第 7 章 MySQL 数据库锁定机制
7.1 MySQL 锁定机制简介
数据库锁定机制简单来说就是数据库为了保证数据的一致性而使各种共享资源在被并发访问访问变
得有序所设计的一种规则。对于任何一种数据库来说都需要有相应的锁定机制,所以MySQL
自然也不能
例外。MySQL
数据库由于其自身架构的特点,存在多种数据存储引擎,每种存储引擎所针对的应用场景特
点都不太一样,为了满足各自特定应用场景的需求,每种存储引擎的锁定机制都是为各自所面对的特定
场景而优化设计,所以各存储引擎的锁定机制也有较大区别。
总的来说,MySQL 各存储引擎使用了三种类型(级别)的锁定机制:行级锁定,页级锁定和表级锁
定。下面我们先分析一下MySQL
这三种锁定的特点和各自的优劣所在。
●
行级锁定(row-level)
行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒
度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的
并发处理能力而提高一些需要高并发应用系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源
的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行
级锁定也最容易发生死锁。
● 表级锁定(table-level)
和行级锁定相反,表级别的锁定是MySQL
各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的
特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一
次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大
打折扣。
● 页级锁定(page-level)
页级锁定是MySQL
中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁
定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的
并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
在数据库实现资源锁定的过程中,随着锁定资源颗粒度的减小,锁定相同数据量的数据所需要消耗
的内存数量是越来越多的,实现算法也会越来越复杂。不过,随着锁定资源颗粒度的减小,应用程序的
访问请求遇到锁等待的可能性也会随之降低,系统整体并发度也随之提升。
在MySQL
数据库中,使用表级锁定的主要是MyISAM,Memory,CSV 等一些非事务性存储引擎,而使用
行级锁定的主要是Innodb 存储引擎和NDB
Cluster 存储引擎,页级锁定主要是BerkeleyDB 存储引擎的锁
定方式。
MySQL
的如此的锁定机制主要是由于其最初的历史所决定的。在最初,MySQL 希望设计一种完全独立
于各种存储引擎的锁定机制,而且在早期的MySQL
数据库中,MySQL 的存储引擎(MyISAM
和Momery)的
设计是建立在“任何表在同一时刻都只允许单个线程对其访问(包括读)”这样的假设之上。但是,随
着MySQL
的不断完善,系统的不断改进,在MySQL3.23 版本开发的时候,MySQL
开发人员不得不修正之前
的假设。因为他们发现一个线程正在读某个表的时候,另一个线程是可以对该表进行insert 操作的,只
不过只能INSERT
到数据文件的最尾部。这也就是从MySQL 从3.23 版本开始提供的我们所说的Concurrent
Insert。
当出现Concurrent Insert 之后,MySQL
