Linux内核架构读书笔记 - 2.5.2 数据结构
时间:2014-04-29 23:32:17
收藏:0
阅读:809
调度系统各个组建关系如下
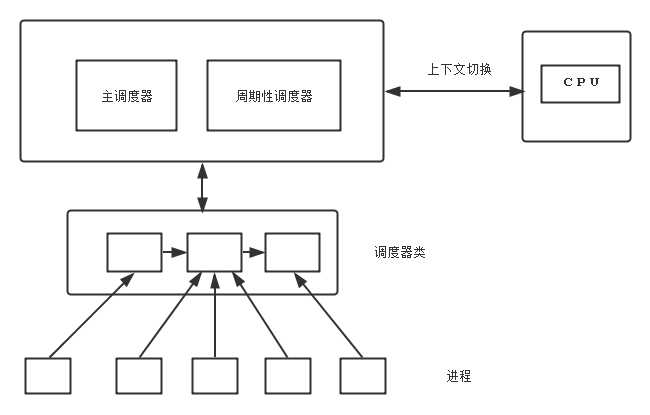
- 激活调度器两种方法:进程睡眠或其他原因放弃CPU,周期性检测 上述两个组件统称为通用调度器或核心调度器.
- 调度器用于判断接下来运行那个进程,内核支持不同的调度策略( 完全公平调度 实时调度 无事可做的空闲调度进程)
- 调度器被调用时候 需要执行体系相关的进程上下文切换
- 每个进程属于某个调度器类,各个调度器负责管理所属进程,通用调度器不涉及进程管理,都由调度器来
下面分别讲述:
- task_struct 成员
-
- sched.h

1 struct task_struct { 2 3 ... 4 int prio, static_prio, normal_prio; 5 6 const struct sched_class *sched_class; 7 struct sched_entity se; 8 unsigned int rt_priority; 9 10 unsigned int policy; 11 cpumask_t cpus_allowed; 12 unsigned int time_slice; 13 14 ... 15 16 }
- 进程由优先级, task_struct 采用三个成员表示进程的优先级:prio 和 normal_prio 表示动态优先级,static_prio 表示进程的静态优先级,static 在启动时候确定,可通过nice和sched_setscheduler系统调用修改, normal_Prio 表示基于静态优先级和调度策略计算出的优先级,调度器考虑的优先级保存在prio,某些状态下内核需要暂时提高进程的优先级,因此优先级用三个变量保存
- rt_priority 表示实时进程的优先级,0- 99,与上面不冲突,优先级之间关系在下文由文章专门讲述
- sched_class 进程的调度器类
- sched_entity 调度实体,调度器不只局限与进程,还可以处理调度更大的实体.eg组调度,CPU现在进程组分配,然后组内在分配
- policy 调度策略
- SCHED_NORMAL 普通进程,通过完全公平调度器处理
- SCHED_BATCH SCHED_IDLE 通过完全公平调度器处理,一般用于次要进程.SCHED_BATCH用于非交互CPU使用密集的批处理程,SCHED_IDLE 权重比较小,注意SCHED_IDLE 不负责处理空闲进程,这由内核来单独处理
- SCHED_RR SCHED_FIFO 用于实现软实时方法,SCHED_RR使用了一种循环,SCHED_FIFO使用先进先出机制
- 辅助函数rt_policy 用于判断进程是否属于实时类 (SCHED_RR SCHED_FIFO)
- task_has_rt_policy 用于对给定进程判断该性质
- CPU_ALLOWED用于限定CPU在那个CPU上面运行
- run_list time_slice 循环实时调度器需要的,但是不用与完全公平调度器run_list 维护进程列表 time_slice 指定进程可以使用的CPU剩余时间段
- sched.h
-
- 调度器类
- sched.h
1 struct sched_class { 2 const struct sched_class *next; 3 4 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup); 5 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep); 6 void (*yield_task) (struct rq *rq); 7 8 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p); 9 10 struct task_struct * (*pick_next_task) (struct rq *rq); 11 void (*put_prev_task) (struct rq *rq, struct task_struct *p); 12 13 #ifdef CONFIG_SMP 14 unsigned long (*load_balance) (struct rq *this_rq, int this_cpu, 15 struct rq *busiest, unsigned long max_load_move, 16 struct sched_domain *sd, enum cpu_idle_type idle, 17 int *all_pinned, int *this_best_prio); 18 19 int (*move_one_task) (struct rq *this_rq, int this_cpu, 20 struct rq *busiest, struct sched_domain *sd, 21 enum cpu_idle_type idle); 22 #endif 23 24 void (*set_curr_task) (struct rq *rq); 25 void (*task_tick) (struct rq *rq, struct task_struct *p); 26 void (*task_new) (struct rq *rq, struct task_struct *p); 27 };
- enqueue_task 向就绪队列添加一个进程,进程被唤醒时候会调用
- dequeue_task 提供与上述的逆向操作
- 进程放弃CPU的时候,可以使用sched_yield,内核会调用yield_task
- 在必要的条件下,会调 check_preempt_curr,用来唤醒一个新的进程来抢占当前进程,eg在wake_up_new_task唤醒新的进程时候会调用
- pick_next_task 选择下一个将要运行的进程,put_prev_task 用于另一个进程代替当前进程之前调用.
