOG_CHECKPOINT_2 (3 * OS_FILE_LOG_BLOCK_SIZE) 704 /* second checkpoint field in the log 705 header */ 706 #define LOG_FILE_HDR_SIZE (4 * OS_FILE_LOG_BLOCK_SIZE)
日志文件头共占用4个OS_FILE_LOG_BLOCK_SIZE的大小,这里对部分字段做简要介绍:
1. LOG_GROUP_ID
这个log文件所属的日志组,占用4个字节,当前都是0;
2. LOG_FILE_START_LSN
这个log文件记录的初始数据的lsn,占用8个字节;
3. LOG_FILE_WAS_CRATED_BY_HOT_BACKUP
备份程序所占用的字节数,共占用32字节,如xtrabackup在备份时会在xtrabackup_logfile文件中记录"xtrabackup
backup_time";
4. LOG_CHECKPOINT_1/LOG_CHECKPOINT_2 两个记录InnoDB
checkpoint信息的字段,分别从文件头的第二个和第四个block开始记录,只使用日志文件组的第一个日志文件。
这里多说两句,每次checkpoint后InnoDB都需要更新这两个字段的值,因此redo
log的写入并非严格的顺序写;
每个log文件包含许多log records。log
records将以OS_FILE_LOG_BLOCK_SIZE(默认值为512字节)为单位顺序写入log文件。每一条记录都有自己的LSN(log
sequence number,表示从日志记录创建开始到特定的日志记录已经写入的字节数)。每个Log
Block包含一个header段、一个tailer段,以及一组log records。
首先看下Log Block header。block header的开始4个字节是log block
number,表示这是第几个block块。其是通过LSN计算得来,计算的函数是log_block_convert_lsn_to_no();接下来两个字节表示该block中已经有多少个字节被使用;再后边两个字节表示该block中作为一个新的MTR开始log
record的偏移量,由于一个block中可以包含多个MTR记录的log,所以需要有记录表示此偏移量。再然后四个字节表示该block的checkpoint
number。block trailer占用四个字节,表示此log
block计算出的checksum值,用于正确性校验,MySQL5.6提供了若干种计算checksum的算法,这里不再赘述。我们可以结合代码中给出的注释,再了解下header和trailer的各个字段的含义。
580 /* Offsets of a log block header */ 581 #define LOG_BLOCK_HDR_NO 0 /* block number which must be > 0 and 582 is allowed to wrap around at 2G; the 583 highest bit is set to 1 if this is the 584 first log block in a log flush write 585 segment */ 586 #define LOG_BLOCK_FLUSH_BIT_MASK 0x80000000UL 587 /* mask used to get the highest bit in 588 the preceding field */ 589 #define LOG_BLOCK_HDR_DATA_LEN 4 /* number of bytes of log written to 590 this block */ 591 #define LOG_BLOCK_FIRST_REC_GROUP 6 /* offset of the first start of an 592 mtr log record group in this log block, 593 0 if none; if the value is the same 594 as LOG_BLOCK_HDR_DATA_LEN, it means 595 that the first rec group has not yet 596 been catenated to this log block, but 597 if it will, it will start at this 598 offset; an archive recovery can 599 start parsing the log records starting 600 from this offset in this log block, 601 if value not 0 */ 602 #define LOG_BLOCK_CHECKPOINT_NO 8 /* 4 lower bytes of the value of 603 log_sys->next_checkpoint_no when the 604 log block was last written to: if the 605 block has not yet been written full, 606 this value is only updated before a 607 log buffer flush */ 608 #define LOG_BLOCK_HDR_SIZE 12 /* size of the log block header in 609 bytes */ 610 611 /* Offsets of a log block trailer from the end of the block */ 612 #define LOG_BLOCK_CHECKSUM 4 /* 4 byte checksum of the log block 613 contents; in InnoDB versions 614 < 3.23.52 this did not contain the 615 checksum but the same value as 616 .._HDR_NO */ 617 #define LOG_BLOCK_TRL_SIZE 4 /* trailer size in bytes */