的开发人员不得不修改之前系统中的锁定实现功能,但是仅
仅只是增加了对Concurrent Insert
的支持,并没有改动整体架构。可是在不久之后,随着BerkeleyDB
存储引擎的引入,之前的锁定机制遇到了更大的挑战。因为BerkeleyDB存储引擎并没有MyISAM
和Memory
存储引擎同一时刻只允许单一线程访问某一个表的限制,而是将这个单线程访问限制的颗粒度缩小到了
单个page,这又一次迫使MySQL
开发人员不得不再一次修改锁定机制的实现。
由于新的存储引擎的引入,导致锁定机制不能满足要求,让MySQL
的人意识到已经不可能实现一种
完全独立的满足各种存储引擎要求的锁定实现机制。如果因为锁定机制的拙劣实现而导致存储引擎的整
体性能的下降,肯定会严重打击存储引擎提供者的积极性,这是MySQL
公司非常不愿意看到的,因为这
完全不符合MySQL
的战略发展思路。所以工程师们不得不放弃了最初的设计初衷,在锁定实现机制中作
出修改,允许存储引擎自己改变MySQL
通过接口传入的锁定类型而自行决定该怎样锁定数据。
7.2 各种锁定机制分析
在整体了解了MySQL 锁定机制之后,这一节我们将详细分析MySQL
自身提供的表锁定机制和其他储引
擎实自身实现的行锁定机制,并通过MyISAM 存储引擎和Innodb
存储引擎实例演示。
表级锁定
MySQL 的表级锁定主要分为两种类型,一种是读锁定,另一种是写锁定。在MySQL
中,主要通过四个
队列来维护这两种锁定:两个存放当前正在锁定中的读和写锁定信息,另外两个存放等待中的读写锁定
信息,如下:
? Current
read-lock queue (lock->read)
? Pending read-lock queue
(lock->read_wait)
? Current write-lock queue (lock->write)
? Pending
write-lock queue (lock->write_wait)
当前持有读锁的所有线程的相关信息都能够在Current read-lock queue
中找到,队列中的信息按
照获取到锁的时间依序存放。而正在等待锁定资源的信息则存放在Pending read-lock queue
里面,另
外两个存放写锁信息的队列也按照上面相同规则来存放信息。
虽然对于我们这些使用者来说MySQL
展现出来的锁定(表锁定)只有读锁定和写锁定这两种类型,
但是在MySQL 内部实现中却有多达11
种锁定类型,由系统中一个枚举量(thr_lock_type)定义,各值描
述如下:
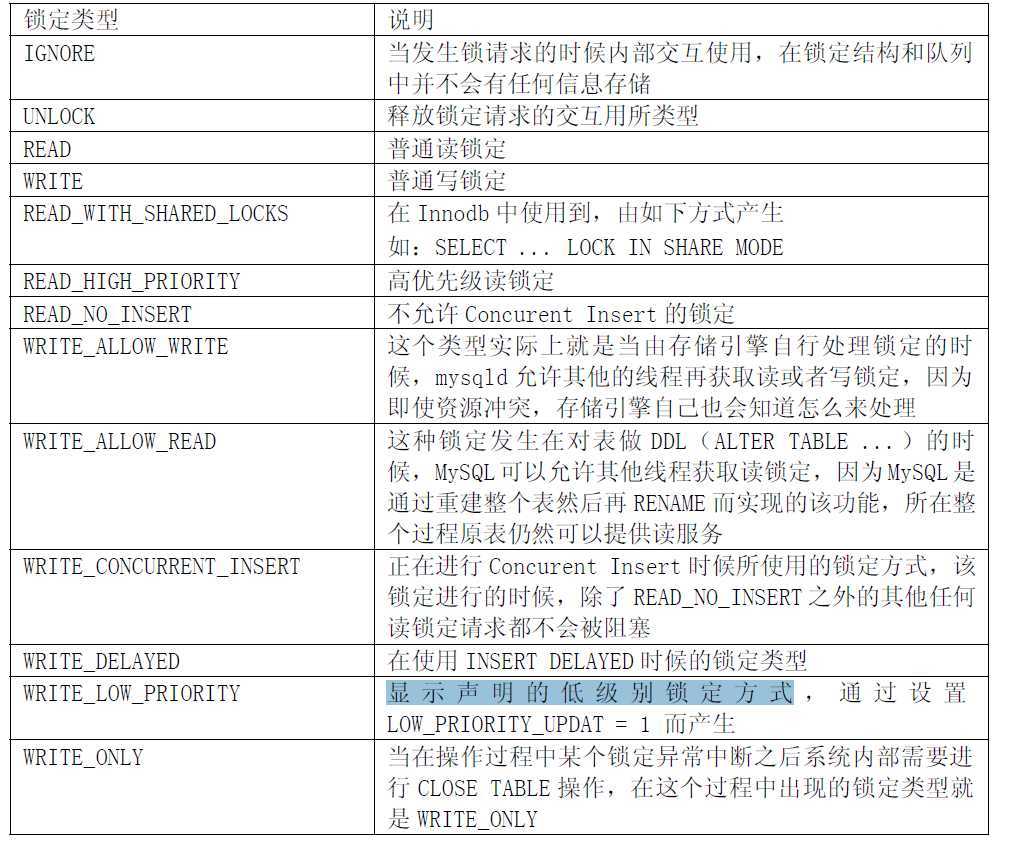
读锁定
一个新的客户端请求在申请获取读锁定资源的时候,需要满足两个条件:
1、请求锁定的资源当前没有被写锁定;
2、写锁定等待队列(Pending
write-lock queue)中没有更高优先级的写锁定等待;
如果满足了上面两个条件之后,该请求会被立即通过,并将相关的信息存入Current
read-lock
queue 中,而如果上面两个条件中任何一个没有满足,都会被迫进入等待队列Pending read-lock
queue
中等待资源的释放。
写锁定
当客户端请求写锁定的时候,MySQL 首先检查在Current write-lock queue
是否已经有锁定相同资
源的信息存在。
如果Current write-lock queue 没有,则再检查Pending write-lock
queue,如果在Pending
write-lock queue
中找到了,自己也需要进入等待队列并暂停自身线程等待锁定资源。反之,如果
Pending write-lock queue 为空,则再检测Current
read-lock queue,如果有锁定存在,则同样需要