- 在进程的调度策略发生变化时,需要调用set_curr_task
- task_tick在每次激活周期性调度器时候,由周期性调度器调用
- new_task用于建立fork 系统调用和调度器之间的关系,新进程建立时候 ,用new_task通知调度器
- activate_task deactivate_task 提供进程在就绪队列入队和出队的功能,此外他们还更新内核的统计数据
- 内核定义了便捷的方法check_preempt_curr 调用进程相关的 check_preempt_curr 方法
进程无法之间与调度器类交互,由|SCHED_XYX与之映射
SCHED_NORMA
SCHED_BATCH -> fair_sched_class 完全公平调度器
SCHED_IDLE
SCHED_RR
->rt_sched_class 实时调度器
SCHED_FIFO
3 就绪队列
-
- 调度器管理活动进程的数据结构称之为就绪队列
1 /* 2 * This is the main, per-CPU runqueue data structure. 3 * 4 * Locking rule: those places that want to lock multiple runqueues 5 * (such as the load balancing or the thread migration code), lock 6 * acquire operations must be ordered by ascending &runqueue. 7 */ 8 struct rq { 9 /* runqueue lock: */ 10 spinlock_t lock; 11 12 /* 13 * nr_running and cpu_load should be in the same cacheline because 14 * remote CPUs use both these fields when doing load calculation. 15 */ 16 unsigned long nr_running; 17 #define CPU_LOAD_IDX_MAX 5 18 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; 19 unsigned char idle_at_tick; 20 #ifdef CONFIG_NO_HZ 21 unsigned char in_nohz_recently; 22 #endif 23 /* capture load from *all* tasks on this cpu: */ 24 struct load_weight load; 25 unsigned long nr_load_updates; 26 u64 nr_switches; 27 28 struct cfs_rq cfs; 29 #ifdef CONFIG_FAIR_GROUP_SCHED 30 /* list of leaf cfs_rq on this cpu: */ 31 struct list_head leaf_cfs_rq_list; 32 #endif 33 struct rt_rq rt; 34 35 /* 36 * This is part of a global counter where only the total sum 37 * over all CPUs matters. A task can increase this counter on 38 * one CPU and if it got migrated afterwards it may decrease 39 * it on another CPU. Always updated under the runqueue lock: 40 */ 41 unsigned long nr_uninterruptible; 42 43 struct task_struct *curr, *idle; 44 unsigned long next_balance; 45 struct mm_struct *prev_mm; 46 47 u64 clock, prev_clock_raw; 48 s64 clock_max_delta; 49 50 unsigned int clock_warps, clock_overflows; 51 u64 idle_clock; 52 unsigned int clock_deep_idle_events; 53 u64 tick_timestamp; 54 55 atomic_t nr_iowait; 56 57 ... 58 struct lock_class_key rq_lock_key; 59 };
- nr_running 队列上可运行的进程数目
- load就绪队列当前负载的度量
- CPU_LOAD跟踪此前的负载状态
- cfs rt 嵌入的子就绪队列,分别用于完全公平调度器和实时调度器
- curr 当前运行的进程task_struct 实例
- idle 没看懂....
- clock prev_raw_clock 用于实现就绪队列自身的时钟
- kernel/sched.c
-
static DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
- 所有就绪队列都在runqueues 数组中,一个CPU一个
- CPU 定义的一些宏方便操作
-
1 #define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) 2 #define this_rq() (&__get_cpu_var(runqueues)) 3 #define task_rq(p) cpu_rq(task_cpu(p)) 4 #define cpu_curr(cpu) (cpu_rq(cpu)->curr)
- 调度器管理活动进程的数据结构称之为就绪队列
4 调度实体
1 /* 2 * CFS stats for a schedulable entity (task, task-group etc) 3 * 4 * Current field usage histogram: 5 * 6 * 4 se->block_start 7 * 4 se->run_node 8 * 4 se->sleep_start 9 * 6 se->load.weight 10 */ 11 struct sched_entity { 12 struct load_weight load; /* for load-balancing */ 13 struct rb_node run_node; 14 unsigned int on_rq; 15 16 u64 exec_start; 17 u64 sum_exec_runtime; 18 u64 vruntime; 19 u64 prev_sum_exec_runtime; 20 21 };
- load指定了权重,决定了各个实体占队列总负载的比例,下一节会详细讲述
- run_node 树节点,使得实体可以在红黑树上面排序
- on_req 表示该实体是否在就绪队列上接受调度
- sum_exec_runtime 记录消耗CPU的时间.update_curr 会跟踪运行时间,进程执行期间虚拟时钟上面流失的时间由vruntime
- 进程撤销时候,当前sum_exec_runtime 保存到prev_exec_runtime ,此后进程抢占需要该数据,注意prev_exec_runtime 保存sum_exec_runtime,sum_exec_runtime会持续增长
- 每个task_struct 嵌入sched_entity ,进程是可调度实体,反过来并不成立
评论(0)