Log 记录生成
在介绍了log file和log block的结构后,接下来描述log
record在InnoDB内部是如何生成的,其“生命周期”是如何在内存中一步步流转并最终写入磁盘中的。这里涉及到两块内存缓冲,涉及到mtr/log_sys等内部结构,后续会一一介绍。
首先介绍下log_sys。log_sys是InnoDB在内存中保存的一个全局的结构体(struct名为log_t,global
object名为log_sys),其维护了一块全局内存区域叫做log
buffer(log_sys->buf),同时维护有若干lsn值等信息表示logging进行的状态。其在log_init函数中对所有的内部区域进行分配并对各个变量进行初始化。
log_t的结构体很大,这里不再粘出来,可以自行看"storage/innobase/include/log0log.h: struct
log_t"。下边会对其中比较重要的字段值加以说明:
| log_sys->lsn | 接下来将要生成的log record使用此lsn的值 |
|
log_sys->flushed_do_disk_lsn |
redo log file已经被刷新到此lsn。比该lsn值小的日志记录已经被安全的记录在磁盘上 |
|
log_sys->write_lsn |
当前正在执行的写操作使用的临界lsn值; |
|
log_sys->current_flush_lsn |
当前正在执行的write + flush操作使用的临界lsn值,一般和log_sys->write_lsn相等; |
|
log_sys->buf |
内存中全局的log buffer,和每个mtr自己的buffer有所区别; |
|
log_sys->buf_size |
log_sys->buf的size |
|
log_sys->buf_free |
写入buffer的起始偏移量 |
|
log_sys->buf_next_to_write |
buffer中还未写到log file的起始偏移量。下次执行write+flush操作时,将会从此偏移量开始 |
|
log_sys->max_buf_free |
确定flush操作执行的时间点,当log_sys->buf_free比此值大时需要执行flush操作,具体看log_check_margins函数
|
接下来介绍mtr。mtr是mini-transactions的缩写。其在代码中对应的结构体是mtr_t,内部有一个局部buffer,会将一组log
record集中起来,批量写入log buffer。mtr_t的结构体如下所示:
376 /* Mini-transaction handle and buffer */ 377 struct mtr_t{ 378 #ifdef UNIV_DEBUG 379 ulint state; /*!< MTR_ACTIVE, MTR_COMMITTING, MTR_COMMITTED */ 380 #endif 381 dyn_array_t memo; /*!< memo stack for locks etc. */ 382 dyn_array_t log; /*!< mini-transaction log */ 383 unsigned inside_ibuf:1; 384 /*!< TRUE if inside ibuf changes */ 385 unsigned modifications:1; 386 /*!< TRUE if the mini-transaction 387 modified buffer pool pages */ 388 unsigned made_dirty:1; 389 /*!< TRUE if mtr has made at least 390 one buffer pool page dirty */ 391 ulint n_log_recs; 392 /* count of how many page initial log records 393 have been written to the mtr log */ 394 ulint n_freed_pages; 395 /* number of pages that have been freed in 396 this mini-transaction */ 397 ulint log_mode; /* specifies which operations should be 398 logged; default value MTR_LOG_ALL */ 399 lsn_t start_lsn;/* start lsn of the possible log entry for 400 this mtr */ 401 lsn_t end_lsn;/* end lsn of the possible log entry for 402 this mtr */ 403 #ifdef UNIV_DEBUG 404 ulint magic_n; 405 #endif /* UNIV_DEBUG */ 406 };
mtr_t::log --作为mtr的局部缓存,记录log record;
mtr_t::memo --包含了一组由此mtr涉及的操作造成的脏页列表,其会在mtr_commit执行后添加到flush
list(参见mtr_memo_pop_all()函数);
mtr的一个典型应用场景如下:
1. 创建一个mtr_t类型的对象;
2. 执行mtr_start函数,此函数将会初始化mtr_t的字段,包括local buffer;
3. 在对内存bp中的page进行修改的同时,调用mlog_write_ulint类似的函数,生成redo log
record,保存在local buffer中;
4. 执行mtr_commit函数,此函数将会将local buffer中的redo
log拷贝到全局的log_sys->buffer,同时将脏页添加到flush list,供后续执行flush操作时使用;
mtr_commit函数调用mtr_log_reserve_and_write,进而调用log_write_low执行上述的拷贝操作。如果需要,此函数将会在log_sys->buf上创建一个新的log