进入Pending write-lock queue
等待。当然,也可能遇到以下这两种特殊情况:
1. 请求锁定的类型为WRITE_DELAYED;
2.
请求锁定的类型为WRITE_CONCURRENT_INSERT 或者是TL_WRITE_ALLOW_WRITE, 同时
Current read lock
是READ_NO_INSERT 的锁定类型。
当遇到这两种特殊情况的时候,写锁定会立即获得而进入Current write-lock queue
中
当遇到这两种特殊情况的时候,写锁定会立即获得而进入Current write-lock queue 中
如果刚开始第一次检测就Current
write-lock queue 中已经存在了锁定相同资源的写锁定存在,那
么就只能进入等待队列等待相应资源锁定的释放了。
写锁定出现在Current write-lock queue 之后,会阻塞除了以下情况下的所有其他锁定的请求:
1.
在某些存储引擎的允许下,可以允许一个WRITE_CONCURRENT_INSERT 写锁定请求
2. 写锁定为WRITE_ALLOW_WRITE
的时候,允许除了WRITE_ONLY 之外的所有读和写锁定请求
3. 写锁定为WRITE_ALLOW_READ
的时候,允许除了READ_NO_INSERT 之外的所有读锁定请求
4. 写锁定为WRITE_DELAYED 的时候,允许除了READ_NO_INSERT
之外的所有读锁定请求
5. 写锁定为WRITE_CONCURRENT_INSERT 的时候,允许除了READ_NO_INSERT
之外的所有读锁定请求
随着MySQL 存储引擎的不断发展,目前MySQL 自身提供的锁定机制已经没有办法满足需求了,很多存
储引擎都在MySQL
所提供的锁定机制之上做了存储引擎自己的扩展和改造。
MyISAM 存储引擎基本上可以说是对MySQL
所提供的锁定机制所实现的表级锁定依赖最大的一种存储
引擎了,虽然MyISAM
存储引擎自己并没有在自身增加其他的锁定机制,但是为了更好的支持相关特性,
MySQL 在原有锁定机制的基础上为了支持其Concurrent Insert
的特性而进行了相应的实现改造。
而其他几种支持事务的存储存储引擎,如Innodb,NDB Cluster 以及Berkeley DB 存储引擎则是让
MySQL
将锁定的处理直接交给存储引擎自己来处理,在MySQL 中仅持有WRITE_ALLOW_WRITE 类型的锁定。
由于MyISAM 存储引擎使用的锁定机制完全是由MySQL 提供的表级锁定实现,所以下面我们将以
MyISAM
存储引擎作为示例存储引擎,来实例演示表级锁定的一些基本特性。由于,为了让示例更加直
观,我将使用显示给表加锁来演示:

行级锁定
行级锁定不是MySQL 自己实现的锁定方式,而是由其他存储引擎自己所实现的,如广为大家所知的
Innodb
存储引擎,以及MySQL 的分布式存储引擎NDB Cluster 等都是实现了行级锁定。
Innodb
锁定模式及实现机制
考虑到行级锁定君由各个存储引擎自行实现,而且具体实现也各有差别,而Innodb
是目前事务型存
储引擎中使用最为广泛的存储引擎,所以这里我们就主要分析一下Innodb 的锁定特性。
总的来说,Innodb 的锁定机制和Oracle 数据库有不少相似之处。Innodb
的行级锁定同样分为两种类
型,共享锁和排他锁,而在锁定机制的实现过程中为了让行级锁定和表级锁定共存, Innodb
也同样使用
了意向锁(表级锁定)的概念,也就有了意向共享锁和意向排他锁这两种。
当一个事务需要给自己需要的某个资源加锁的时候,如果遇到一个共享锁正锁定着自己需要的资源
的时候,自己可以再加一个共享锁,不过不能加排他锁。但是,如果遇到自己需要锁定的资源已经被一
个排他锁占有之后,则只能等待该锁定释放资源之后自己才能获取锁定资源并添加自己的锁定。而意向
锁的作用就是当一个事务在需要获取资源锁定的时候,如果遇到自己需要的资源已经被排他锁占用的时
候,该事务可以需要锁定行的表上面添加一个合适的意向锁。如果自己需要一个共享锁,那么就在表上
面添加一个意向共享锁。而如果自己需要的是某行(或者某些行)上面添加一个排他锁的话,则先在表
上面添加一个意向排他锁。意向共享锁可以同时并存多个,但是意向排他锁同时只能有一个存在。所
以,可以说Innodb
的锁定模式实际上可以分为四种:共享锁(S),排他锁(X),意向共享锁(IS)和
意向排他锁(IX),我们可以通过以下表格来总结上面这四种所的共存逻辑关系:
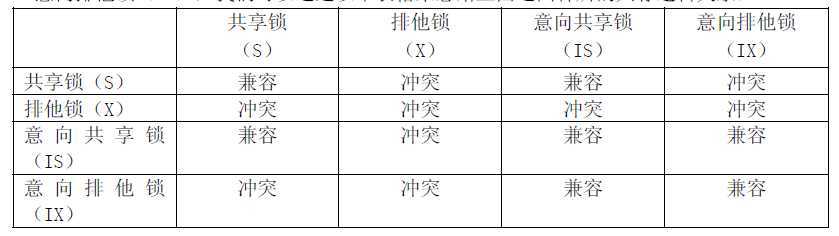
虽然Innodb 的锁定机制和Oracle 有不少相近的地方,但是两者的实现确是截然不同的。总的来说就
是Oracle
锁定数据是通过需要锁定的某行记录所在的物理block
上的事务槽上表级锁定信息,而Innodb
的锁定则是通过在指向数据记录的第一个索引键之前和最后一个索引键之后的空域空间上标记锁定信息
而实现的。Innodb
的这种锁定实现方式被称为“NEXT-KEY locking”(间隙锁),因为Query
执行过程
中通过过范围查找的华,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。
间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜
的锁定,而造成在锁定的时候无法插入锁定键值范围内的任何数据。在某些场景下这可能会对性能造成
很大的危害。而Innodb
给出的解释是为了组织幻读的出现,所以他们选择的间隙锁来实现锁定。
除了间隙锁给Innodb 带来性能的负面影响之外,通过索引实现锁定的方式还存在其他几个较大的性能
隐患:
● 当Query 无法利用索引的时候,Innodb 会放弃使用行级别锁定而改用表级别的锁定,造成并发
性能的降低;
● 当Quuery
使用的索引并不包含所有过滤条件的时候,数据检索使用到的索引键所只想的数据可
能有部分并不属于该Query
的结果集的行列,但是也会被锁定,因为间隙锁锁定的是一个范
围,而不是具体的索引键;
● 当Query
在使用索引定位数据的时候,如果使用的索引键一样但访问的数据行不同的时候(索
引只是过滤条件的一部分),一样会被锁定
Innodb 各事务隔离级别下锁定及死锁
Innodb 实现的在ISO/ANSI SQL92 规范中所定义的Read
UnCommited,Read Commited,Repeatable
Read 和Serializable
这四种事务隔离级别。同时,为了保证数据在事务中的一致性,实现了多版本数据
访问。
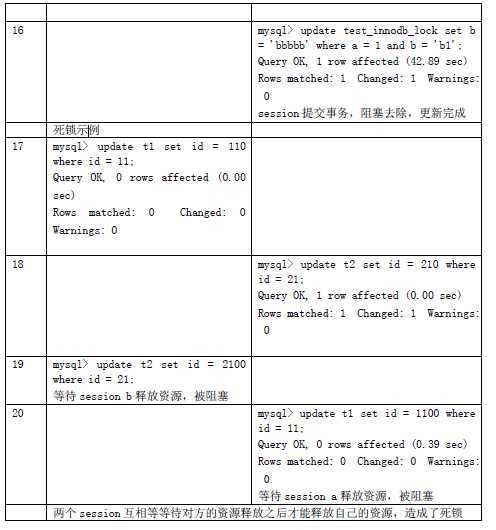
之前在第一节中我们已经介绍过,行级锁定肯定会带来死锁问题,Innodb
也不可能例外。至于死锁
的产生过程我们就不在这里详细描述了,在后面的锁定示例中会通过一个实际的例子为大家爱展示死锁
的产生过程。这里我们主要介绍一下,在Innodb
中当系检测到死锁产生之后是如何来处理的。
在Innodb
的事务管理和锁定机制中,有专门检测死锁的机制,会在系统中产生死锁之后的很短时间
内就检测到该死锁的存在。当Innodb
检测到系统中产生了死锁之后,Innodb 会通过相应的判断来选这产
生死锁的两个事务中较小的事务来回滚,而让另外一个较大的事务成功完成。那Innodb
是以什么来为标
准判定事务的大小的呢?MySQL 官方手册中也提到了这个问题,实际上在Innodb
发现死锁之后,会计算
出两个事务各自插入、更新或者删除的数据量来判定两个事务的大小。也就是说哪个事务所改变的记录