block,填充header、tailer以及计算checksum。
我们知道,为了保证数据库ACID特性中的原子性和持久性,理论上,在事务提交时,redo
log应已经安全原子的写到磁盘文件之中。回到MySQL,文件内存中的log_sys->buffer何时以及如何写入磁盘中的redo log
file与innodb_flush_log_at_trx_commit的设置密切相关。无论对于DBA还是MySQL的使用者对这个参数都已经相当熟悉,这里直接举例不同取值时log子系统是如何操作的。
innodb_flush_log_at_trx_commit=1/2。此时每次事务提交时都会写redo
log,不同的是1对应write+flush,2只write,而由指定线程周期性的执行flush操作(周期多为1s)。执行write操作的函数是log_group_write_buf,其由log_write_up_to函数调用。一个典型的调用栈如下:
(trx_commit_in_memory() / trx_commit_complete_for_mysql() / trx_prepare() e.t.c)-> trx_flush_log_if_needed()-> trx_flush_log_if_needed_low()-> log_write_up_to()-> log_group_write_buf().
log_group_write_buf会再调用innodb封装的底层IO系统,其实现很复杂,这里不再展开。
innodb_flush_log_at_trx_commit=0时,每次事务commit不会再调用写redo
log的函数,其写入逻辑都由master_thread完成,典型的调用栈如下:
srv_master_thread()-> (srv_master_do_active_tasks() / srv_master_do_idle_tasks() / srv_master_do_shutdown_tasks())-> srv_sync_log_buffer_in_background()-> log_buffer_sync_in_background()->log_write_up_to()->... .
除此参数的影响之外,还有一些场景下要求刷新redo log文件。这里举几个例子:
1)为了保证write ahead logging(WAL),在刷新脏页前要求其对应的redo
log已经写到磁盘,因此需要调用log_write_up_to函数;
2)为了循环利用log file,在log
file空间不足时需要执行checkpoint(同步或异步),此时会通过调用log_checkpoint执行日志刷新操作。checkpoint会极大的影响数据库的性能,这也是log
file不能设置的太小的主要原因;
3)在执行一些管理命令时要求刷新redo log文件,比如关闭数据库;
这里再简要总结一下一个log record的“生命周期”:
1. redo log record首先由mtr生成并保存在mtr的local buffer中。这里保存的redo log
record需要记录数据库恢复阶段所需的所有信息,并且要求恢复操作是幂等的;
2. 当mtr_commit被调用后,redo log record被记录在全局内存的log buffer之中;
3. 根据需要(需要额外的空间?事务commit?),redo log
buffer将会write(+flush)到磁盘上的redo log文件中,此时redo log已经被安全的保存起来;
4. mtr_commit执行时会给每个log record生成一个lsn,此lsn确定了其在log
file中的位置;
5. lsn同时是联系redo log和dirty page的纽带,WAL要求redo
log在刷脏前写入磁盘,同时,如果lsn相关联的页面都已经写入了磁盘,那么磁盘上redo log file中对应的log
record空间可以被循环利用;
6. 数据库恢复阶段,使用被持久化的redo log来恢复数据库;
接下来介绍redo log在数据库恢复阶段所起的重要作用。
Log Recovery
InnoDB的recovery的函数入口是innobase_start_or_create_for_mysql,其在mysql启动时由innobase_init函数调用。我们接下来看下源码,在此函数内可以看到如下两个函数调用:
1. recv_recovery_from_checkpoint_start
2. recv_recovery_from_checkpoint_finish
代码注释中特意强调,在任何情况下,数据库启动时都会尝试执行recovery操作,这是作为函数启动时正常代码路径的一部分。
主要恢复工作在第一个函数内完成,第二个函数做扫尾清理工作。这里,直接看函数的注释可以清楚函数的具体工作是什么。
146 /** Wrapper for recv_recovery_from_checkpoint_start_func(). 147 Recovers from a checkpoint. When this function returns, the database is able 148 to start processing of new user transactions, but the function 149 recv_recovery_from_checkpoint_finish should be called later to complete 150 the recovery and free the resources used in it. 151 @param type in: LOG_CHECKPOINT or LOG_ARCHIVE 152 @param lim in: recover up to this log sequence number if possible 153 @param min in: minimum flushed log sequence number from data files 154 @param max in: maximum flushed log sequence number from data files 155 @return error code or DB_SUCCESS */ 156 # define recv_recovery_from_checkpoint_start(type,lim,min,max) 157 recv_recovery_from_checkpoint_start_func(type,lim,min,max)