条数越多,在死锁中就越不会被回滚掉。但是有一点需要注意的就是,当产生死锁的场景中涉及到不止
Innodb
存储引擎的时候,Innodb 是没办法检测到该死锁的,这时候就只能通过锁定超时限制来解决该死
锁了。另外,死锁的产生过程的示例将在本节最后的Innodb
锁定示例中演示。
Innodb 锁定机制示例
mysql> create table test_innodb_lock (a int(11),b
varchar(16)) engine=innodb;
Query OK, 0 rows affected (0.02 sec)
mysql>
create index test_innodb_a_ind on test_innodb_lock(a);
Query OK, 0 rows
affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create
index test_innodb_lock_b_ind on test_innodb_lock(b);
Query OK, 11 rows
affected (0.01 sec)
Records: 11 Duplicates: 0 Warnings: 0



7.3 合理利用锁机制优化MySQL
MyISAM 表锁优化建议
对于MyISAM
存储引擎,虽然使用表级锁定在锁定实现的过程中比实现行级锁定或者页级锁所带来的
附加成本都要小,锁定本身所消耗的资源也是最少。但是由于锁定的颗粒度比较到,所以造成锁定资源
的争用情况也会比其他的锁定级别都要多,从而在较大程度上会降低并发处理能力。
所以,在优化MyISAM
存储引擎锁定问题的时候,最关键的就是如何让其提高并发度。由于锁定级别
是不可能改变的了,所以我们首先需要尽可能让锁定的时间变短,然后就是让可能并发进行的操作尽可
能的并发。
1、缩短锁定时间
缩短锁定时间,短短几个字,说起来确实听容易的,但实际做起来恐怕就并不那么简单了。如何让
锁定时间尽可能的短呢?唯一的办法就是让我们的Query
执行时间尽可能的短。
a) 尽两减少大的复杂Query,将复杂Query 分拆成几个小的Query 分布进行;
b)
尽可能的建立足够高效的索引,让数据检索更迅速;
c) 尽量让MyISAM 存储引擎的表只存放必要的信息,控制字段类型;
d)
利用合适的机会优化MyISAM 表数据文件;
2、分离能并行的操作
说到MyISAM 的表锁,而且是读写互相阻塞的表锁,可能有些人会认为在MyISAM
存储引擎的表上就只
能是完全的串行化,没办法再并行了。大家不要忘记了,MyISAM 的存储引擎还有一个非常有用的特性,
那就是Concurrent
Insert(并发插入)的特性。
MyISAM 存储引擎有一个控制是否打开Concurrent Insert
功能的参数选项:concurrent_insert,可
以设置为0,1 或者2。三个值的具体说明如下:
a)
concurrent_insert=2,无论MyISAM
存储引擎的表数据文件的中间部分是否存在因为删除数据
而留下的空闲空间,都允许在数据文件尾部进行Concurrent Insert;
b)
concurrent_insert=1,当MyISAM 存储引擎表数据文件中间不存在空闲空间的时候,可以从文
件尾部进行Concurrent
Insert;
c) concurrent_insert=0,无论MyISAM
存储引擎的表数据文件的中间部分是否存在因为删除数据
而留下的空闲空间,都不允许Concurrent Insert。
3、合理利用读写优先级
在本章各种锁定分析一节中我们了解到了MySQL
的表级锁定对于读和写是有不同优先级设定的,默
认情况下是写优先级要大于读优先级。所以,如果我们可以根据各自系统环境的差异决定读与写的优先
级。如果我们的系统是一个以读为主,而且要优先保证查询性能的话,我们可以通过设置系统参数选项
low_priority_updates=1,将写的优先级设置为比读的优先级低,即可让告诉MySQL
尽量先处理读请
求。当然,如果我们的系统需要有限保证数据写入的性能的话,则可以不用设置low_priority_updates
参数了。
这里我们完全可以利用这个特性,将concurrent_insert
参数设置为1,甚至如果数据被删除的可能
性很小的时候,如果对暂时性的浪费少量空间并不是特别的在乎的话,将concurrent_insert
参数设置
为2
都可以尝试。当然,数据文件中间留有空域空间,在浪费空间的时候,还会造成在查询的时候需要
读取更多的数据,所以如果删除量不是很小的话,还是建议将concurrent_insert
设置为1 更为合适。
Innodb 行锁优化建议
Innodb
存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁
定会要更高一些,但是在整体并发处理能力方面要远远优于MyISAM
的表级锁定的。当系统并发量较高的
时候,Innodb 的整体性能和MyISAM 相比就会有比较明显的优势了。但是,Innodb
的行级锁定同样也有其
脆弱的一面,当我们使用不当的时候,可能会让Innodb 的整体性能表现不仅不能比MyISAM 高,甚至可能
会更差。
要想合理利用Innodb 的行级锁定,做到扬长避短,我们必须做好以下工作:
a) 尽可能让所有的数据检索都通过索引来完成,从而避免Innodb
因为无法通过索引键加锁而升级
为表级锁定;
b) 合理设计索引,让Innodb
在索引键上面加锁的时候尽可能准确,尽可能的缩小锁定范围,避免
造成不必要的锁定而影响其他Query 的执行;
c)
尽可能减少基于范围的数据检索过滤条件,避免因为间隙锁带来的负面影响而锁定了不该锁定
的记录;
d)
尽量控制事务的大小,减少锁定的资源量和锁定时间长度;
e) 在业务环境允许的情况下,尽量使用较低级别的事务隔离,以减少MySQL
因为实现事务隔离级
别所带来的附加成本;
由于Innodb
的行级锁定和事务性,所以肯定会产生死锁,下面是一些比较常用的减少死锁产生概率
的的小建议,读者朋友可以根据各自的业务特点针对性的尝试:
a)
类似业务模块中,尽可能按照相同的访问顺序来访问,防止产生死锁;
b) 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
c)
对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁
产生的概率;
系统锁定争用情况查询
对于两种锁定级别,MySQL 内部有两组专门的状态变量记录系统内部锁资源争用情况,我们先看看
MySQL
实现的表级锁定的争用状态变量:
mysql> show status like
‘table%‘;
+-----------------------+-------+
| Variable_name | Value
|
+-----------------------+-------+
| Table_locks_immediate | 100 |
|
Table_locks_waited | 0
|
+-----------------------+-------+
这里有两个状态变量记录MySQL
内部表级锁定的情况,两个变量说明如下:
● Table_locks_immediate:产生表级锁定的次数;
●
Table_locks_waited:出现表级锁定争用而发生等待的次数;
两个状态值都是从系统启动后开始记录,没出现一次对应的事件则数量加1。如果这里的
Table_locks_waited