与log_t结构体相对应,恢复阶段也有一个结构体,叫做recv_sys_t,这个结构体在recv_recovery_from_checkpoint_start函数中通过recv_sys_create和recv_sys_init两个函数初始化。recv_sys_t中同样有几个和lsn相关的字段,这里做下介绍。
|
recv_sys->limit_lsn |
恢复应该执行到的最大的LSN值,这里赋值为LSN_MAX(uint64_t的最大值) |
|
recv_sys->parse_start_lsn |
恢复解析日志阶段所使用的最起始的LSN值,这里等于最后一次执行checkpoint对应的LSN值 |
|
recv_sys->scanned_lsn |
当前扫描到的LSN值 |
|
recv_sys->recovered_lsn |
当前恢复到的LSN值,此值小于等于recv_sys->scanned_lsn |
在获取start_lsn后,recv_recovery_from_checkpoint_start函数调用recv_group_scan_log_recs函数读取及解析log
records。
我们重点看下recv_group_scan_log_recs函数:
2908 /*******************************************************//** 2909 Scans log from a buffer and stores new log data to the parsing buffer. Parses 2910 and hashes the log records if new data found. */ 2911 static 2912 void 2913 recv_group_scan_log_recs( 2914 /*=====================*/ 2915 log_group_t* group, /*!< in: log group */ 2916 lsn_t* contiguous_lsn, /*!< in/out: it is known that all log 2917 groups contain contiguous log data up 2918 to this lsn */ 2919 lsn_t* group_scanned_lsn)/*!< out: scanning succeeded up to 2920 this lsn */ 2930 while (!finished) { 2931 end_lsn = start_lsn + RECV_SCAN_SIZE; 2932 2933 log_group_read_log_seg(LOG_RECOVER, log_sys->buf, 2934 group, start_lsn, end_lsn); 2935 2936 finished = recv_scan_log_recs( 2937 (buf_pool_get_n_pages() 2938 - (recv_n_pool_free_frames * srv_buf_pool_instances)) 2939 * UNIV_PAGE_SIZE, 2940 TRUE, log_sys->buf, RECV_SCAN_SIZE, 2941 start_lsn, contiguous_lsn, group_scanned_lsn); 2942 start_lsn = end_lsn; 2943 }
此函数内部是一个while循环。log_group_read_log_seg函数首先将log
record读取到一个内存缓冲区中(这里是log_sys->buf),接着调用recv_scan_log_recs函数用来解析这些log
record。解析过程会计算log block的checksum以及block
no和lsn是否对应。解析过程完成后,解析结果会存入recv_sys->addr_hash维护的hash表中。这个hash表的key是通过space
id和page number计算得到,value是一组应用到指定页面的经过解析后的log record,这里不再展开。
上述步骤完成后,recv_apply_hashed_log_recs函数可能会在recv_group_scan_log_recs或recv_recovery_from_checkpoint_start函数中调用,此函数将addr_hash中的log应用到特定的page上。此函数会调用recv_recover_page函数做真正的page
recovery操作,此时会判断页面的lsn要比log record的lsn小。
105 /** Wrapper for recv_recover_page_func(). 106 Applies the hashed log records to the page, if the page lsn is less than the 107 lsn of a log record. This can be called when a buffer page has just been 108 read in, or also for a page already in the buffer pool. 109 @param jri in: TRUE if just read in (the i/o handler calls this for 110 a freshly read page) 111 @param block in/out: the buffer block 112 */ 113 # define recv_recover_page(jri, block) recv_recover_page_func(jri, block)