状态值比较高,那么说明系统中表级锁定争用现象比较严重,就需要进一步分析为
什么会有较多的锁定资源争用了。
对于Innodb 所使用的行级锁定,系统中是通过另外一组更为详细的状态变量来记录的,如下:
mysql> show status like
‘innodb_row_lock%‘;
+-------------------------------+--------+
|
Variable_name | Value |
+-------------------------------+--------+
|
Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 490578 |
|
Innodb_row_lock_time_avg | 37736 |
| Innodb_row_lock_time_max | 121411 |
|
Innodb_row_lock_waits | 13 |
+-------------------------------+--------+
Innodb
的行级锁定状态变量不仅记录了锁定等待次数,还记录了锁定总时长,每次平均时长,以及
最大时长,此外还有一个非累积状态量显示了当前正在等待锁定的等待数量。对各个状态量的说明如
下:
●
Innodb_row_lock_current_waits:当前正在等待锁定的数量;
●
Innodb_row_lock_time:从系统启动到现在锁定总时间长度;
●
Innodb_row_lock_time_avg:每次等待所花平均时间;
●
Innodb_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
●
Innodb_row_lock_waits:系统启动后到现在总共等待的次数;
对于这5 个状态变量,
比较重要的主要是Innodb_row_lock_time_avg( 等待平均时长)
,
Innodb_row_lock_waits(等待总次数)以及Innodb_row_lock_time(等待总时长)这三项。尤其是当等
待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后
根据分析结果着手指定优化计划。
此外,Innodb
出了提供这五个系统状态变量之外,还提供的其他更为丰富的即时状态信息供我们分
析使用。可以通过如下方法查看:
1. 通过创建Innodb Monitor 表来打开Innodb 的monitor 功能:
mysql> create table
innodb_monitor(a int) engine=innodb;
Query OK, 0 rows affected (0.07
sec)
2. 然后通过使用“SHOW INNODB
STATUS”查看细节信息(由于输出内容太多就不在此记录了);
可能会有读者朋友问为什么要先创建一个叫innodb_monitor
的表呢?因为创建该表实际上就是告诉
Innodb 我们开始要监控他的细节状态了,然后Innodb
就会将比较详细的事务以及锁定信息记录进入
MySQL 的error log 中,以便我们后面做进一步分析使用。
7.4 小结
本章以MySQL Server 中的锁定简介开始,分析了当前MySQL
中使用最为广泛的锁定方式表级锁定和
行级锁定的基本实现机制,并通过MyISAM 和Innodb
这两大典型的存储引擎作为示例存储引擎所使用的表
级锁定和行级锁定做了较为详细的分析和演示。然后,再通过分析两种锁定方式的特性,给出相应的优
化建议和策略。最后了解了一下在MySQL
Server 中如何获得系统当前各种锁定的资源争用状况。希望本
章内容能够对各位读者朋友在理解MySQL 锁定机制方面有一定的帮助。