如上就是整个页面的恢复流程。
附一个问题环节,后续会将redo log相关的问题记录在这里。
1. Q: Log_file, Log_block, Log_record的关系?
A: Log_file由一组log block组成,每个log block都是固定大小的。log block中除了header\tailer以外的字节都是记录的log record
2. Q: 是不是每一次的Commit,产生的应该是一个Log_block ?
A: 这个不一定的。写入log_block由mtr_commit确定,而不是事务提交确定。看log record大小,如果大小不需要跨log block,就会继续在当前的log block中写 。
3. Q: Log_record的结构又是怎么样的呢?
A: 这个结构很多,也没有细研究,具体看后边登博图中的简要介绍吧;
4. Q: 每个Block应该有下一个Block的偏移吗,还是顺序即可,还是记录下一个的Block_number
A: block都是固定大小的,顺序写的
5. Q: 那如何知道这个Block是不是完整的,是不是依赖下一个Block呢?
A: block开始有2个字节记录 此block中第一个mtr开始的位置,如果这个值是0,证明还是上一个block的同一个mtr。
6. Q: 一个事务是不是需要多个mtr_commit
A: 是的。mtr的m == mini;
7. Q: 这些Log_block是不是在Commit的时候一起刷到当中?
A: mtr_commit时会写入log buffer,具体什么时候写到log file就不一定了
8. Q: 那LSN是如何写的呢?
A: lsn就是相当于在log file中的位置,那么在写入log buffer时就会确定这个lsn的大小了 。当前只有一个log buffer,在log buffer中的位置和在log file中的位置是一致的
9. Q: 那我Commit的时候做什么事情呢?
A: 可能写log 、也可能不写,由innodb_flush_log_at_trx_commit这个参数决定啊
10. Q: 这两个值是干嘛用的: LOG_CHECKPOINT_1/LOG_CHECKPOINT_2
A: 这两个可以理解为log file头信息的一部分(占用文件头第二和第四个block),每次执行checkpoint都需要更新这两个字段,后续恢复时,每个页面对应lsn中比这个checkpoint值小的,认为是已经写入了,不需要再恢复
A: Log_file由一组log block组成,每个log block都是固定大小的。log block中除了header\tailer以外的字节都是记录的log record
2. Q: 是不是每一次的Commit,产生的应该是一个Log_block ?
A: 这个不一定的。写入log_block由mtr_commit确定,而不是事务提交确定。看log record大小,如果大小不需要跨log block,就会继续在当前的log block中写 。
3. Q: Log_record的结构又是怎么样的呢?
A: 这个结构很多,也没有细研究,具体看后边登博图中的简要介绍吧;
4. Q: 每个Block应该有下一个Block的偏移吗,还是顺序即可,还是记录下一个的Block_number
A: block都是固定大小的,顺序写的
5. Q: 那如何知道这个Block是不是完整的,是不是依赖下一个Block呢?
A: block开始有2个字节记录 此block中第一个mtr开始的位置,如果这个值是0,证明还是上一个block的同一个mtr。
6. Q: 一个事务是不是需要多个mtr_commit
A: 是的。mtr的m == mini;
7. Q: 这些Log_block是不是在Commit的时候一起刷到当中?
A: mtr_commit时会写入log buffer,具体什么时候写到log file就不一定了
8. Q: 那LSN是如何写的呢?
A: lsn就是相当于在log file中的位置,那么在写入log buffer时就会确定这个lsn的大小了 。当前只有一个log buffer,在log buffer中的位置和在log file中的位置是一致的
9. Q: 那我Commit的时候做什么事情呢?
A: 可能写log 、也可能不写,由innodb_flush_log_at_trx_commit这个参数决定啊
10. Q: 这两个值是干嘛用的: LOG_CHECKPOINT_1/LOG_CHECKPOINT_2
A: 这两个可以理解为log file头信息的一部分(占用文件头第二和第四个block),每次执行checkpoint都需要更新这两个字段,后续恢复时,每个页面对应lsn中比这个checkpoint值小的,认为是已经写入了,不需要再恢复
文章最后,将网易杭研院何登成博士-登博博客上的一个log block的结构图放在这,再画图也不会比登博这张图画的更清晰了,版权属于登博。
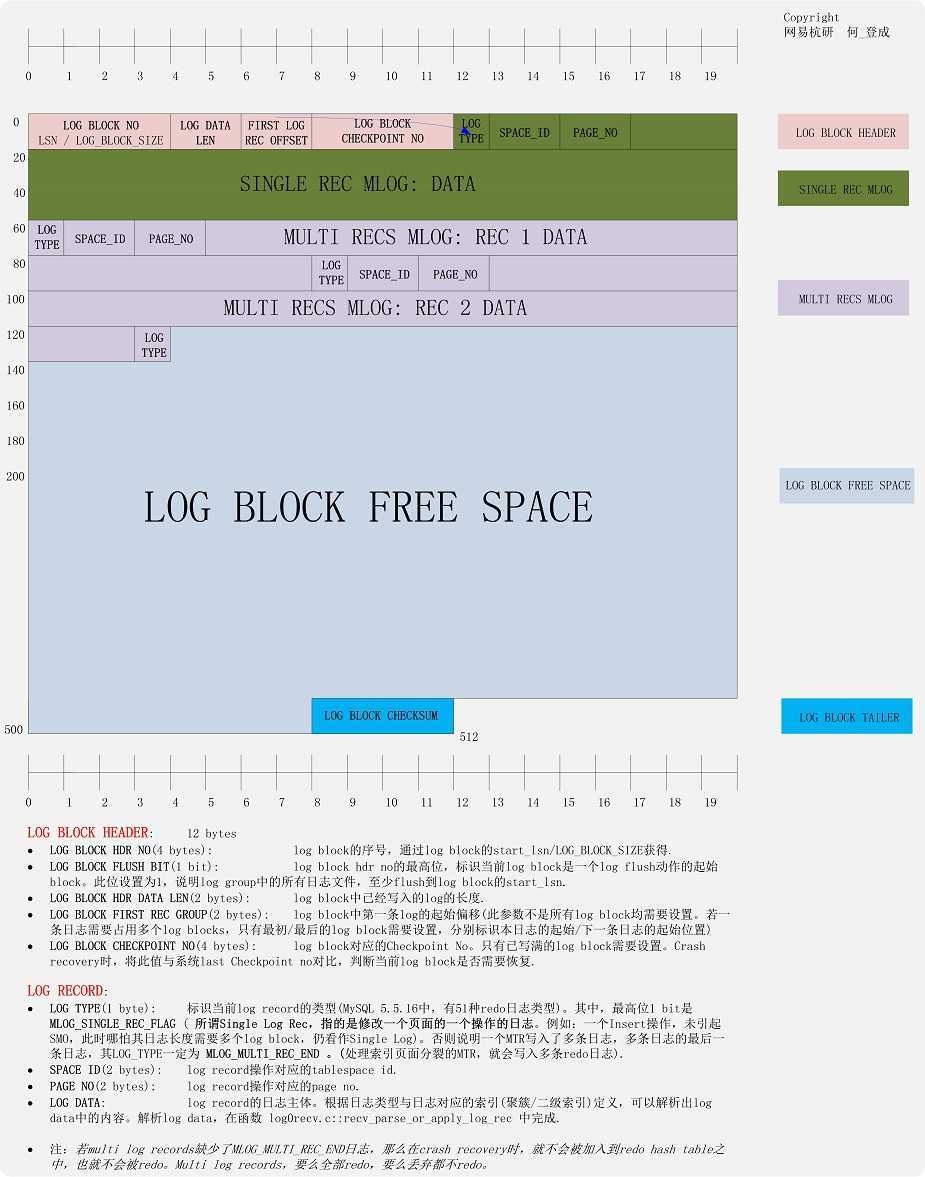
评论(0)